在上一章中,我们讨论了GoogLeNet网络结构和Inception模块,这节中,我们将讨论由一个新的微结构模块组成的网络结构,即由residual微结构组成的网络结构——ResNet。
ResNet网络由residual模块串联而成,在原论文中,我们发现作者训练的ResNet网络深度达到了先前认为不可能的深度。在2014年,我们认为VGG16和VGG19网络结构已经非常深了。然而,通过ResNet网络结构,我们发现可以成功在ImageNet数据集上训练超过100层的网络和在CIFAR-10数据集上训练超过1000层的网络。
从论文《Identity Mappings in Deep Residual Networks》 中,可知只有使用更高级的权值初始化算法(如Xavier等)以及identity mapping(恒等映射)才能实现这些深度,我们将在本章后面讨论相关内容。我们知道CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。非常深的ResNet网络在ILSVRC 2015年所有三项挑战(分类、检测和定位)中获得了第一名。
在本文中,首先,我们将讨论ResNet网络结构、residual模块,以及residual模块的扩展。之后,我们将在CIFAR-10数据集和tiny imagenet数据集上训练ResNet网络结构。
ResNet网络和residual模块
He等人在2015年的论文《Deep Residual Learning for Image Recognition》提出了ResNet网络结构,并证明了使用标准的SGD优化算法和合理的初始化函数可以训练非常深的网络。从论文中,我们可以看到ResNet网络深度可以达到50-100层以上(甚至1000层),主要依赖于residual模块。
另外,从论文中,可以发现ResNet网络结构很少使用pooling层,这跟以往我们搭建的卷积神经网络不同。ResNet网络并不完全依赖于max pooling层来降低feature map的大小。相反,使用步长大于1的卷积来降低输出的feature map大小。事实上,在搭建网络结构时,只有两种情况可能会使用pooling层:
为了降低feature map大小,在搭建网络主体部分使用max pooling。
像GoogLeNet一样,用average pooling层代替全连接层。
严格地说,ResNet网络只有一个max pooling层——所有降维效果都是由卷积层完成。
我们将回顾原始的residual模块,以及用于训练更深层次网络的bottleneck residual模块。接着,我们将讨论He等人在2016年发表的《Identity Mappings in Deep Residual Networks》论文中对原始residual模块的扩展,从而进一步提高分类准确率。最后,我们将基于Keras框架从头到尾实现ResNet网络结构,并在CIFAR-10数据集和tiny imagenet数据集上进行训练。
residual 和 Bottlenecks residual
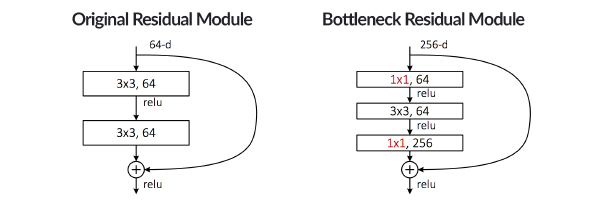
He等人在2015年提出的residual模块依赖于identity mappings。如图12.1(左)所示,residual模块主要有两个分支:
右边分支(“弯弯的部分”)输出的是原始输入
左边分支输出的是对原始输入经过一系列卷积变换
最后将两分支输出进行相加得到整个residual模块的输出。从图12.1可以看到residual模块只有两个分支,而我们上节提到的GoogLeNet的Inception模块有四个分支。所以,相对而言,residual模块非常简单。
图12.1 左:原始的residual模块 右:bottleneck residual模块
从图12.1(左),可知He等人将原始输入直接与经过CONV、RELU和BN层计算的输出相加,我们称这个加法为identity mapping(标识映射)。**注意**,我们并不是像前面几章所做的那样,沿着通道维度连接,而是我们将两个分支的输出按照1+1=2的加法模式。
传统的神经网络层可以看作是学习一个函数y = f(x),而residual模块可以看做是学习一个函数y=f(x)+id(x)=f(x)+x,其中id(x)是恒等映射函数。我们考虑y作为residual模块要拟合的基础映射,x表示residual模块的输入,假设多个非线性层可以渐进地近似复杂函数,它等价于假设它们可以渐进地近似残差函数,即f(x) = y-x(假设输入输出是相同的维度)。因此,我们明确让这些层近似参数函数f(x) = y-x,而不是期望堆叠层近似y(图12.1左图的左分支)。因此原始函数变成了f(x)+x。尽管两种形式应该都能渐进地近似要求的函数(假设),但学习的难易程度可能是不同的。
此外,由于每个residual模块都包含输入,所以学习率越大,网络训练越快(一般来说,学习率越大,神经网络学习速度越快,如果学习率太小,网络很可能会陷入局部最优,但是如果太大,超过了极值,损失就会停止下降,在某一位置反复震荡)。一般训练ResNet网络的初始学习率为1e-1,但是对于大多数网络结构,比如AlexNet或VGGNet,这么高的学习率,网络几乎不可能会收敛。由于ResNet网络的resident模块包含identity mapping,所以高学习率是可行的。
此外,He等人也对原始residual模块进行了扩展——bottleneck(如图12.1右),从图12.1右,我们可以发现右分支的identity mapping没有发生变化,而左分支的conv层进行了更新:
使用三个CONV层,而不是两个。
第一层和最后一层是1x1卷积。
前两个CONV层的filter的数量等于最后一个CONV层的filter的数量的1/4。
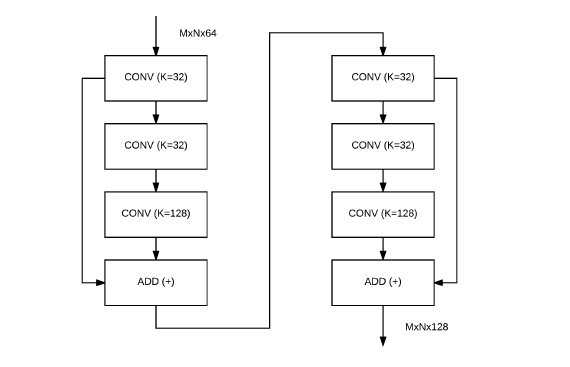
bottleneck的结构如图12.2所示,这里我们列了两个residual模块,其中一个residual模块输出直接输入到下一个residual模块。
图12.2 bottleneck案例
第一个residual模块接收大小为MxNx64的feature map(这个示例的宽度和高度是任意的),且三个CONV层的filter个数分别为32、32和128。最后residual模块输出的feature map大小为MxNx128,然后将其传递到第二个residual模块中。
在第二个residual模块中,三个CONV层的filter个数分别为32、32和128。需要注意的是 32 < 128,意味着通过1x1和3x3CONV层,我们降低了feature map的大小。
最后一个1x1CONV层的filter个数是前两个CONV层的filter个数的4倍,从而再次增加了feature map的个数,这就是为什么我们把对residual模块的改进称为“bottleneck”——其意思就是输入输出维度差距较大,就像一个瓶颈一样,上窄下宽亦或上宽下窄。在构建自定义residual模块时,通常会提供一些伪代码,比如residual_module(K=128),这意味着residual模块中最后一个CONV层的filter个数为128个,从而可以推导出前两个conv层的filter个数为128/4 = 32个。这种表示法通常更容易使用。
在构建ResNet网络代码之前,我们再来认识下identity mapping。
identity mapping
ResNet网络中提出的Residual block之所以成功,原因有两点:
第一,是它的shortcut connection增加了它的信息流动,
第二,就是它认为对于一个堆叠的非线性层,那么它最优的情况就是让它成为一个恒等映射,但是shortcut connection的存在恰好使得它能够更加容易的变成一个identity mapping。
比如:
下面那行的网络其实就是在上面那行网络的基础上新叠加了一层,而新叠加上那层的权重weight ,如果能够学习成为一个恒等的矩阵I ,那么其实上下两个网络是等价的,那么也就是说如果继续堆叠的层如果能够学到一个恒等矩阵,那么经过堆叠的网络是不会比原始网络的性能差的,也就是说,如果能够很容易的学到一个恒等映射,那么更深层的网络也就更容易产生更好的性能。这是ResNet所提出的根源,也是本文所强调的重点。
