比LLM更重要的多模态学习
这次想要和大家分享的内容主要包括以下几个方面。首先,我会介绍下多模态学习的基础知识,包括相关概念、应用场景、意义等。然后,我将探讨一些多模态学习中的核心技术以及代表性的模型。最后,我们还会一起看看多模态学习面临的挑战以及未来可能的发展方向。不管你是对人工智能有浓厚兴趣的新手,还是已经在这个领域摸爬滚打了一段时间的老兵,相信你都能从这次分享中找到自己需要的。
多模态学习相关概念介绍
那么,我们先来聊聊什么是多模态学习。模态(Modality)可能是大家比较陌生的词汇,但实际上,在我们日常生活中,经常会接触到不同的模态的数据,例如文字、语音、图片等等。这些都是明显的不同模态的数据。如果我们进一步拓宽视野,会发现模态其实可以理解成一个表达、记录或感知某个事物的方式,或者说这种信息被记录或数据被存储的一种方式。每种不同的存储方式都可以被认为是一种不同的模态。
比如,有的模态可能更接近传感器的原始数据,比如语音、图像等;而有的模态则可能涉及更抽象的概念,比如情绪、物体分类等。在过去,我们可能更倾向于处理单一模态的数据,比如仅处理文字或者仅处理图片。但现在,随着科技的发展,我们不仅需要处理更多的模 ...

大语言模型100K上下文窗口的秘诀
上下文窗口(context window)是指语言模型在进行预测或生成文本时,所考虑的前一个token或文本片段的大小范围。
在语言模型中,上下文窗口对于理解和生成与特定上下文相关的文本至关重要。较大的上下文窗口可以提供更丰富的语义信息、消除歧义、处理上下文依赖性,并帮助模型生成连贯、准确的文本,还能更好地捕捉语言的上下文相关性,使得模型能够根据前文来做出更准确的预测或生成。
最新发布的语言大模型的上下文窗口越来越大。本文详细探讨了大型上下文窗口的技术可能性,尤其分析了将上下文长度增加到100K背后的六大优化技巧。
最近有几个新的语言大模型(LLM)发布,这些模型可以使用非常大的上下文窗口,例如65K 个tokens(MosaicML的MPT-7B-StoryWriter-65k+)和100K个tokens的上下文窗口(Antropic)。在Palm-2技术报告中,谷歌并没有透露具体上下文大小,但表示他们“显著增加了模型的上下文长度”。
相比之下,当前GPT-4模型可以使用32K个输入tokens的上下文长度,而大多数开源LLM的上下文长度为2K个tokens。
如此大的上下文长度意味 ...
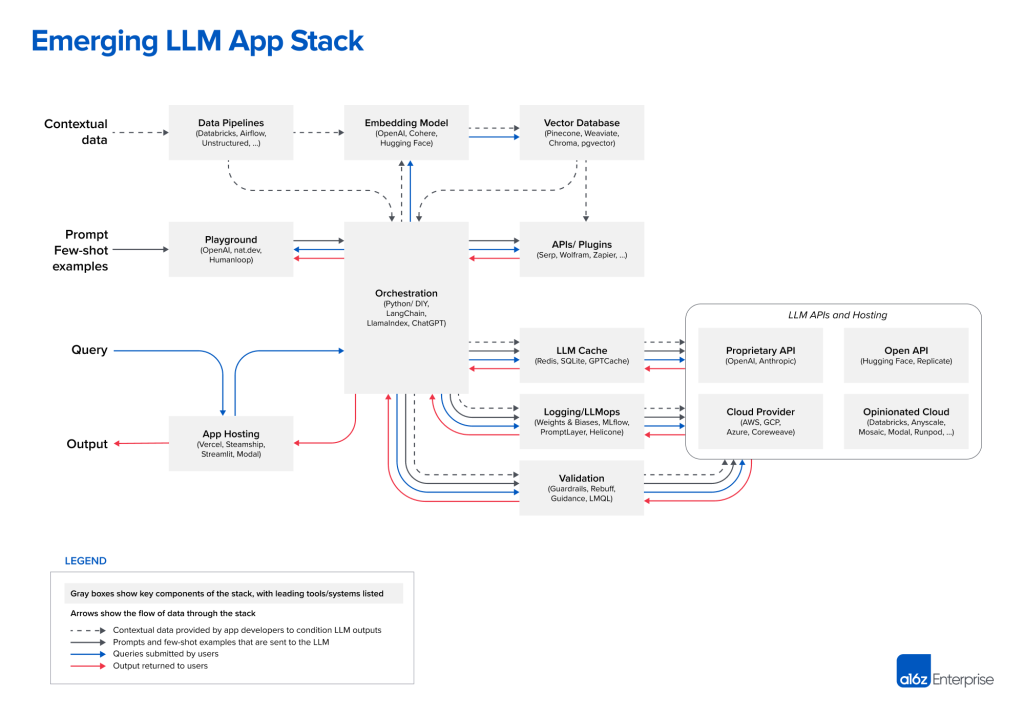
LLM应用开发的架构参考
大型语言模型是构建软件的强大新工具。但由于它们是如此之新,而且行为方式与普通计算资源如此不同,因此如何使用它们并不总是显而易见的。
在这篇文章中,我们将分享新兴 LLM 应用程序栈的参考架构。它展示了我们所见过的人工智能初创公司和尖端科技公司所使用的最常见的系统、工具和设计模式。这个堆栈仍处于早期阶段,可能会随着底层技术的发展而发生重大变化,但我们希望它能为现在使用 LLM 的开发人员提供有用的参考。
1、LLM App技术栈
这是我们当前的 LLM 应用程序栈视图:
以下是每个项目的链接列表,以供快速参考:
Data pipelines
