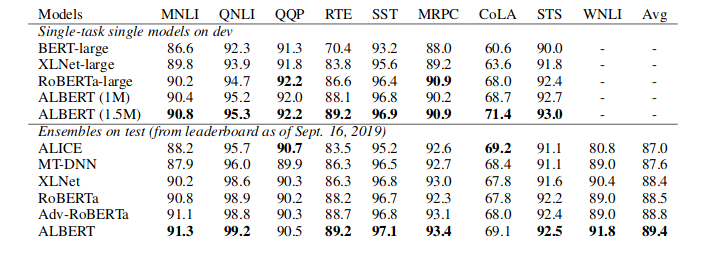
当前的预训练模型如BERT都分为两个训练阶段:预训练和微调。但很多人不知道的是,在微调阶段,随机种子不同会导致最终效果呈现巨大差异。本文探究了在微调时参数初始化、训练顺序和early stopping对最终效果的影响,发现:参数初始化和训练顺序在最终结果上方差巨大,而early stopping可以节省训练开销。这启示我们去进一步探索更健壮、稳定的微调方式。
介绍
当前所有的预训练模型都分为两个训练阶段:预训练和微调。预训练就是在大规模的无标注文本上,用掩码语言模型(MLM)或其他方式无监督训练。微调,就是在特定任务的数据集上训练,比如文本分类。
然而,尽管微调使用的参数量仅占总参数量的极小一部分(约0.0006%),但是,如果对参数初始化使用不同的随机数种子,或者是用不同的数据训练顺序,其会对结果产生非常大的影响——一些随机数直接导致模型无法收敛,一些随机数会取得很好的效果。
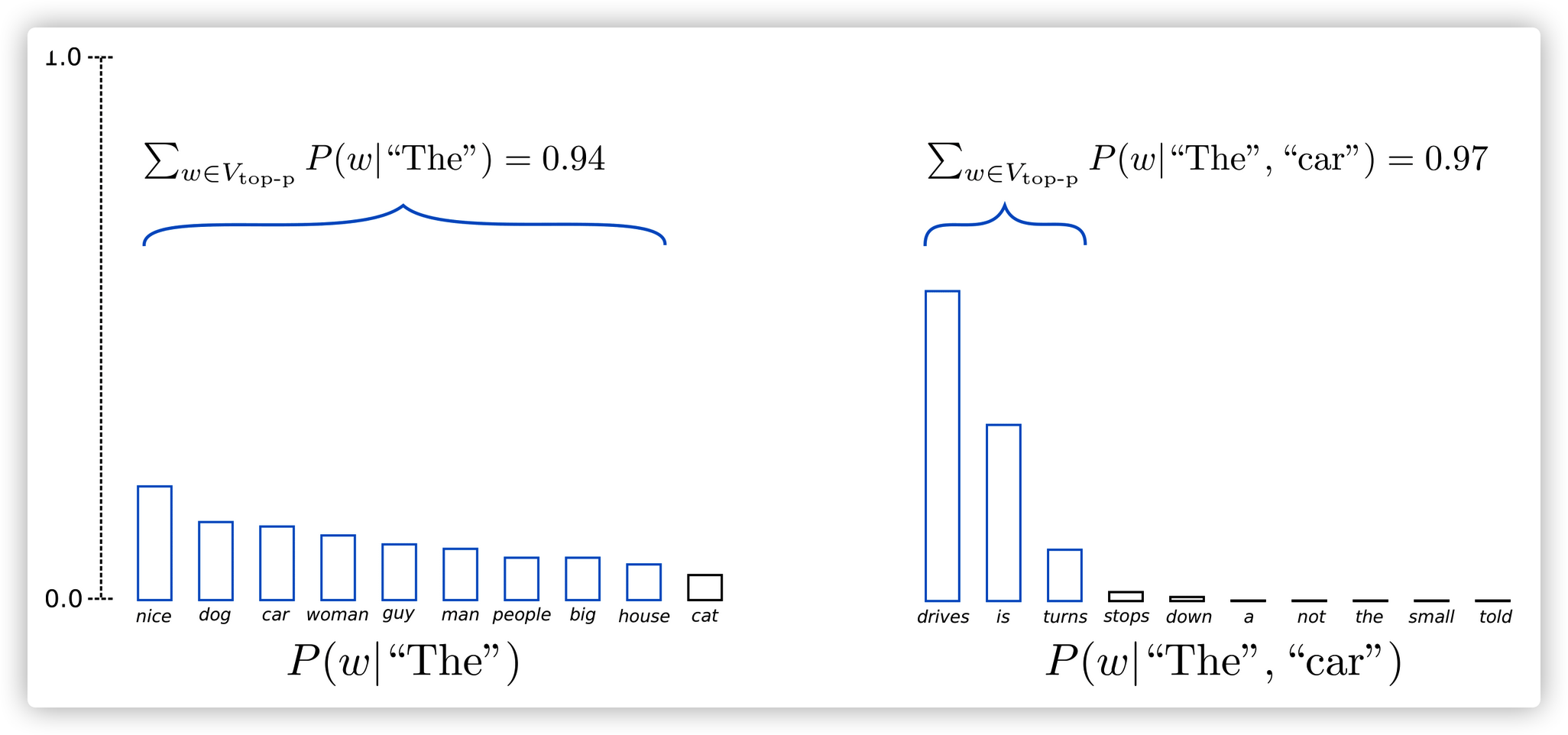