对于一个网络中的一个卷积层f(x,W) ,W 是卷积层的权重,如果要使得这个卷积层是一个恒等映射,即f(x,W)=x ,那么W 就应该是一个恒等映射I ,但是当模型的网络变深时,要使得W =I 就不那么容易。对于ResNet的每一个Residual Block,要使得它为一个恒等映射,即f(x,W)+x=x ,就只要使得W =0即可,而学习一个全0的矩阵比学习一个恒等矩阵要容易的多,这就是ResNet在层数达到几百上千层时,依然不存在优化难题的原因。
Residual模块的扩展
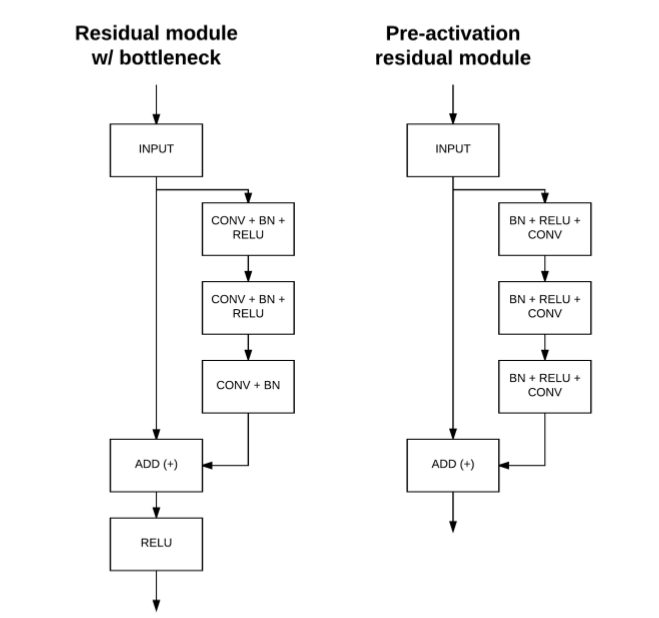
2016年,He等人发表了第二篇关于residual模块的论文《Identity Mappings in Deep Residual Networks》。该论文从多个角度详细介绍了residual模块内部的卷积、激活和BN层的位置排序问题,包括从理论和实践角度。首先,我们来看看bottleneck residual模块,如图12.3(左)所示:
图12.3 左: bottleneck residual 右:pre-activation residual
原bottleneck residual模块对输入层做两个分支,由图12.3(左)可知,右边分支对输入层应用一系列(CONV = > BN = > ReLU)x2 = > CONV = > BN变换,左分支直接输出输入,然后将两输出进行相加并添加RELU激活。然而,在He等2016年的研究中,发现有一种更优的层序能够获得更高的精度——这种方法被称为预激活(pre-activation)。
在pre-activation版本的residual模块中,如图12.3(右)所示,我们去掉模块底部的ReLU激活层,并且把residual mapping中的BN层和RELU激活层放在了CONV层之前,从图12.3左右对比,很明显看到这一变换。
因此,我们不再从CONV层开始,而是应用一系列(BN => RELU => CONV) x 3。residual模块的输出是两个分支的输出进行加法得到,它随后被输入到网络中的下一个residual模块中(因为residual模块是叠加在一起的)。
作者将ReLU和BN看做是权重层的”pre-activation”,基于这个观点,作者设计了如图12.3(右)所示的新的residual模块,相比原始的residual模块,新结构更加易于训练且取得了更好的训练结果。
实现 ResNet
上面,我们讨论了ResNet网络结构相关内容,接下来,我们将基于Keras框架实现ResNet网络。注意,我们将实现最新版本的residual模块,包括bottlenecks和pre-activations。在pyimagesearch项目中的nn.conv子目录中创建一个resnet.py (若存在,则进行更新),整体项目目录结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 --- pyimagesearch | |--- __init__.py | |--- callbacks | |--- io | |--- nn | | |--- __init__.py | | |--- conv | | | |--- __init__.py | | | |--- alexnet.py | | | |--- deepergooglenet.py | | | |--- lenet.py | | | |--- minigooglenet.py | | | |--- minivggnet.py | | | |--- fcheadnet.py | | | |--- resnet.py | | | |--- shallownet.py | |--- preprocessing | |--- utils
打开resnet.py ,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from keras.layers import BatchNormalizationfrom keras.layers import Conv2Dfrom keras.layers import AveragePooling2Dfrom keras.layers import MaxPooling2Dfrom keras.layers import ZeroPadding2Dfrom keras.layers import Activationfrom keras.layers import Densefrom keras.layers import Flattenfrom keras.layers import Inputfrom keras.models import Modelfrom keras.layers import addfrom keras.regularizers import l2from keras import backend as K
其中,add函数主要是将residual模块的两个分支输出相加,l2函数是正则项,在训练非常深的网络时,正则化非常重要,因为网络越深,越容易发生过拟合问题。
接下来,构建residual_module:
1 2 3 class ResNet : @staticmethod def residual_module (data,K,stride,chanDim,red = False ,reg = 0.0001 ,bnEps=2e-5 ,bnMom=0.9 ):
注意 :我们基于keras框架实现的ResNet网络将类似于He的caffe版本和wei wu的mxnet版本,因此,参数具体的取值主要与两个版本保持一致。
其中:
data: residual模块的输入,也就是上一层的输出
K:filter的个数,注意 : K值是对应bottleneck中最后一个conv层的filters个数,前面两个conv层的filters个数为K/4,主要参考He的设置。
stride:步长,我们将设置这个参数来达到降低feature map大小的效果,而不是使用max pooling。
chanDim:通道位置
red:(reduce的缩写),bool类型,是否降低feature map的大小,这里主要是表明不是所有的residual模块都进行降维。
reg:正则化系数,这里会对所有的conv层使用l2正则。
bnEps:bn参数,主要预防标准化时,分母为0,在keras模块中,默认值为0.001,这里我们将默认设置为2e-5,主要降低该值得影响。
bnMom:bn参数,动态均值的动量。在keras中默认值为0.99,而he和wei wu版本中都设置为0.9.
接下来,定义residual模块的主体:
1 2 3 4 5 6 7 8 shortcut = data bn1 = BatchNormalization(axis = chanDim,epsilon=bnEps,momentum = bnMom)(data) act1 = Activation('relu' )(bn1) conv1 = Conv2D(int (K*0.25 ),(1 ,1 ),use_bias = False ,kernel_regularizer=l2(reg))(act1)
shortcut对应residual模块中的identity mapping,之后,我们会将shortcut与residual mapping输出相加。
residual mapping的第一个pre-activation由BN、relu和conv组成,先BN层,然后是RELU激活层,最后是1x1conv层,需要注意的是 ,1x1卷积层的filters个数为K/4,且use_bais=False表明在conv层中不使用偏置项,根据He的研究,BN层的作用相当于bias,若conv层后紧接着bn层,则conv层中可以不使用bias。
构建residual mapping中的第二个block:
1 2 3 4 5 bn2 = BatchNormalization(axis = chanDim,epsilon=bnEps,momentum=bnMom)(conv1) act2 = Activation('relu' )(bn2) conv2 = Conv2D(int (K*0.25 ),(3 ,3 ),strides = stride,padding='same' ,use_bias=False ,kernel_regularizer=l2(reg))(act2)
其中,filters同样为K/4,而大小变成了3x3.
