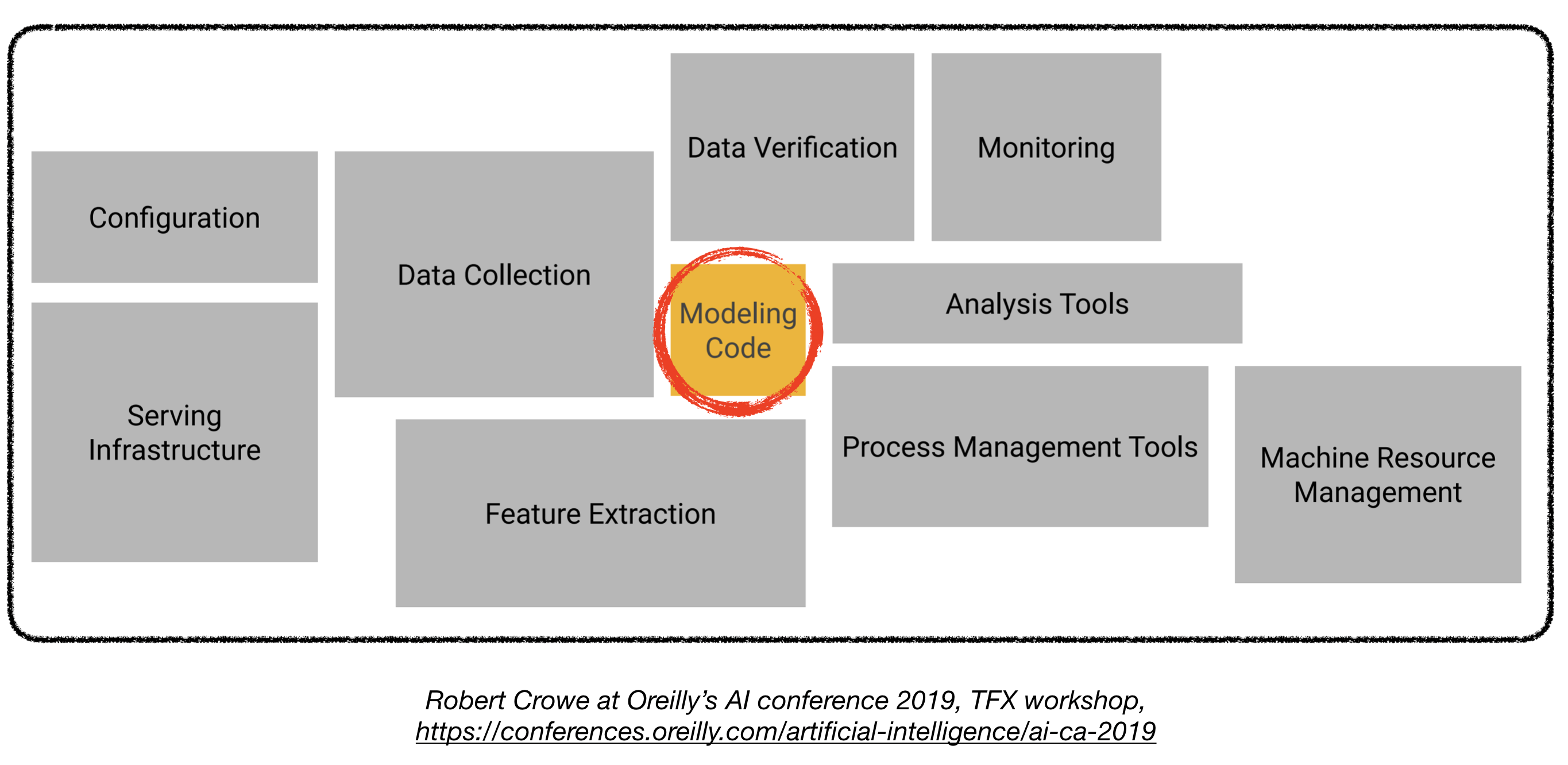
产品级深度学习系统入门指南
部署产品级的深度学习模型充满挑战,其难度远远超过训练一个性能不俗的模型。为了部署一个产品级的深度学习系统,还需要设计和开发以下几个部分(见下图):
本文可以作为一篇工程指南去构建一个产品级的深度学习系统,并且该系统可以部署在真实的生产环境中。
本文借鉴了如下文章:
Full Stack Deep Learning Bootcamp (by Pieter Abbeel at UC Berkeley, Josh Tobin at OpenAI, and Sergey Karayev at Turnitin), TFX workshop by Robert Crowe, and Pipeline.ai’s Advanced KubeFlow Meetup by Chris Fregly.
