本文介绍神经网络训练中的周期性学习率技术。
Introduction
学习率(learning_rate, LR)是神经网络训练过程中最重要的超参数之一,它对于快速、高效地训练神经网络至关重要。简单来说,LR决定了我们当前的权重参数朝着降低损失的方向上改变多少。
1 | new_weight = exsiting_weight - learning_rate * gradient |
本文介绍了一种叫做周期性学习率(CLR)的技术,它是一种非常新的、简单的想法,用来设置和控制训练过程中LR的大小。该技术在jeremyphoward今年的fast.ai course课程中提及过。
Motivation
神经网络用来完成某项任务需要对大量参数进行训练。参数训练意味着寻找合适的一些参数,使得在每个batch训练完成后损失(loss)达到最小。
通常来说,有两种广泛使用的方法用来设置训练过程中的LR。
One LR for all parameters
一个典型的例子是SGD, 在训练开始时设置一个LR常量,并且设定一个LR衰减策略(如step,exponential等)。这个单一的LR用来更新所有的参数。在每个epochs中,LR按预先设定随时间逐渐衰减,当我们临近最小损失时, 通过衰减可以减缓更新,以防止我们越过最小值。
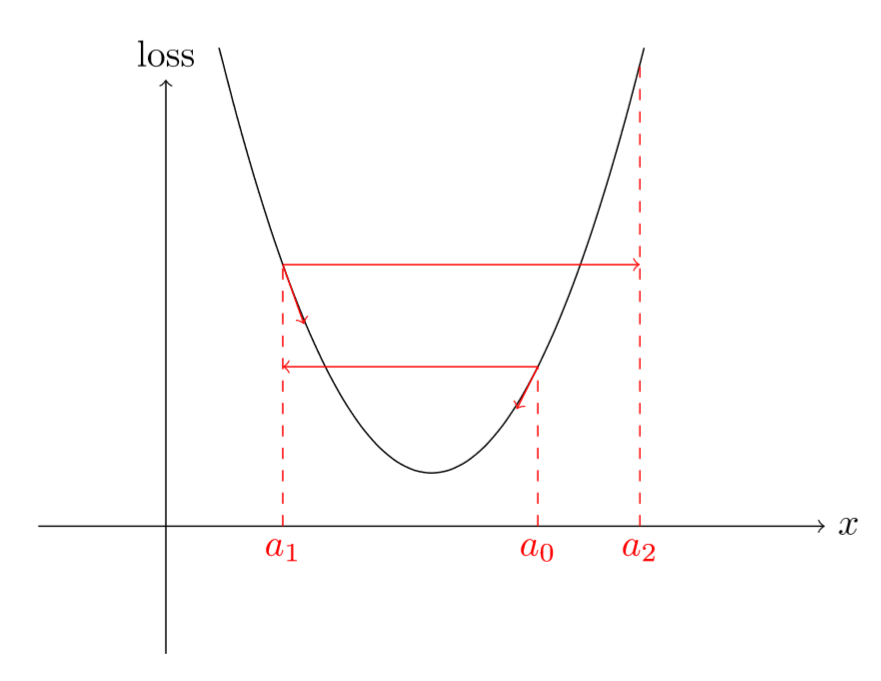
- 难以选择初始的LR达到想要的效果(如上图所示);
- LR衰减策略同样难以设定,他们很难自适应动态变化的数据;
- 所有的参数使用相同的LR进行更新,而这些参数可能学习速率不完全相同;
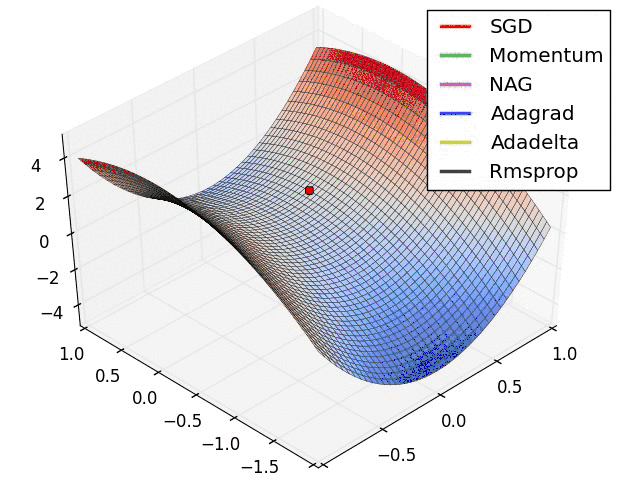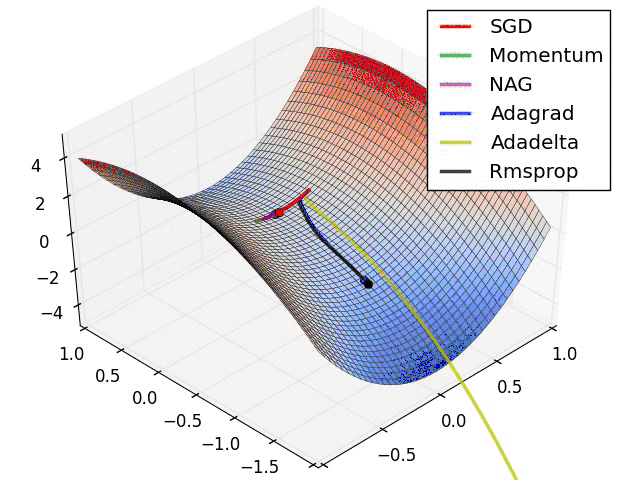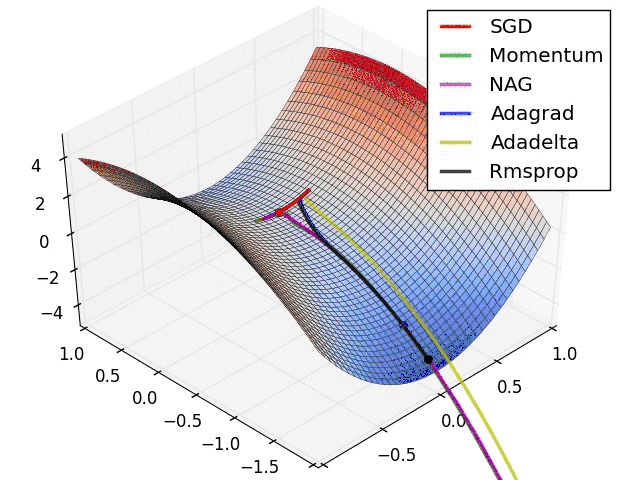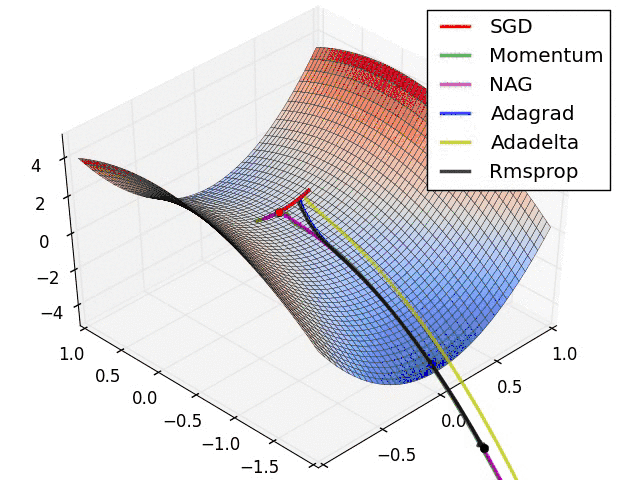
- 很容易陷入鞍点不能自拔(下面会阐述)
Adaptive LR for each parameter
一些改进的优化器如AdaGrad, AdaDelta, RMSprop and Adam 很大程度上缓解了上述困难,主要是对每个参数采用不同的自适应学习率。比如AdaDelta,它的更新机制甚至不需要我们主动设置默认的学习率。
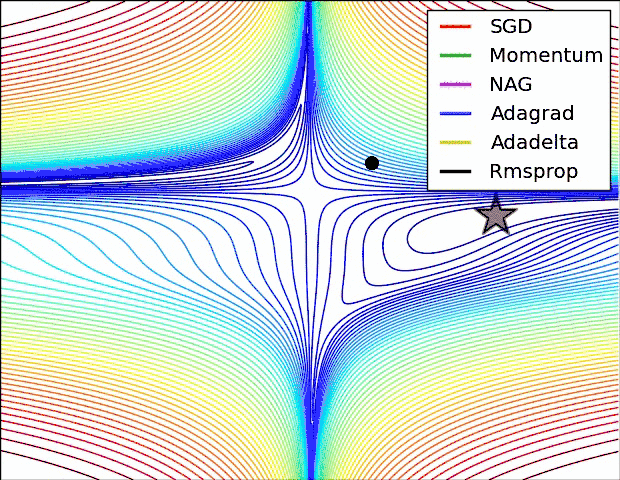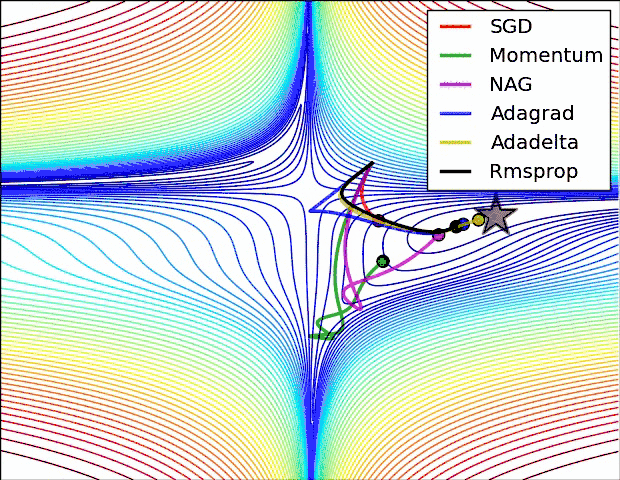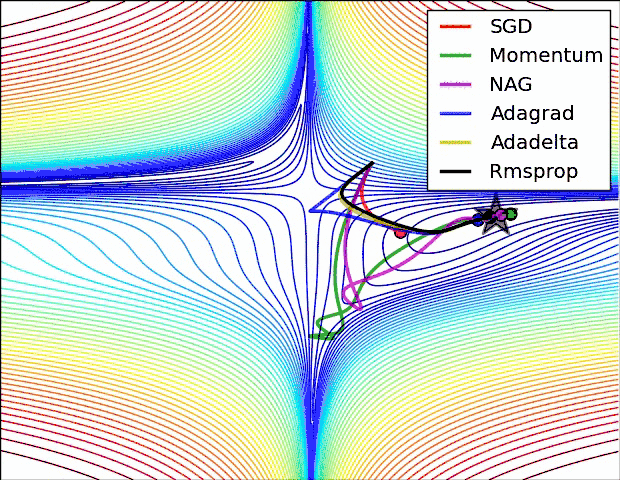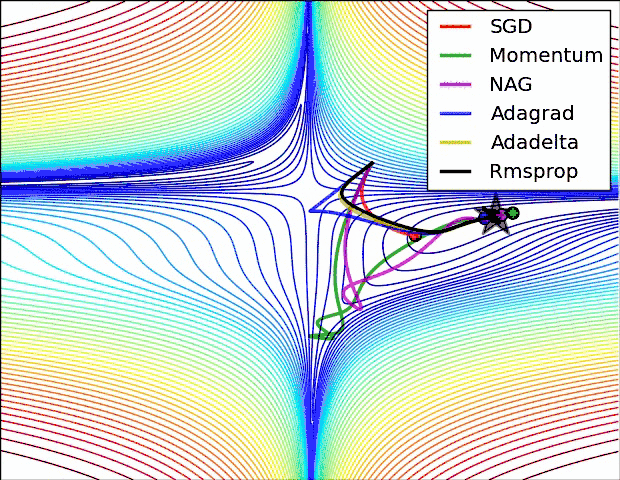
CLR是Leslie Smith于2015年提出的。这是一种调节LR的方法,在该方法中,设定一个LR上限和下限,LR的值在上限和下限的区间里周期性地变化。看上去,CLR似乎是自适应LR技术和SGD的竞争者,事实上,CLR技术是可以和上述提到的改进的优化器一起使用来进行参数更新的。
而在计算上,CLR比上述提到的改进的优化器更容易实现,正如文献[1]所述:
Adaptive learning rates are fundamentally different from CLR policies, and CLR can be combined with adaptive learning rates, as shown in Section 4.1. In addition, CLR policies are computationally simpler than adaptive learning rates. CLR is likely most similar to the SGDR method that appeared recently.