Embedding model
Vector database
Playground
Orchestration
APIs/plugins
LLM cache
Databricks
OpenAI
Pinecone
OpenAI
Langchain
Serp
Redis
Airflow
Cohere
Weaviate
nat.dev
LlamaIndex
Wolfram
SQLite
Unstructured
Hugging F ...

BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP 是一种多模态 Transformer 模型,主要针对以往的视觉语言训练 (Vision-Language Pre-training, VLP) 框架的两个常见问题:
大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。
大多数现有的预训练模型为了提高性能,使用从网络收集的嘈杂图像-文本对扩展数据集。这样虽然提高了性能,但是很明显这个带噪声的监督信号肯定不是最优的。
BLIP 这种新的 VLP 框架可以灵活地在视觉理解任务上和生成任务上面迁移,这是针对第一个问题的贡献。至于第二个问题,BLIP 提出了一种高效率利用噪声网络数据的方法。即先使用嘈杂数据训练一遍 BLIP,再使用 BLIP 的生成功能生成一系列通过预训练的 Captioner 生成一系列的字幕,再把这些生成的字幕通过预训练的 Filter 过滤一遍,得到干净的数据。最后再使用干净的数据训练一遍 BLIP。
论文地址: https://larxiv.org/pdf/2201.12086.pdf
背景
视觉语言训练 (Vision-Language Pre-trainin ...
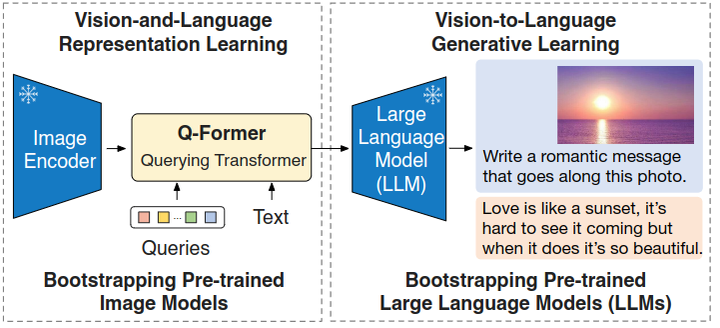
BLIP-2:Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP2是BLIP的续作,是一种多模态 Transformer 模型,主要针对以往的视觉-语言预训练 (Vision-Language Pre-training, VLP) 模型端到端训练导致计算代价过高的问题,在多模态模型中,参数量和计算成本比较高的分别是image encoder和text encoder。
所以,如果能够使用预训练好的视觉模型和语言模型,把参数冻结,能够节约不少的计算代价。
BLIP-2提出了一种借助预训练好的参数的预训练视觉模型和大型语言模型(冻结住参数),高效的视觉语言预训练方法。
但是,简单的冻结预训练好的视觉模型的参数或者语言模型的参数会带来一个问题:就是视觉特征的空间和文本特征的空间,它不容易对齐。那么为了解决这个问题,BLIP-2 提出了一个轻量级的 Querying Transformer,该 Transformer 分两个阶段进行预训练。第一阶段从冻结的视觉编码器中引导多模态学习,第二阶段从冻结的文本编码器中引导多模态学习。
经过这样的流程,BLIP-2 在各种视觉语言任务上实现了最先进的性能,同时需要训练的参数也大大减少。
论文地址: http ...