Machine Learning Projects 机器学习项目
[译者注]原作者在文中既使用了Mechine Learning(机器学习),又使用了Deep Learning(深度学习,大部分工具可以两者都适用)
有趣的真相 :flushed: fact: 85%的AI项目会失败. 1 潜在的原因如 ...
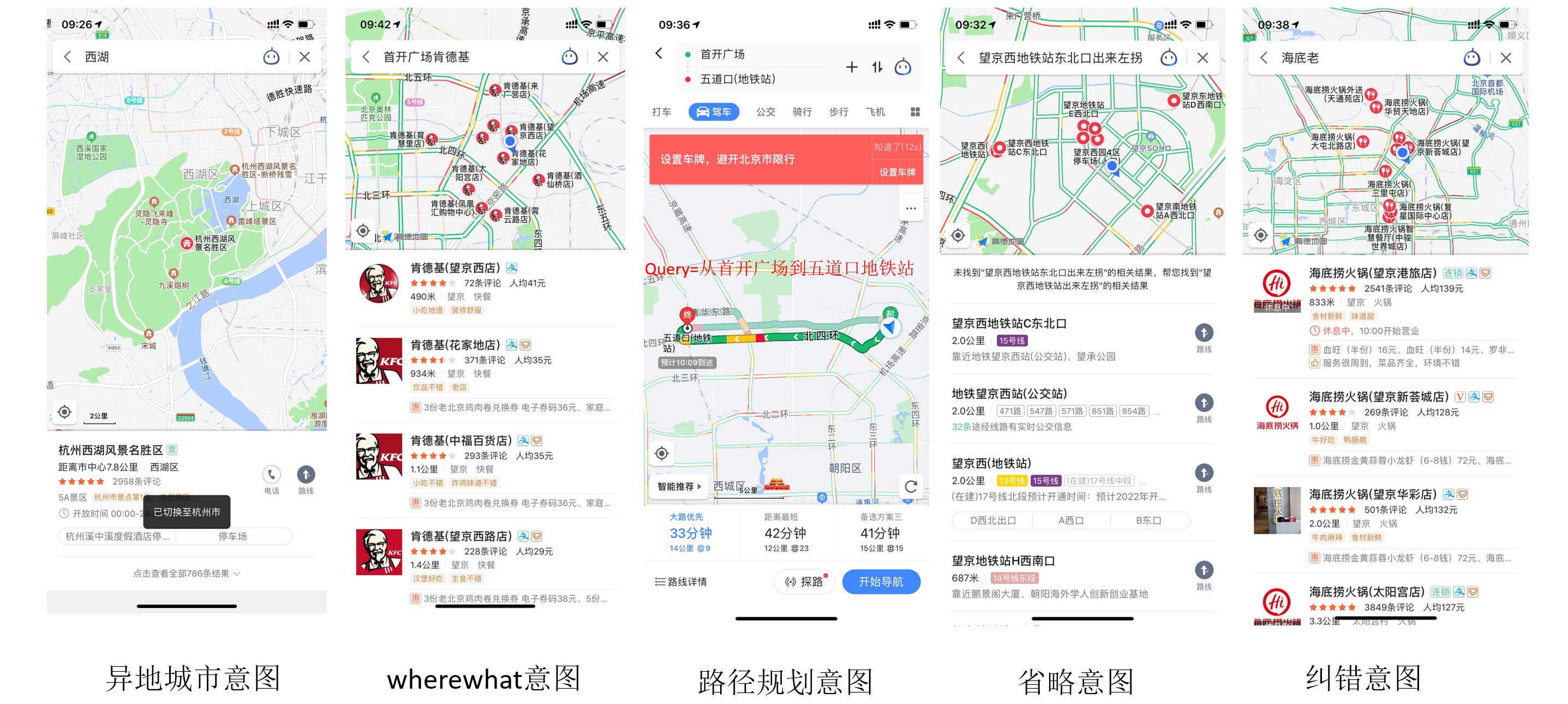
地理文本处理技术在高德的演进
地图App的功能可以简单概括为定位,搜索,导航三部分,分别解决在哪里,去哪里,和怎么去的问题。高德地图的搜索场景下,输入的是,地理相关的检索query,用户位置,App图面等信息,输出的是,用户想要的POI。如何能够更加精准地找到用户想要的POI,提高满意度,是评价搜索效果的最关键指标。
一个搜索引擎通常可以拆分成query分析、召回、排序三个部分,query分析主要是尝试理解query表达的含义,为召回和排序给予指导。
地图搜索的query分析不仅包括通用搜索下的分词,成分分析,同义词,纠错等通用NLP技术,还包括城市分析,wherewhat分析,路径规划分析等特定的意图理解方式。
常见的一些地图场景下的query意图表达如下:
query分析是搜索引擎中策略密集的场景,通常会应用NLP领域的各种技术。地图场景下的query分析,只需要处理地理相关的文本,多样性不如网页搜索,看起来会简单一些。但是,地理文本通常比较短,并且用户大部分的需求是唯一少量结果,要求精准度非常高,如何能够做好地图场景下的文本分析,并提升搜索结果的质量,是充满挑战的。
整体技术架构
类似于通用检索的架构,地 ...

(转)组建技术团队的一些思考
68d4c704ab608d783d8a8a5d59eda75a87edb4142e54b5833dd4933ea86f97dfc57d4fccf0a24157a2245041e4c81ba0cab66c0cefce8e9167aaa5d4963ccad8f5454d1a12d66642fc27e7da