Why it works
直觉上看,随着训练次数的增加我们应该保持学习率一直减小以便于在某一时刻达到收敛。
然而,事实恰与直觉相反,使用一个在给定区间里周期性变化的LR可能更有用处。原因是周期性高的学习率能够使模型跳出在训练过程中遇到的局部最低点和鞍点。事实上,Dauphin等[3]指出相比于局部最低点,鞍点更加阻碍收敛。如果鞍点正好发生在一个巧妙的平衡点,小的学习率通常不能产生足够大的梯度变化使其跳过该点(即使跳过,也需要花费很长时间)。这正是周期性高学习率的作用所在,它能够更快地跳过鞍点。
Epoch,iterations, cycles and stepsize
首先介绍几个术语,理解这些术语可以更好地理解下面描述的算法和公式。
我们现在考虑一个包含50000个样本的训练集。
一个epoch是至将整个训练集训练一轮。如果我们令batch_size等于100(每次使用100个样本进行训练), 那么一个epoch总共需要计算500次iteration。iteration的数目随着epoch的增加不断积累,在第二个epoch,对应着501到1000次iteration,后面的以此类推。
一个cycle定义为学习率从低到高,然后从高到低走一轮所用的iteration数。而stepsize指的是cycle迭代步数的一半。注意,cycle不一定必须和epoch相同,但实践上通常将cycle和epoch对应相同的iteration。

Calculating the LR
综上所述,接下来我们需要参数作为该算法的输入:
-
stepsize
-
base_lr
-
max_lr
下面是LR更新的一段代码。
1 | import numpy as np |
结果如下图所示。
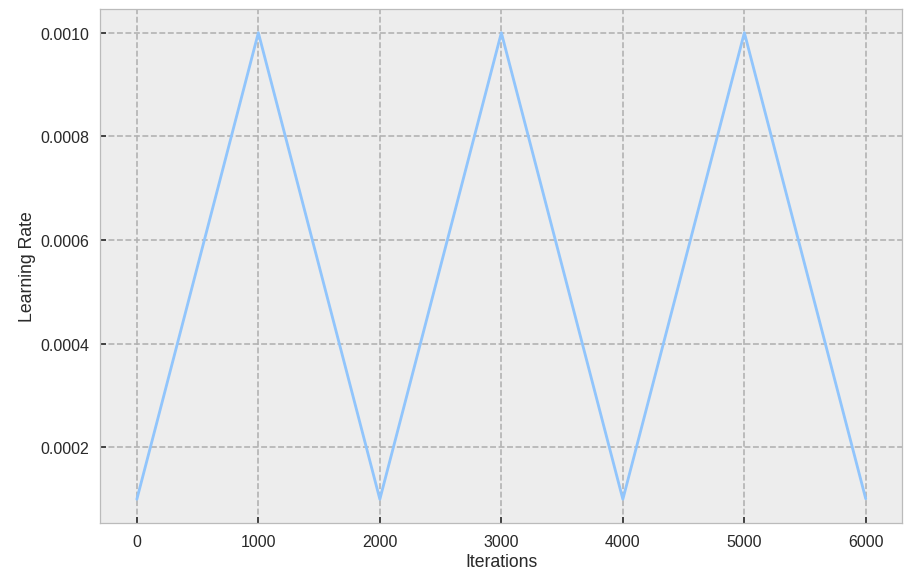
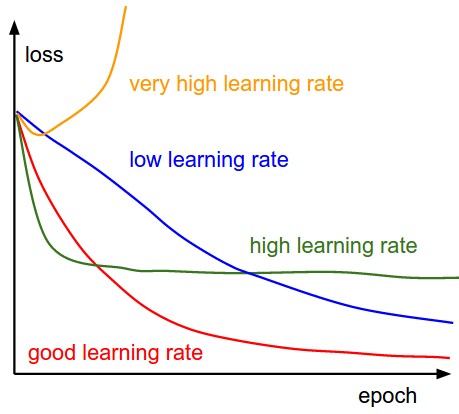
对于给定的数据集,怎么确定合理的base lr 和max lr呢?