构建residual mapping中的最后一个block:
1 2 3 4 bn3 = BatchNormalization(axis = chanDim,epsilon=bnEps,momentum=bnMom)(conv2) act3 = Activation('relu' )(bn3) conv3 = Conv2D(K,(1 ,1 ),use_bias=False ,kernel_regularizer=l2(reg))(act3)
稍微注意下,最后一个block的conv层的filters个数为K,大小为1x1.
是否需要降低feature map的大小:
1 2 3 4 if red: shortcut = Conv2D(K,(1 ,1 ),strides=stride,use_bias=False ,kernel_regularizer=l2(reg))(act1)
如果我们需要减小feature map的个数,则我们可以对shortcut使用步长大于1的conv层。
将residual mapping中conv3的输出与shortcut相加,作为residual_module的输出:
1 2 3 x = add([conv3,shortcut]) return x
接下来,我们将使用residual_module搭建整个resnet网络结构:
1 2 @staticmethod def build (width,height,depth,classes,stage,filters,reg = 0.0001 ,bnEps=2e-5 ,bnMom=0.9 ,dataset='cifar' ):
其中:
width:输入图像的宽度
height:输入图像的高度
depth:通道数,即深度
classes:类别个数
stage:list形式,列表中的每一值代表我们需要堆叠的residual模块的个数(每一个residual模块的filters个数相同)
filters:list形式,列表中的每一个值代表conv层中filter的个数,注意 :第一个值为第一个conv层的filter个数。
reg:l2正则化系数,默认值为0.0001
bnEps:BN参数,防止标准化时分母为0,默认值为2e-5
bnMom:动态均值的动量,默认值为0.9
dataset:训练数据的类型,默认是在cifar数据集上训练
需要注意的是 :stage和filters值的形式,两者都是list形式,比如假设stage =[3,4,6]和filters=[64,128,256,512]——注意stage和filters值的个数,stage列表与filters列表后三个值是一一对应。filters列表中第一个数值表示单独conv层的filter个数,而不是residual模块中conv层的filter个数,因此第一个filter值为64表明,ResNet网络的第一个conv层的filter个数为64。然后,我们把三个residual模块堆叠在一起——每个residual模块的filters参数K=128,降低了feature map的大小。接着,我们把四个residual模块叠加在一起——每个residual模块的参数K = 256,经过四个residual模块之后,我们再一次降低了feature map的大小。最后,我们把六个residual模块堆叠在一起——每个residual模块的参数K = 512。
使用列表来存储stage和filters数值,这样方便我们构建更深的网络,而不会增加代码量。
接下来,定义input的shape:
1 2 3 4 5 6 inputShape = (height,width,depth) chanDim = -1 if K.image_data_format() == "channels_first" : inputShape = (depth,height,width) chanDim = 1
ResNet网络的input层:
1 2 3 4 5 6 7 8 # 输入层 inputs = Input(shape=inputShape) # 对输入进行BN x = BatchNormalization(axis = chanDim,epsilon = bnEps,momentum = bnMom)(inputs) # 使用数据类型 if dataset == 'cifar': # 卷积层 x = Conv2D(filters[0],(3,3),use_bias = False,padding='same',kernel_regularizer = l2(reg))(x)
ResNet的第一层为BN层,这与我们之前看到的网络结构有点不同(之前网络的第一层一般都是CONV层)。以往我们构建网络结构时,需要对输入数据进行标准化,一般的做法是减去均值,作者在这里再加了一层BN层,主要是为了数据更加标准。事实上,直接对输入数据进行BN运算有时可以不用对输入数据进行零均值处理。
BN层之后,紧接着是一个CONV层,filter的个数为filters列表的第一个值(注 :所有的conv层的参数都在filters列表中),大小为3x3。需要注意的是,该conv层是针对cifar-10数据集,之后,我们会在tiny imagenet数据集上也训练ResNet网络,即dataset=‘tiny_imagenet’,而对于tiny imagenet数据集,由于tiny imagenet数据的图片shape比较大,因此在堆叠residual模块之前,我们会对输入数据进行一系列的卷积、bn和max pooling等操作。
接下来,我们开始堆叠residual模块:
1 2 3 4 5 6 7 8 9 for i in range (0 ,len (stage)): stride = (1 ,1 ) if i==0 else (2 ,2 ) x = ResNet.residual_module(x,filters[i+1 ],stride,chanDim,red=True ,bnEps = bnEps,bnMom=bnMom) for j in range (0 ,stage[i] -1 ): x = ResNet.residual_module(x,filters[i+1 ],(1 ,1 ),chanDim,bnEps=bnEps,bnMom=bnMom)
注意 :stage列表每一个数值表示多少个residual模块堆叠在一起。从整个网络结构中,我们可知ResNet网络尽可能地减少pooling层的使用,而依靠conv层来降低feature map的大小。
若不依赖pooling层减小feature map大小,则我们必须设置conv的步长,但是,在第一个stage的所有residual模块的conv层的步长为1,表明不进行下采样处理,而之后的stage的所有conv层的步长为2,此时可以达到减小feature map大小的作用。
经过一系列的residual模块之后,特征图像的大小减少到8x8xclases,类似于GoogLeNet网络,为了避免使用全连接层,我们将使用average pooling层将特征图像的大小缩小到1x1xclasses:
1 2 3 4 x = BatchNormalization(axis=chanDim,epsilon = bnEps,momentum = bnMom)(x) x =Activation('relu' )(x) x = AveragePooling2D((8 ,8 ))(x)
最后,构建softmax层返回预测概率:
1 2 3 4 5 6 7 x = Flatten()(x) x = Dense(classes,kernel_regularizer=l2(reg))(x) x = Activation('softmax' )(x) model = Model(inputs,x,name='resnet' ) return model
以上,我们搭建好了ResNet网络结构,接下来我们将在CIFAR-10数据集和tiny imagenet数据集上进行训练。
ResNet on CIFAR-10
首先,我们将在CIFAR-10数据集上训练ResNet网络结构,并且我们将复现he的实验结果。
CIFAR-10数据:ctrl + c 方法
当我们一开始训练一个不太熟悉的网络结构或者一个未使用过的数据集时,一般使用ctrl+c的方法进行训练网络。我们可以根据训练过程结果对学习率进行调整,当我们完全不确定一个网络结构或者数据集需要训练多长时间才能获得合理的精度时,这个方法尤其有用。
从之前的CIFAR-10数据实验中,我们觉得对cifar-10数据集训练网络大概需要迭代60-100次左右。对于ResNet网络是需要更多还是更少?,一开始我们也无法确定,但是至少可以先从之前的实验经验获得一个大概的次数,然后根据实验结果,在决定是多还是少。因此,我们将根据之前的cifar-10数据实验中,确定超参数的变化范围。
首先,新建一个名为resnet_cifar10.py文件,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import matplotlibmatplotlib.use("Agg" ) from sklearn.preprocessing import LabelBinarizerfrom pyimagesearch.nn.conv import resnetfrom pyimagesearch.callbacks import epochcheckpoint as EPOfrom pyimagesearch.callbacks import trainingmonitor as TMfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.datasets import cifar10from keras.optimizers import SGDfrom keras.models import load_modelimport keras.backend as Kimport numpy as npimport argparse
其中,我们加载了EpochCheckpoint类,以便在训练过程中将ResNet权值序列化到磁盘,从而可以从特定的checkpoint停止并重新开始训练,第一个实验中,我们将使用SGD进行训练。