开源大模型扩充中文词表
当前开源大模型正在如火如荼的进行,随着LLAMA,BLOOM为代表的开源社区逐步完善,如何基于这两个模型更好地使用低成本、高性能的中文场景需求,目前已经出现了多种具有代表性的工作。
不过很现实的问题是,LLaMA词表中仅包含很少的中文字符,其对中文并不友好,BLOOM作为一个多语言模型,词表有过大,在训练过程中并不平民化。
因此,为了解决这个问题,通过干预词表,或通过增加词表,或裁剪词表,并加以预训练这一范式,已经逐步成为一个主流的方式。
因此,为了增强对该范式的认识,本文主要从LLAMA扩充词表以增强中文能力、Bloom裁剪词表以降低训练成本这两个角度进行介绍,充分借鉴了相关开源项目的代码原理一些实验论述,供大家一起参考。
一、LLaMA扩充词表以增强中文能力
《 Efficient and Effective Text Encoding for Chinese Llama and Alpaca》这一文章介绍了在LLaMA上进行中文词表扩充,以增强中文能力的工作。
项目地址:Github
1、LLaMA为什么要扩充词表
为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
这 ...
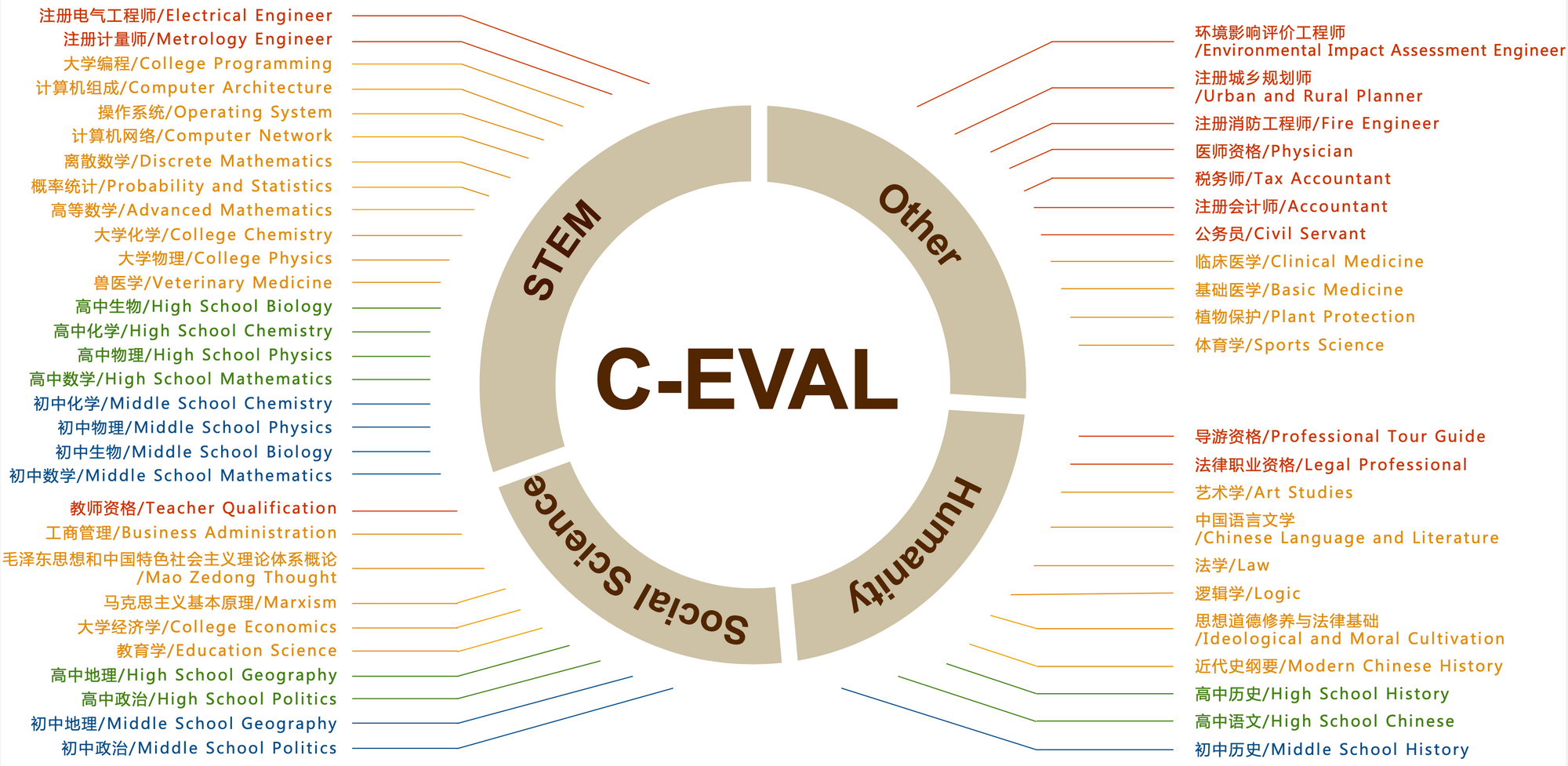
大模型知识&推理评估基准
ChatGPT 的出现,使中文社区意识到与国际领先水平的差距。近期,中文大模型研发如火如荼,但中文评价基准却很少。在 OpenAI GPT 系列 / Google PaLM 系列 / DeepMind Chinchilla 系列 / Anthropic Claude 系列的研发过程中,MMLU / MATH / BBH 这三个数据集发挥了至关重要的作用,因为它们比较全面地覆盖了模型各个维度的能力。
最值得注意的是 MMLU 这个数据集,它考虑了 57 个学科,从人文到社科到理工多个大类的综合知识能力。DeepMind 的 Gopher 和 Chinchilla 这两个模型甚至只看 MMLU 的分数,因此我们想要构造一个中文的,有足够区分度的,多学科的基准榜单,来辅助开发者们研发中文大模型。我们花了大概三个月的时间,构造了一个覆盖人文,社科,理工,其他专业四个大方向,52 个学科(微积分,线代 …),从中学到大学研究生以及职业考试,一共 13948 道题目的中文知识和推理型测试集,我们管它叫 C-Eval,来帮助中文社区研发大模型。
这篇文章是把我们构造 C-Eval 的过程记下来,与开 ...

深度学习调参指南中文版
深度学习调优指南中文版
这不是官方认证的 Google 产品。
Varun Godbole † , George E. Dahl † , Justin Gilmer † , Christopher J. Shallue ‡ , Zachary Nado †