我们通过这篇文章来学习,即fast.ai模块中lr_find功能,简述如下:
在开始训练模型的同时,从低到高地设置学习率,知道奥损失(loss)变得失控为止,然后将损失和学习率画在一张图中,在损失持续下降。即将达到最小值前的范围上取一个值作为学习率。比如下图:可以在10^-2到3x10^-2之间任意取一个值。
这里的思想和Leslie是一致的,他在论文中提出了一个很好的训练方法。
Leslie建议,用两个等长的步骤组成一个cycle:从很小的学习率开始,慢慢增大学习率,然后再慢慢降低回到最小值。最大学习率应该根据Learning Rate Finder来确定,最小值则可以取最大值的十分之一。这个cycle的长度应该比总的epoch次数越小,在训练的最后阶段,可以将学习率降低到最小值以下几个数量级。
答案是先跑几个epoch,并且让学习率线性增加,观察准确率的变化,从中选出合适的base 和max lr。
我们让学习率按照上面的斜率进行增长,跑了几轮,结果如下图所示。
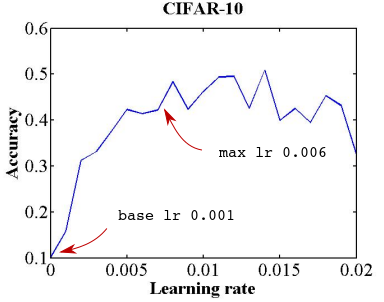
好了,三个参数中已经有两个确定了,那么怎么确定stepsize呢?
已经有论文做过实验,他们将stepsize设成一个epoch包含的iteration数量的2-10倍。拿我们之前举的例子来说,我们一个epoch包含500个iteration,那么stepsize就设成1000-5000。该论文实验表明,stepsize设成2倍或者10倍,两者结果并没有太大的不同。
Variants
上面我们实现的算法中,学习率是按照三角的规律周期性变化。除了这种以外,还有其他集中不同的函数形式。
***traiangular2:***这里max lr 按cycle进行对半衰减。
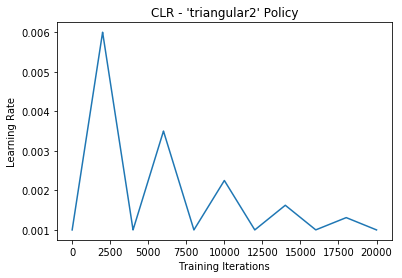
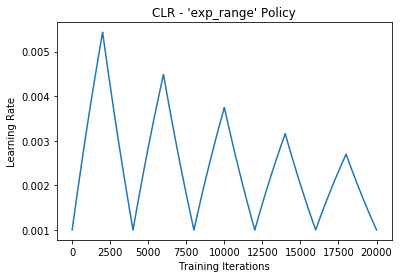
Results
如下图所示,在某神经网络上,CLR提供了一个快速的收敛,因此它的确值得一试。
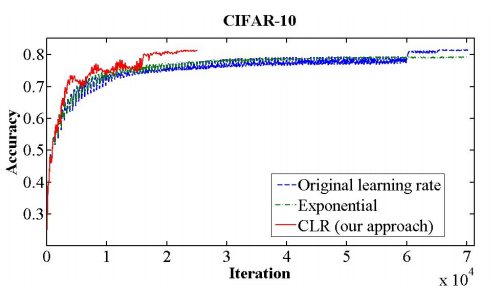
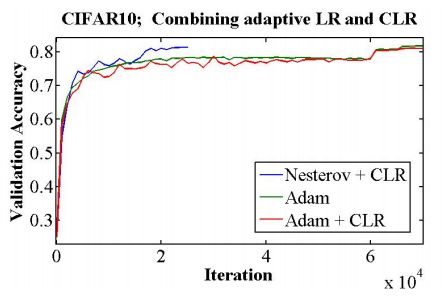
Conclusion
CLR带来了一种新的方案来控制学习率的更新,它可以与SGD以及一些更加高级的优化器上一起使用。CLR应该成为每一个深度学习实践者工具箱里的一项技术。
References
- Cyclical Learning Rates for Training Neural Networks, Smith
- An overview of gradient descent optimization algorithms, Rudder
- Y. N. Dauphin, H. de Vries, J. Chung, and Y. Bengio. Rmsprop and equilibrated adaptive learning rates for non-convex optimization.
- SGDR: Stochastic Gradient Descent with Warm Restarts, Loshchilov, Hutter
- https://github.com/bckenstler/CLR