解析命令行参数:
1 2 3 4 5 6 ap = argparse.ArgumentParser() ap.add_argument('-c' ,'--checkpoints' ,required=True ,help ='path to output checkpoint directory' ) ap.add_argument('-m' ,'--model' ,type =str ,help ='path to *specific* model checkpoint to load' ) ap.add_argument('-s' ,'--start_epoch' ,type =int ,default =0 ,help ='epoch to restart training as ' ) args = vars (ap.parse_args())
其中:
checkpoints:保存checkpoint模型路径
model:模型保存路径
start_epoch:重新开始训练checkpoint模型
加载cifar-10数据集——已经划分好了train和test,并进行零均值预处理和标签编码化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 print ('[INFO] loading CIFAR-10 data...' )((trainX,trainY),(testX,testY)) = cifar10.load_data() trainX = trainX.astype("float" ) testX = testX.astype("float" ) mean = np.mean(trainX,axis =0 ) trainX -= mean testX -= mean lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.fit_transform(testY)
与之前的实验一样,为了提高精度和防止过拟合,我们对train数据进行数据增强处理:
1 2 3 4 5 aug = ImageDataGenerator(width_shift_range = 0.1 , height_shift_range = 0.1 , horizontal_flip = True , fill_mode='nearest' )
如果我们第一次训练网络,则需要初始化网络结构:
1 2 3 4 5 6 7 if args['model' ] is None : print ("[INFO] compiling model..." ) opt = SGD(lr=1e-1 ) model = resnet.ResNet.build(32 ,32 ,3 ,10 ,(9 ,9 ,9 ),(64 ,64 ,128 ,256 ),reg=0.0005 ) model.compile (loss='categorical_crossentropy' ,optimizer=opt,metrics = ['accuracy' ])
可能你会注意到SGD的学习率为0.1,比之前的任何实验的学习率都要高,这是由于在residual模块中存在identity mapping,使得我们可以使用大学习率。但是这个大学习率并不适合像VGG或AlexNet的网络结构。
在初始化ResNet模型时,输入图像的大小为32x32x3,cifar-10有10种不同类别,因此classes=10,需要特别注意的是 stage和filters列表。stage=(9,9,9),也就是说我们将学习三个阶段,每个阶段由9个residual模块堆叠而成。在每一个阶段中,我们使用特定的residual模块来降低feature map的大小。
filters=(64、64、128、256)是CONV层的filter个数。第一个CONV层(在residual模块之前)由K = 64个filter组成。而64、128和256分别对应于每个stage中conv层的filter个数,即前9个residual模块的参数K = 64。第二组的9个residual模块的参数K = 128,最后一组的9个residual模块的参数K = 256。
如果,给定checkpoint,我们将从特定的模型开始训练,并更新学习率:
1 2 3 4 5 6 7 8 9 else : print ("[INFO] loading {}..." .format (args['model' ])) model = load_model(args['model' ]) print ("[INFO] old learning rate: {}" .format (K.get_value(model.optimizer.lr))) K.set_value(model.optimizer.lr,1e-5 ) print ("[INFO] new learning rate: {}" .format (K.get_value(model.optimizer.lr)))
回调函数列表:
(1)检每5次epoch,保存一次当前ResNet模型
(2)监控整个训练过程:
1 2 3 4 5 6 7 8 9 callbacks = [ EPO.EpochCheckpoint(args['checkpoints' ],every = 5 ,startAt = args['start_epoch' ]), TM.TrainingMonitor("output/resnet56_cifar10.png" , jsonPath="output/resnet56_cifar10.json" , startAt = args['start_epoch' ]) ]
训练网络
1 2 3 4 5 6 7 8 9 10 print ("[INFO] training network....." )model.fit_generator( aug.flow(trainX,trainY,batch_size=128 ), validation_data = (testX,testY), steps_per_epoch = len (trainX) // 128 , epochs = 10 , callbacks = callbacks, verbose =1 )
CIFAR-10: 实验1
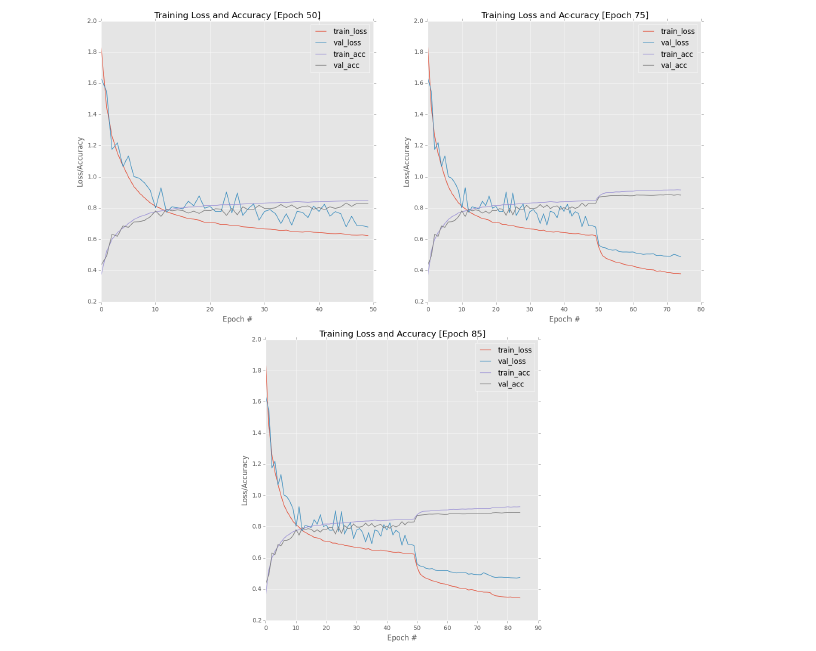
从这节开始,我们将对ResNet网络结构进行实验。一开始,模型各个参数值只能凭借经验决定,对于小数据集cifar-10,过多的filter可能会造成过拟合,因此,第一个实验的filters为(16, 16, 32, 64)。另外,我们知道网络越深,越有可能发生过拟合,因此,添加正则项是必须的,但是我们无法具体确定正则化系数的精确值,一般我们设置较小的正则化系数,即reg=0.0001,使用初始学习率为1e-1,动量为0.9的SGD算法进行训练模型。
图12.4 实验结果
运行以下命令进行训练:
1 $ python resnet_cifar10.py --checkpoints output/checkpoints
从图12.4左上方,可知,在50次epochs中,train_loss下降速度逐渐减缓,val_loss不稳定,波动较大,并且train_loss和val_loss之间的差距逐渐变大。因此在50次epochs后,我们停止训练,并降低学习率为1e-2,然后继续训练。
调整学习率后,我们加载第50次epoch保存的checkpoint模型继续训练,运行以下命令:
1 2 $ python resnet_cifar10.py --checkpoints output/checkpoints \ --model output/checkpoints/epoch_50.hdf5 --start-epoch 50
从图12.4右上,可知,降低学习率是有效的,train_loss和val_loss进一步降低,并且val_loss变得稳定了。但是train_loss和val_loss之间的差距随着训练的深入,差距也越来越大,并且从train_acc和val_acc变换曲线中,可以看到大约在第75次epoch慢慢地发生了过拟合。因此,在第75次epoch,我们再一次停止训练,并再次降低学习率为1e-3,epochs设置为10,继续训练。
运行以下命令继续训练:
1 2 $ python resnet_cifar10.py --checkpoints output/checkpoints \ --model output/checkpoints/epoch_75.hdf5 --start-epoch 75
结果如图12.4(下图)所示,验证集的准确率达到了89.06%,对于第一个实验来说,89.06%是一个好的开始,虽然,它比第11章中GoogLeNet取得的90.81%还要低。此外,从其他人实验报告中,可知在CIFAR-10数据集上ResNet的准确度大约能达到93左右%,说明我们还需要做一些工作来提高准确率。
CIFAR-10: 实验2
第一个实验我们取得了89.06%的准确率,显然没有达到目标。所以,在保证网络深度不变的情况下,我们增加filters的个数,即令filter=(16,64,128,256)。
注意 :我们只修改residual模块中的filter个数,即所有residual模块中的filter的数量是先前实验的两倍(第一个CONV层中的filter的数量保持不变)。优化算法同样是SGD,reg=0.0001。
图12.5 实验2结果
实验2的结果如图12.5所示,从图12.5(左上)可知,在40次epoch之后,我们可以很清楚地看到train_loss和val_loss之间的差距,但总体而言,val_acc仍与train_acc保持一致。为了提高accuracy,我们降低学习率从1e-1到1e-2,并训练5次epochs,从图12.5(右上),我们可以看到模型已经完全停滞。45次epochs后,我们再一次降低学习率从从1e-2到1e-3,结果从图12.5(下),可知模型同样处于停滞状态,甚至发生过拟合问题(val_loss轻微上升).