† 谷歌研究,谷歌大脑团队
‡ 哈佛大学
备注:感谢开源大佬提供中文材料
中文版地址
英文版地址

Align before Fuse:Vision and Language Representation Learning with Momentum Distillation
ALBEF 是一种大规模视觉和语言表征学习的方法,可以完成多种视觉-语言的下游任务。现有的很多 Vision-and-Language Pre-training (VLP) 方法使用一个多模态 Transformer 联合建模视觉和文本的 token,但是因为视觉特征和文本特征在输入给 Transformer 时是没对齐的,导致这个多模态 Transformer 准确地学习到图文的关联关系不是很容易。本文提出将视觉和文本的特征在喂入多模态 Transformer 之前,先做对齐,对齐的方法是通过一个对比学习的损失函数。
ALBEF 的另一个优点是也不需要目标检测的框架,同时为了从嘈杂的网络数据中进行高效的学习,ALBEF 作者还提出了一套动量蒸馏的方法辅助 ALBEF 模型的训练。ALBEF 是一种算力上比较亲民的多模态学习的框架。
论文地址: https://arxiv.org/pdf/2107.07651.pdf
背景
视觉-语言预训练 (Vision-and-Language Pre-training, VLP) 旨在从大规模图像-文本对中学习多模态表征,可以改善下游视觉和语言 ...
训个LLM:开源LLM Tokenizer比较
最近在训练LLM,发现不同tokenizer的分词结果和效率都不太一样,因此做实验探究一下,顺便把结果在这里做一个记录。
实验是使用各tokenizer在NewsCommentary的中英平行语料(各25w条)上进行处理,记录处理出的token长度以及处理时间等,结果如下:
名称
词表长度↑
中文平均长度↓
英文平均长度↓
中文处理时间↓
英文处理时间↓
LLaMA
32000
62.8
32.8
02:09
01:37
BELLE
79458
24.3
32.1
00:52
01:27
MOSS
106072
24.8
28.3
07:08
00:49
GPT4
50281
49.9
27.1
00:07
00:08
BLOOM/Z
250680
23.4
27.6
00:46
01:00
ChatGLM
130344
23.6
28.7
00:26
00:39
实验结果
LLaMA的词表长度是最短的,其在中英文的平均长度上效果都不佳,同时处理时间也较长。
BELLE的词表是在LLaMA基础上进行扩增的,通过观察可以发现,扩增的主要是中文的t ...