97bacbbe738cf0161727b36d35eb66c63865f28dc90bf2f0c7f8fe85c485a71ca6c4f084c36a29f6f28e6a6b8d2201acdaf146d2738738c80cc37f917b7a13420b4afffad721fbb9ddc6ad49d2ba97ee44aad0aa665b019e6c15d9f5c2d187f1ac1ad6041e9b317af62117870b9ad064c0f4a1200c520ec53b5a018d6860fad37bb9ef426e58b251203159a3d5b63c65009faa6466380d127ae63ce72e64ce8a1d404e82d6d9bbc2ffcda4f28 ...
利用 GitHub+Actions 自动部署 Hexo 博客
3a325dc39ad404746d7c8526f2f7a082e343685b54a9c7fb3c42d6c3b33f10fba8d374db088f643c182a00234d17603d5bf9c3c506caa12c0ae31713ece6005b366634e84b2bada3d200c81e2ae763f39cf9a090af062b11f772eede9cd73c53d34738cb32e5db74c88342587052593d7711ffed03c9a80d365fc121443c8de78eb5bee354489060d7b8580df3489a5bded256b3e89ec32be93ddd5407b019c92152809e277e55aaf4e2a69d5c3fe33a0e7e4f4bd7882147bafe07e79ba7a14cd2ad373c7c82773917465eabb9a50ac6aa24f622bc456fbbab69f20377f506b7bdd34dca6eb4210ac476f060b182fb30158babf60b891e373 ...