有趣的是,从图12.5(下),我们可以发现train_loss和val_loss基本都停滞了,这与前一章我们用GoogLeNet网络做的实验没什么不同。在第一次降低学习率之后,模型似乎无法再学习到更加高级的特征。总的来说,在50次epochs之后,验证机集的准确率为90.10%,比第一个实验有所提高。
ResNet on CIFAR-10: 实验3
从第二个实验结果中,可以发现增加filter的个数是有帮助的。但是,在第一次学习率下降之后,模型停滞不前仍然令人困扰。我相信学习率的缓慢线性下降有助于解决这个问题,但是无法保证学习率衰减的超参数是最优的。
因此,我们首先尝试对网络结构进行修改,将第一个CONV层的filter的个数增加到64(从16个增加到64个),即filters=(64,64,128,256),因为第二个实验中residual模块中filter的个数增加提高了accuracy,没理由我们不增加第一个conv层的filter个数。
另外,在第二个实验中,我们看到模型发生了过拟合,因此,我们将正则化系数从0.0001增加到0.0005。
同时也考虑过降低初始学习率,但是对于ResNet网络结构而言,使用1e-1的初始学习率训练没有问题,因此,觉得没必要一开始就把学习率降低到1e-2,或许这样做有助于训练平稳(例如,减少val_loss/val_acc的波动),但最终会导致训练完成后准确率降低(在同样的epochs次数下)。
图12.6 实验3结果
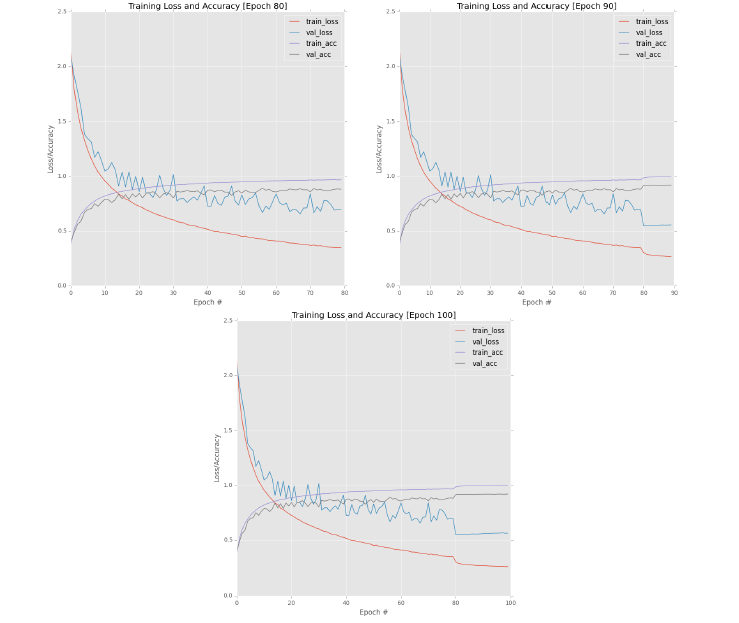
实验3的结果如图12.6所示,从图12.6(左上),可知,前80次epochs中,随着训练的深入,train_loss与val_loss之间的差距越来越大,train_acc和val_acc之间也明显存在差距,我们可以肯定的是模型发生了过拟合。虽然模型发生了过拟合(train_loss明显下降比val_loss快),但是其实我们还可以迭代多次,因为val_loss还是在降低的。
我们在第80次epoch停止训练,并降低了学习率到1e-2,接着再训练了10次epoch,结果如图12.6(右上),我们可以看到loss都下降,acc都上升了。但是在80次epoch之后,val_loss和val_acc就停滞了,并且val_loss逐渐上升,显然是发生过拟合了。
为了验证确实发生了过拟合,我们在第90次epoch停止训练,并将学习率降低到1e-3,然后再训练10次epochs,结果如图12.6(下),很明显,模型发生了过拟合,因为随着迭代次数的增加,train_loss下降或者保持不变,而val_loss反而变大。
从图12.6下,可知在第100次epochs后,验证集的准确率为91.83%,高于我们前两次实验。唯一的问题是模型发生了过拟合——我们需要一种方法来既能获得高精度又能保证模型不发生过拟合。
CIFAR-10:学习率衰减
从上面实验中,我们发现epochs为80-100之间左右,我们可以获得一个比较好的精度。但是仍然存在两个问题:
每次降低学习率时,精度瞬间有所提高,但是之后,模型就停滞了。
过拟合问题。
下面,我们将一一解决这些问题,新建一个名resnet_cifar10_decay.py文件,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import matplotlibmatplotlib.use("Agg" ) from sklearn.preprocessing import LabelBinarizerfrom pyimagesearch.nn.conv import resnetfrom pyimagesearch.callbacks import epochcheckpoint as EPOfrom pyimagesearch.callbacks import trainingmonitor as TMfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.datasets import cifar10from keras.callbacks import LearningRateSchedulerfrom keras.optimizers import SGDfrom keras.models import load_modelimport keras.backend as Kimport numpy as npimport argparseimport sysimport os
与之前章节实验一样,学习率按照多项式衰减进行更新:
1 2 3 4 5 6 7 8 9 10 11 12 NUM_EPOCHS = 100 INIT_LR = 1e-1 def ploy_decay (epoch ): maxEpochs = NUM_EPOCHS baseLR = INIT_LR power = 1.0 alpha = baseLR * (1 - (epoch / float (maxEpochs))) ** power return alpha
这里,总的迭代次数为100次,初始学习率为1e-1。
解析命令行参数:
1 2 3 4 5 ap = argparse.ArgumentParser() ap.add_argument('-m' ,'--model' ,required=True ,help ='path to output model ' ) ap.add_argument('-o' ,'--output' ,required=True ,help ='path to output directory (logs,plots,etc.)' ) args = vars (ap.parse_args())
其中:
model: 模型保存路径
output:日志,图表等保存路径
从磁盘中加载cifar-10数据集,并进行零均值化处理:
1 2 3 4 5 6 7 8 9 10 print ('[INFO] loading CIFAR-10 data...' )((trainX,trainY),(testX,testY)) = cifar10.load_data() trainX = trainX.astype("float" ) testX = testX.astype("float" ) mean = np.mean(trainX,axis =0 ) trainX -= mean testX -= mean
对标签数据进行编码处理:
1 2 3 4 lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.fit_transform(testY)
为了提高准确度和防止过拟合,我们对训练数据进行数据增强处理:
1 2 3 4 5 aug = ImageDataGenerator(width_shift_range=0.1 , height_shift_range=0.1 , horizontal_flip=True , fill_mode='nearest' )
回调函数列表:
TrainingMonitor:主要监控训练过程各个指标的变化
LearningRateScheduler:训练过程中进行学习率更新
1 2 3 4 5 6 7 8 figPath = os.path.sep.join([args['output' ],"{}.png" .format (os.getpid())]) jsonPath = os.path.sep.join([args['output' ],"{}.json" .format (os.getpid())]) callbacks = [ TM.TrainingMonitor(figPath,jsonPath), LearningRateScheduler(ploy_decay) ]
接下来初始化学习率和编译模型,注意 :其中各个参数值我们主要根据之前的实验得到:
1 2 3 4 5 print ("[INFO] compiling model..." )opt = SGD(lr=INIT_LR,momentum=0.9 ) model = resnet.ResNet.build(32 , 32 , 3 , 10 , (9 , 9 , 9 ), (64 , 64 , 128 , 256 ), reg=0.0005 ) model.compile (loss='categorical_crossentropy' , optimizer=opt, metrics=['accuracy' ])
训练模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 print ("[INFO] training network....." )model.fit_generator( aug.flow(trainX,trainY,batch_size=128 ), validation_data = (testX,testY), steps_per_epoch = len (trainX) // 128 , epochs = 10 , callbacks = callbacks, verbose =1 ) print ("[INFO] serializing network..." )model.save(args['model' ])
以上我们完成了学习率衰减方式训练模型,接下来通过实验来看看学习率衰减是否有效果.