比如,下图是在BERT上实验多次取得的结果,远远高于之前BERT的结果,甚至逼近更先进的预训练模型。似乎微调阶段会对最终效果产生巨大的方差。
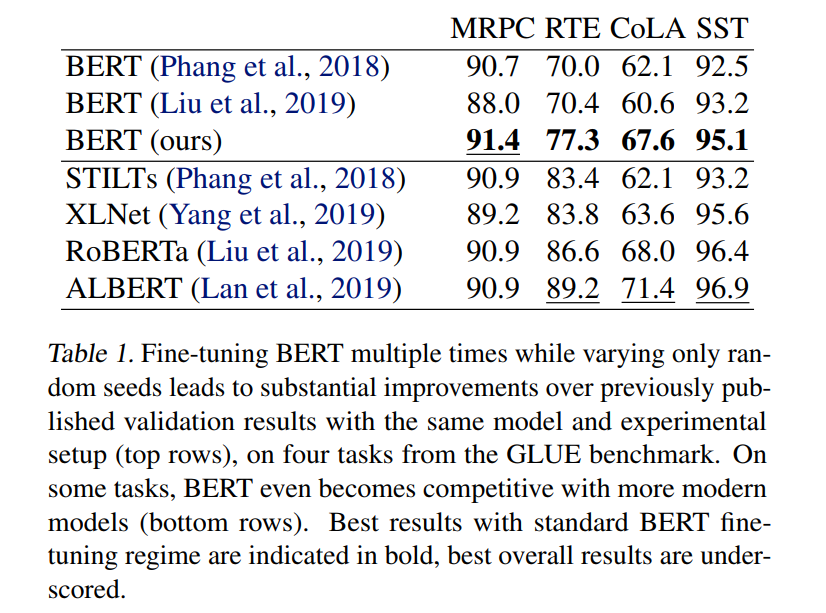
为此,我们想知道有哪些因素会导致模型最终效果的巨大不确定性。本文研究了两个因素:(微调的)参数初始化和数据的训练顺序。结果表明,不同的初始化和不同的训练顺序会导致最后在具体任务上效果的差异。为此,本文提出使用early stopping的策略,降低搜索最佳模型的训练开销。
总的来说,本文贡献如下:
- 本文表明,微调阶段的不同的随机数种子会导致最终结果的巨大差异;
- 权重初始化和数据的训练顺序是影响差异的因素之一;
- 使用early stopping的方法可以减少训练开销。
方法
为了探究微调阶段对最终结果的影响,本文在四个分类数据集上实验:MRPC,RTE,CoLA和SST。前三个比较小,SST比较大。
所有的实验都基于预训练好的BERT,每次微调都运行三个epoch。微调的参数既包括BERT主体,即原来预训练的部分,也包括最后一层分类层(下称这一层为“微调层”)。微调层都按照标准正态分布采样初始化。