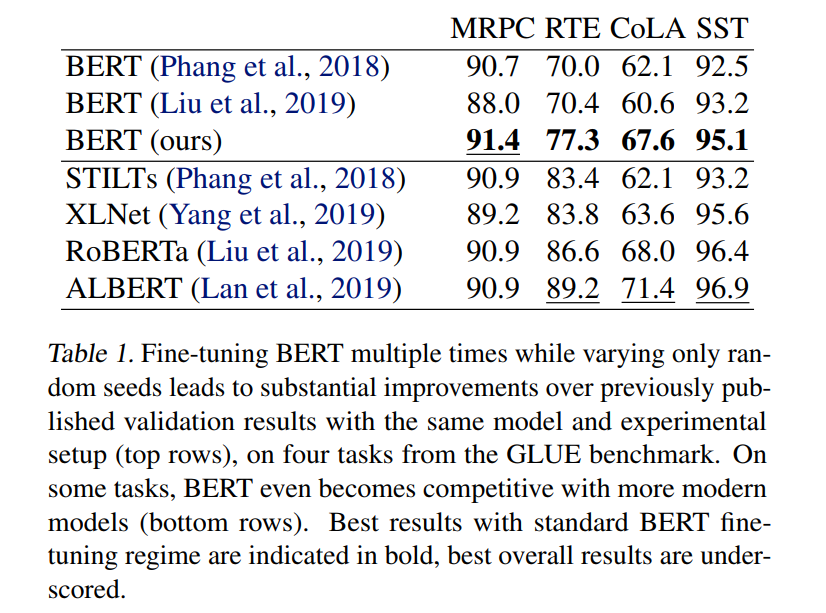
Fine-Tuning Pretrained Language Models ,Weight Initializations, Data Orders, and Early
当前的预训练模型如BERT都分为两个训练阶段:预训练和微调。但很多人不知道的是,在微调阶段,随机种子不同会导致最终效果呈现巨大差异。本文探究了在微调时参数初始化、训练顺序和early stopping对最终效果的影响,发现:参数初始化和训练顺序在最终结果上方差巨大,而early stopping可以节省训练开销。这启示我们去进一步探索更健壮、稳定的微调方式。
论文地址: https://arxiv.org/pdf/2002.06305.pdf
介绍
当前所有的预训练模型都分为两个训练阶段:预训练和微调。预训练就是在大规模的无标注文本上,用掩码语言模型(MLM)或其他方式无监督训练。微调,就是在特定任务的数据集上训练,比如文本分类。
然而,尽管微调使用的参数量仅占总参数量的极小一部分(约0.0006%),但是,如果对参数初始化使用不同的随机数种子,或者是用不同的数据训练顺序,其会对结果产生非常大的影响——一些随机数直接导致模型无法收敛,一些随机数会取得很好的效果。
比如,下图是在BERT上实验多次取得的结果,远远高于之前BERT的结果,甚至逼近更先进的预训练模型。似乎微调阶段会对最终效 ...
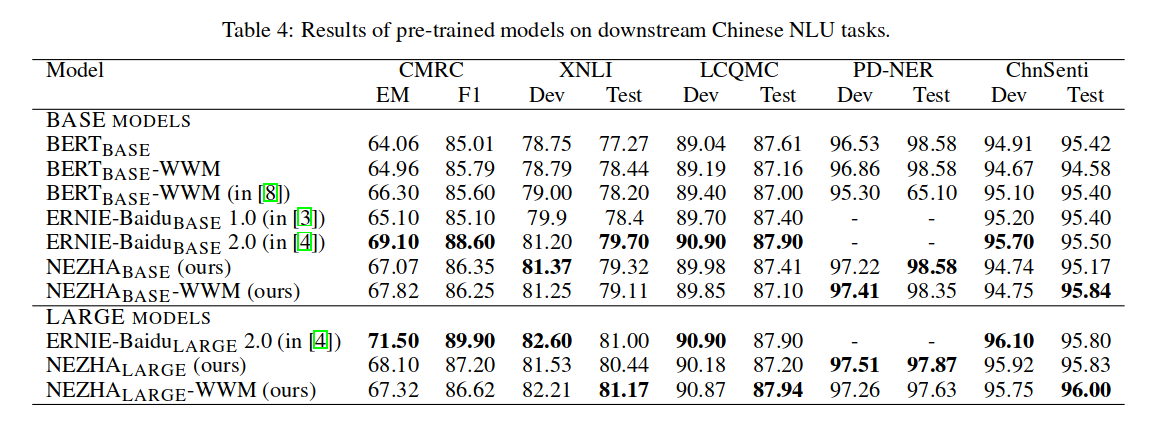
NEZHA-Neural Contextualized Representation for Chinese Language Understanding
预训练模型在捕捉深度语境表征方面的成功是有目共睹的。本文提出一个面向中文NLU任务的模型,名为NEZHA(NEural contextualiZed representation for CHinese lAnguage understanding,面向中文理解的神经语境表征模型,哪吒)。NEZHA相较于BERT有如下改进:
函数式相对位置编码
全词覆盖
混合精度训练
训练过程中使用 LAMB 优化器
前两者是模型改进,后两者是训练优化。
NEZHA在以下数个中文自然处理任务上取得了SOTA的结果:
命名实体识别(人民日报NER数据集)
句子相似匹配(LCQMC,口语化描述的语义相似度匹配)
中文情感分类(ChnSenti)
中文自然语言推断(XNLI)
介绍
预训练模型大部分是基于英文语料(BooksCorpus和English Wikipedia),中文的预训练模型目前现有如下几个:Google的中文BERT(只有base版)、ERNIE-Baidu、BERT-WWM(科大讯飞)。这些模型都是基于Transformer,且在遮蔽语言模型(MLM)和下一句预测(NSP)这两 ...