CIFAR-10: 实验4
如前面代码所示,我们使用SGD优化算法,学习率为1e-1,动量为0.9,总的迭代次数为100,学习率按照线性衰减进行更新。
执行以下代码进行训练:
1 2 $ python resnet_cifar10_decay.py --output output \ --model output/resnet_cifar10.hdf5
图12.7 实验4结果
实验结果如图12.7所示。与之前实验一样,train_loss和val_loss在第10次epoch左右开始出现差距,不一样的是,随着迭代次数增加,train_loss与val_loss之间的差距似乎没有明显被拉大,也就是说val_loss与train_loss近似同速度下降。这个结果很重要,因为它表明模型的过拟合是可控的。我们必须承认在CIFAR-10数据集上训练模型是肯定会发生过拟合问题,但是,我们需要控制过拟合的幅度。通过应用学习率衰减,我们成功地做到了这一点。
虽然,我们一定上把控了过拟合,但是精度是否提高了呢?我们将最后几次epoch结果打印出来,如下所示:
1 2 3 4 5 6 7 Epoch 98/100 247s - loss: 0.1563 - acc: 0.9985 - val_loss: 0.3987 - val_acc: 0.9351 Epoch 99/100 245s - loss: 0.1548 - acc: 0.9987 - val_loss: 0.3973 - val_acc: 0.9358 Epoch 100/100 244s - loss: 0.1538 - acc: 0.9990 - val_loss: 0.3978 - val_acc: 0.9358 [INFO] serializing network...
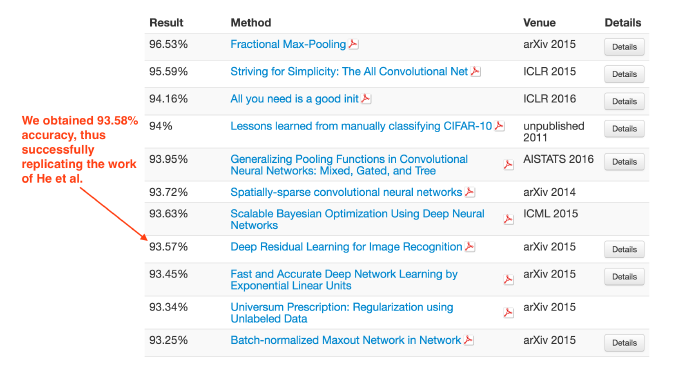
100次epochs之后,测试集的准确率达到了93.58%,这个结果大大高于我们之前的两个实验,更重要的是,我们复现了he等人的实验结果。
看一下CIFAR-10排行榜,我们发现he等人的准确率达到了93.57%,接近我们的结果(如图12.8)——红色的箭头表示我们的准确性。
图12.8 CIFAR-10排行榜
## ResNet on Tiny ImageNet
在本节中,我们将在tiny ImageNet数据集上训练ResNet网络架构。类似于前面的CIFAR-10实验,我们第一次在tiny ImageNet数据集上训练ResNet网络,所以我们将按照相同的实验过程进行训练:
按照ctrl+c方式进行训练,获得一个baseline结果。
如果学习率下降后模型发生停滞,则进行学习率衰减方式进行更新学习率。
整个项目目录结构如下所示:
1 2 3 4 5 6 7 8 9 10 --- resnet_tinyimagenet.py | |--- config | | |--- __init__.py | | |--- tiny_imagenet_config.py | |--- rank_accuracy.py | |--- train.py | |--- train_decay.py | |--- output/ | | |--- checkpoints/ | | |--- tiny-image-net-200-mean.json
其中配置文件tiny_imagenet_config.py与GoogLeNet实验一样,我们只需修改MODEL_PATH、FIG_PATH和JSON_PATH即可:
1 2 3 4 5 6 7 8 OUTPUT_PATH = "output" MODEL_PATH = path.sep.join([OUTPUT_PATH, "resnet_tinyimagenet.hdf5" ]) FIG_PATH = path.sep.join([OUTPUT_PATH, 'resnet56_tinyimagenet.png' ]) JSON_PATH = path.sep.join([OUTPUT_PATH, 'resnet56_tinyimage.json' ])
在前面,我们搭建ResNet网络结构时,我们提到dataset参数,如下:
1 2 @staticmethod def build (width,height,depth,classes,stage,filters,reg = 0.0001 ,bnEps=2e-5 ,bnMom=0.9 ,dataset='cifar' ):
该值默认为cifar,但是,由于我们现在使用的是Tiny ImageNet数据集,所以我们需要更新ResNet网络结构代码,主要是修改if/elif块。在resnet.py脚本中加入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 if dataset == 'cifar' : x = Conv2D(filters[0 ],(3 ,3 ),use_bias = False ,padding='same' ,kernel_regularizer = l2(reg))(x) elif dataset =='tiny_imagenet' : x = Conv2D(filters[0 ],(5 ,5 ),use_bias = False ,padding='same' ,kernel_regularizer=l2(reg))(x) x = BatchNormalization(axis = chanDim,epsilon = bnEps,momentum=bnMom)(x) x = Activation('relu' )(x) x = ZeroPadding2D((1 ,1 ))(x) x = MaxPooling2D((3 ,3 ),strides = (2 ,2 ))(x)
很明显,tiny imagenet数据集的处理方式与cifar-10数据集不一样。首先,由于输入的feature map比较大,我们使用5x5的CONV层(在完整的ImageNet数据集实现中,我们实际上使用的是7x7的filter)。其次,在BN层之后紧接RELU激活层和Max pooling层。这里的Max pooling是ResNet网络结构中唯一使用到的Max pooling层,并且pooling的大小为3x3,步长为2x2。结合之前的ZeroPadding2D层,pooling层确保我们的输出feature map大小为32x32,与cifar-10数据集实验的输入图像的大小相同,这样我们可以轻松地重用ResNet网络结构的其余部分,而无需进行任何其他更改。
Tiny ImageNet: ctrl+c方法
新建一个名为train.py文件,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import matplotlibmatplotlib.use("Agg" ) from config import tiny_imagenet_config as configfrom pyimagesearch.preprocessing import imagetoarraypreprocessor as ITAPfrom pyimagesearch.preprocessing import simplespreprocessor as SIPfrom pyimagesearch.preprocessing import meanpreprocessor as MPfrom pyimagesearch.callbacks import epochcheckpoint as EPOfrom pyimagesearch.callbacks import trainingmonitor as TMfrom pyimagesearch.io import hdf5datasetgenerator as HDFGfrom pyimagesearch.nn.conv import resnetfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.optimizers import Adam,SGDfrom keras.models import load_modelimport keras.backend as Kimport argparseimport jsonimport sys
解析命令行参数:
1 2 3 4 5 6 7 8 9 10 ap = argparse.ArgumentParser() ap.add_argument('-c' ,'--checkpoints' ,required=True , help ='path to output checkpoint directory' ) ap.add_argument('-m' ,'--model' ,type =str , help ='path to *specific* model checkpoint to load' ) ap.add_argument('-s' ,'--start_epoch' ,type = int ,default=0 , help ='epoch to restart training at' ) args=vars (ap.parse_args())
其中:
checkpoints:保存checkpoint模型路径
model:模型保存路径
start_epoch:重新开始训练checkpoint模型
数据增强处理:
1 2 3 4 5 6 7 aug = ImageDataGenerator(rotation_range=18 ,zoom_range=0.15 , width_shift_range=0.2 ,height_shift_range=0.2 ,shear_range=0.15 , horizontal_flip=True ,fill_mode='nearest' ) means = json.loads(open (config.DATASET_MEAN).read())
数据预处理:
1 2 3 4 5 6 7 8 9 10 11 sp = SIP.SimplePreprocessor(64 ,64 ) mp = MP.MeanPreprocessor(means['R' ],means['G' ],means['B' ]) iap = ITAP.ImageToArrayPreprocessor() trainGen = HDFG.HDF5DatasetGenerator(config.TRAIN_HDF5,64 ,aug = aug, preprocessors=[sp,mp,iap],classes=config.NUM_CLASSES) valGen = HDFG.HDF5DatasetGenerator(config.VAL_HDF5,64 , preprocessors=[sp,mp,iap],classes=config.NUM_CLASSES)
如果我们第一次训练网络,则需要初始化网络结构:
1 2 3 4 5 6 7 8 9 if args['model' ] is None : print ("[INFO] compiling model...." ) model = resnet.ResNet.build(width=64 ,height=64 ,depth=3 ,classes=config.NUM_CLASSES,(3 ,4 ,6 ),(64 ,128 ,256 ,512 ),reg=0.0005 ,dataset='tiny_imagenet' ) opt = SGD(lr=1e-2 , momentum=0.9 ) model.compile (loss='categorical_crossentropy' ,optimizer=opt, metrics=['accuracy' ])
这里需要注意的是stage列表,stage=(3,4,6)是参考论文《Deep Residual Learning for Image Recognition》的设置,该论文使用了类似的residual模块堆叠方式在全量的imagenet数据集上训练。
另外tiny imagenet数据集比CIFAR-10数据集复杂,我们很自然地认为需要更多的filters,因此,我们对filters列表进行更新,即filters=(64、128、256、512),也就是说第一CONV层由64个5x5的filter组成。之后三个stage中,每个stage的residual模块对应的K为128、256和512。
如果指定了checkpoint,则从磁盘中加载checkpoint模型,并更新参数(比如学习率等):
1 2 3 4 5 6 7 8 9 else : print ("[INFO] loading {}..." .format (args['model' ])) model = load_model(args['model' ]) print ("[INFO] old learning rate:{}" .format (K.get_value(model.optimizer.lr))) K.set_value(model.optimizer.lr,1e-5 ) print ("[INFO] new learning rate: {}" .format (K.get_value(model.optimizer.lr)))
回调函数列表:
1 2 3 4 5 6 callbacks = [ EPO.EpochCheckpoint(args['checkpoints' ],every=5 ,startAt = args['start_epoch' ]), TM.TrainingMonitor(config.FIG_PATH,jsonPath=config.JSON_PATH,startAt = args['start_epoch' ]) ]
训练网络:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 model.fit_generator( trainGen.generator(), steps_per_epoch = trainGen.numImages // 64 , validation_data = valGen.generator(), validation_steps = valGen.numImages // 64 , epochs = 50 , max_queue_size = 64 * 2 , callbacks = callbacks, verbose = 1 ) trainGen.close() valGen.close()
一开始,我们无法确定训练ResNet网络所需的总epochs次数,因此我们把epochs设置为一个较大的数字,并根据需要进行调整。
Tiny ImageNet: 实验1
运行以下命令进行训练网络:
1 $ python train.py --checkpoints output/checkpoints
图12.9 实验1结果
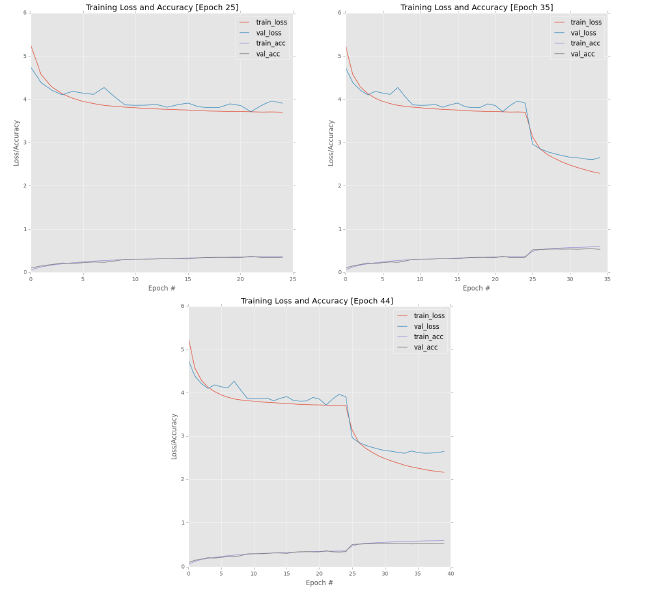
我们对前25次epochs的训练过程进行可视化,如图12.9(左上)所示,我们观察train_loss的变化曲线,很明显可以看到模型开始发生停滞。因此,我们在第25次epoch停止训练,并降低学习率为1e-2,且修改epochs为10,然后接着继续训练:
1 2 $ python train.py --checkpoints output/checkpoints \ --model output/checkpoints/epoch_25.hdf5 --start-epoch 25
结果如图12.9(右上)所示,降低学习率后,很明显地train_loss降低,准确度提高。
但是,我们仔细观察train_loss和val_loss曲线变化,在降低学习率之后,一开始train_loss和val_loss同步下降,随着迭代次数的增加,train_loss下降的速度明显比val_loss下降的速度快。因此,我们在第35次epochs再次降低学习率为1e-3,然后接着继续训练:
1 2 $ python train.py --checkpoints output/checkpoints \ --model output/checkpoints/epoch_35.hdf5 --start-epoch 35
结果如图12.9(下)所示,这里我们只训练5次,因为模型已经发生了明显的过拟合问题。在学习率降低到1e-3之后,val_loss开始增加,而train_loss下降速度越来越快,很明显发生过拟合,因此我们在第40次epochs之后,完全停止训练,此时模型的验证集准确率为53.14%。
执行以下命令获得rank-N准确度信息:
1 2 3 4 5 $ python rank_accuracy.py [INFO] loading model... [INFO] predicting on test data... [INFO] rank-1: 53.10% [INFO] rank-5: 75.43%
从结果中,模型在测试集上的准确率为53.10%,还不错,接近了GoogLeNet网络在tiny imagenet上的准确度。另外我们从GoogLeNet实验中发现学习率衰减有助于提高准确率,因此我们下面同样对ResNet网络实验应用学习率衰减方法。
ResNet:学习率衰减