pip下载python包,离线安装
pip download 和 pip install 有着相同的解析和下载过程,不同的是,pip install 会安装依赖项,而 pip download 会把所有已下载的依赖项保存到指定的目录 ( 默认是当前目录 ),此目录稍后可以作为值传递给 pip install --find-links 以便离线或锁定下载包安装。适合在离线服务器上继续安装python模块,主要步骤如下:
首先在联网的环境中安装相同python环境,可使用conda创建虚拟环境
1conda create -n envir_name python=3.7
在虚拟环境中进行pip download下载所依赖包
1pip download tensorflow==2.11.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/ -d ./tensorflow2/
将下载的包的名字输出到 requirements.txt中
1ls tensorflow2 > requirements.txt
离线安装
1pip install --no-index --f ...
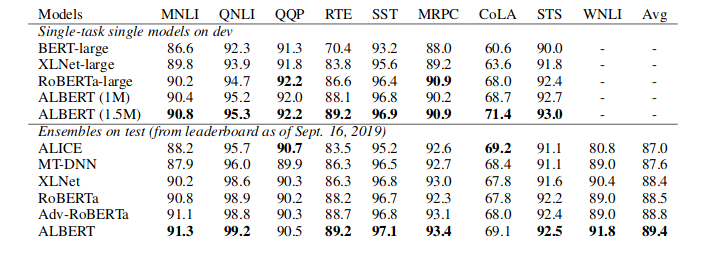
ALBERT-A Lite BERT For Self-Supervised Learning Of Language Representations
对于预训练模型来说,提升模型的大小能够提高下游任务的效果,然而如果进一步提升模型规模,势必会导致显存或者内存出现OOM的问题,长时间的训练也可能导致模型出现退化的情况。这次的新模型不再是简单的的升级,而是采用了全新的权重共享机制,反观其他升级版BERT模型,基本都是添加了更多的预训练任务,增大数据量等轻微的改动。ALBERT模型提出了两种减少内存的方法,同时提升了训练速度,其次改进了BERT中的NSP的预训练任务。
从ResNet论文可知,当模型的层次加深到一定程度后继续加深层深度会带来模型的效果下降,与之类似,如下图所示;
将BERT的hidden size增加,结果效果变差。因此,ALBERT模型三种手段来提升效果,又能降低模型参数量大小。
Embedding因式分解
从模型的角度来说,WordPiece embedding的参数学习的表示是上下文无关的,而隐藏层则学习的表示是上下文相关的。在之前的研究成果中表明,BERT及其类似的模型的好效果更多的来源于上下文信息的捕捉,因而,理论上来说隐藏层的表述包含的信息应该更多一些,隐藏层的大小应比embedding大,若让embed ...