新建一个名为train_decay.py文件,并插入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import matplotlibmatplotlib.use("Agg" ) from config import tiny_imagenet_config as configfrom pyimagesearch.preprocessing import imagetoarraypreprocessor as ITAPfrom pyimagesearch.preprocessing import simplespreprocessor as SIPfrom pyimagesearch.preprocessing import meanpreprocessor as MPfrom pyimagesearch.callbacks import epochcheckpoint as EPOfrom pyimagesearch.callbacks import trainingmonitor as TMfrom pyimagesearch.io import hdf5datasetgenerator as HDFGfrom pyimagesearch.nn.conv import resnetfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.callbacks import LearningRateSchedulerfrom keras.optimizers import Adam,SGDfrom keras.models import load_modelimport keras.backend as Kimport argparseimport jsonimport sysimport os
接下来,定义学习率衰减函数:
1 2 3 4 5 6 7 8 9 10 11 12 NUM_EPOCHS = 75 INIT_LR = 1e-1 def ploy_decay (epoch ): maxEpochs = NUM_EPOCHS baseLR = INIT_LR power = 1.0 alpha = baseLR * (1 - (epoch / float (maxEpochs))) ** power return alpha
解析命令行参数:
1 2 3 4 5 ap = argparse.ArgumentParser() ap.add_argument('-m' ,'--model' ,required=True ,help ='path to output model ' ) ap.add_argument('-o' ,'--output' ,required=True ,help ='path to output directory (logs,plots,etc.)' ) args = vars (ap.parse_args())
其中:
model: 模型保存路径
output: 输出日志、图标等保存路径
初始化数据增强类,以及从磁盘中加载RGB通道均值文件:
1 2 3 4 5 6 7 aug = ImageDataGenerator(rotation_range=18 ,zoom_range=0.15 , width_shift_range=0.2 ,height_shift_range=0.2 ,shear_range=0.15 , horizontal_flip=True ,fill_mode='nearest' ) means = json.loads(open (config.DATASET_MEAN).read())
初始化数据预处理函数:
1 2 3 4 5 6 7 8 9 10 sp = SIP.SimplePreprocessor(64 ,64 ) mp = MP.MeanPreprocessor(means['R' ],means['G' ],means['B' ]) iap = ITAP.ImageToArrayPreprocessor() trainGen = HDFG.HDF5DatasetGenerator(config.TRAIN_HDF5,64 ,aug = aug, preprocessors=[sp,mp,iap],classes=config.NUM_CLASSES) valGen = HDFG.HDF5DatasetGenerator(config.VAL_HDF5,64 , preprocessors=[sp,mp,iap],classes=config.NUM_CLASSES)
回调函数列表:
1 2 3 4 5 6 7 figPath = os.path.sep.join([args['output' ],"{}.png" .format (os.getpid())]) jsonPath = os.path.sep.join([args['output' ],"{}.json" .format (os.getpid())]) callbacks = [ TM.TrainingMonitor(figPath,jsonPath), LearningRateScheduler(ploy_decay) ]
初始化ResNet网络和SGD优化算法:
1 2 3 4 5 print ("[INFO] compiling model..." )opt = SGD(lr=INIT_LR,momentum=0.9 ) model = resnet.ResNet.build(64 , 64 , 3 , config.NUM_CLASSES, (3 , 4 , 6 ), (64 , 128 , 256 , 512 ), reg=0.0005 ,dataset='tiny_imagenet' ) model.compile (loss='categorical_crossentropy' , optimizer=opt, metrics=['accuracy' ])
最后,以64的batch进行训练ResNet网络:
1 2 3 4 5 6 7 8 9 10 11 print ("[INFO] training network...." )model.fit_generator( trainGen.generator(), steps_per_epoch = trainGen.numImages // 64 , validation_data = valGen.generator(), validation_steps = valGen.numImages // 64 , epochs = NUM_EPOCHS, max_queue_size = 64 * 2 , callbacks = callbacks, verbose = 1 )
保存模型:
1 2 3 4 5 6 7 print ("[INFO] serializing network..." )model.save(args['model' ]) trainGen.close() valGen.close()
Tiny ImageNet: 实验2
运行以下进行训练模型:
1 2 $ python train_decay.py --model output/resnet_tinyimagenet_decay.hdf5 \ --output output
图12.11 实验2结果
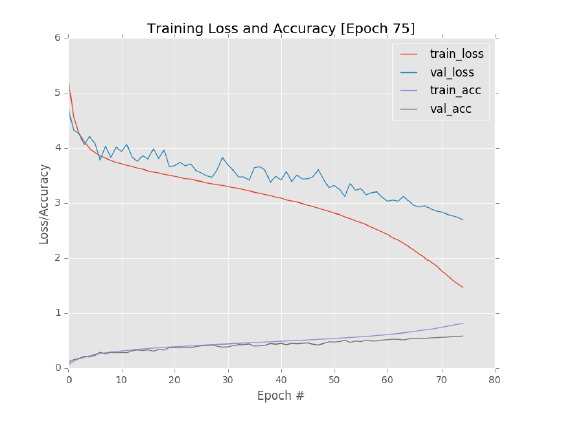
结果如图12.11所示。train_loss和val_loss相互下降,直到第60次epoch,train_loss与val_loss之间的差距才逐渐扩大。但是,val_loss也在继续减少。在第75次epoch结束,rank-1的准确率为58.32%。
运行以下命令对测试集进行评估:
1 2 3 4 5 $ python rank_accuracy.py [INFO] loading model... [INFO] predicting on test data... [INFO] rank-1: 58.03% [INFO] rank-5: 80.46%
在测试集上,rank-1的准确率为58.03%,rank-5的准确率为80.46%,这比我们上一章的GoogLeNet网络的结果提高了不少。
总结
在本章中,我们详细讨论了ResNet网络结构,包括residual模块。He等人在2015年的论文《Deep Residual Learning for Image Recognition》中提出了原始的residual模块,目前经过了好几次优化。原始的residual模块由两个CONV层和一个identity mapping “shortcut”组成。在同一篇论文中,作者发现由序列1x1、3x3和1x1CONV层组成的“bottleneck”可以提高准确率。
之后,He等人在2016年的论文《Identity Mappings in Deep Residual Networks》又提出了residual模块一个改进版本——pre-activation residual模块。之所以叫“pre-activation”,是因为作者在构建ResNet网络结构时,把激活层和BN层放在了CONV层前面,与我们之前构造卷积神经网络的经验原则不太一样。
之后,我们基于keras框架实现了bottlececk和pre-activation类型的ResNet网络结构,并在CIFAR-10数据集和tiny ImageNet数据集上进行训练。在CIFAR-10数据集中,我们复现了He等人的结果,获得了93.58%的准确率。在tiny ImageNet数据集上,我们获得了58.03%的准确率。
本文完整代码位于:github