2019达观杯信息提取第九名方案
2019达观杯信息提取第九名方案介绍以及代码地址
代码
代码地址: github
方案
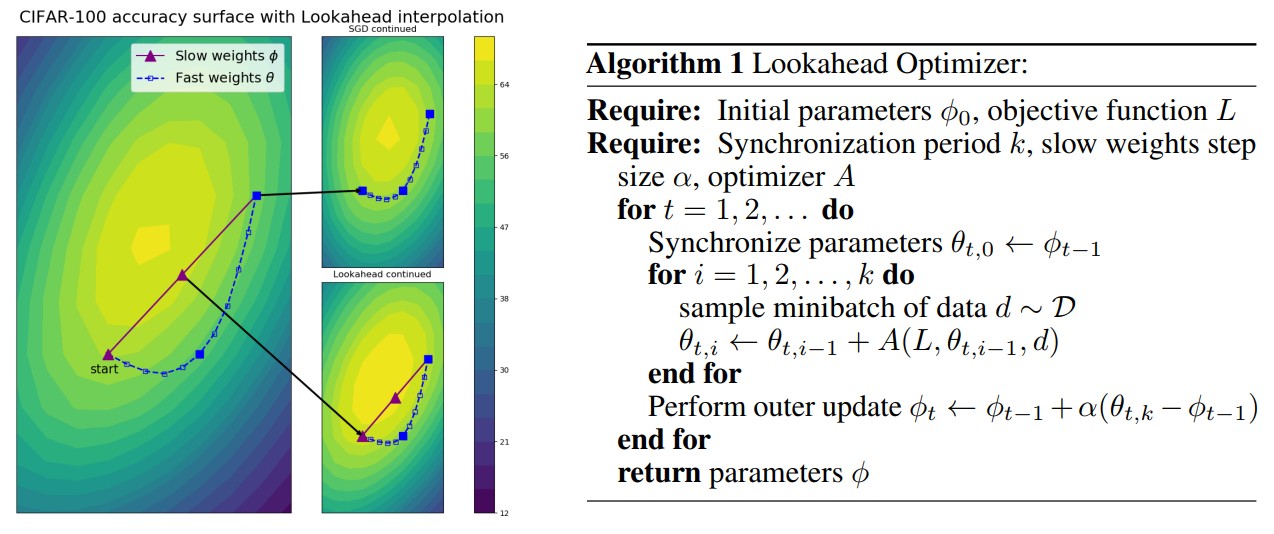
Lookahead Optimizer k steps forward, 1 step back
快来试试 Lookahead 最优化方法啊,调参少、收敛好、速度还快,大牛用了都说好。
最优化方法一直主导着模型的学习过程,没有最优化器模型也就没了灵魂。好的最优化方法一直是 ML 社区在积极探索的,它几乎对任何机器学习任务都会有极大的帮助。
从最开始的批量梯度下降,到后来的随机梯度下降,然后到 Adam 等一大帮基于适应性学习率的方法,最优化器已经走过了很多年。尽管目前 Adam 差不多已经是默认的最优化器了,但从 17 年开始就有各种研究表示 Adam 还是有一些缺陷的,甚至它的收敛效果在某些环境下比 SGD 还差。
为此,我们期待更好的标准优化器已经很多年了…
最近,来自多伦多大学向量学院的研究者发表了一篇论文,提出了一种新的优化算法——Lookahead。值得注意的是,该论文的最后作者 Jimmy Ba 也是原来 Adam 算法的作者,Hinton 老爷子也作为三作参与了该论文,所以作者阵容还是很强大的。
Lookahead 算法与已有的方法完全不同,它迭代地更新两组权重。直观来说,Lookahead 算法通过提前观察另一个优化器生成的「fast weights」序列,来选择 ...