对每一个随机数,它都会产生一个对应的微调层初始化和数据的训练顺序,所以,对个不同的随机数,一共有个不同的组合。本文设。
为了量化随机数种子对最终结果的影响,本文采取了“期望验证集效果”的方法。简单来说,就是多次实验中在验证集上取得最好的结果的期望值。
随机数种子的影响
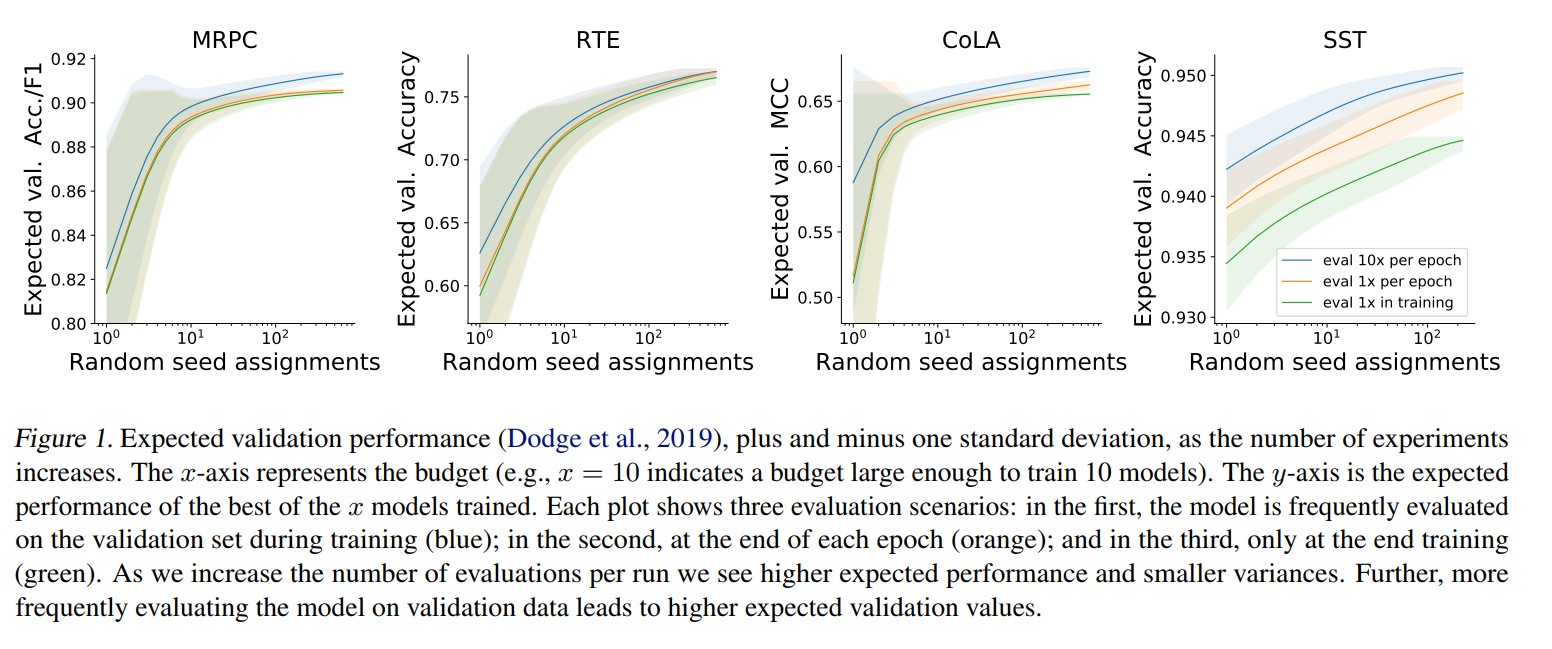
首先来看看总体随机数种子的影响。下图是期望效果随着试验次数增加(每次实验的种子都不同)的变化曲线。可以看到,随着实验次数的增加,模型总的效果是不断上升的,而且,在试验次数较少的时候,模型效果的方差特别大,后来渐渐变小。绿色的线是在三轮结束后再测评,橙色的是每一轮都测评一次,而蓝色是每一轮测评十次。这三者都具有相同的增长模式。这就说明了不同的随机数种子的确会导致迥然不同的效果差异。
权重初始化和训练顺序的影响
随机数种子的改变会影响什么的变化呢?因为模型预训练部分的参数是不变的、超参数是不变的,那么最明显的改变就是微调层参数的初始化值,和数据训练的顺序(因为在微调之前一般需要shuffle,这涉及到随机数种子)了。我们可以猜想,这二者是导致模型效果差异的因素。
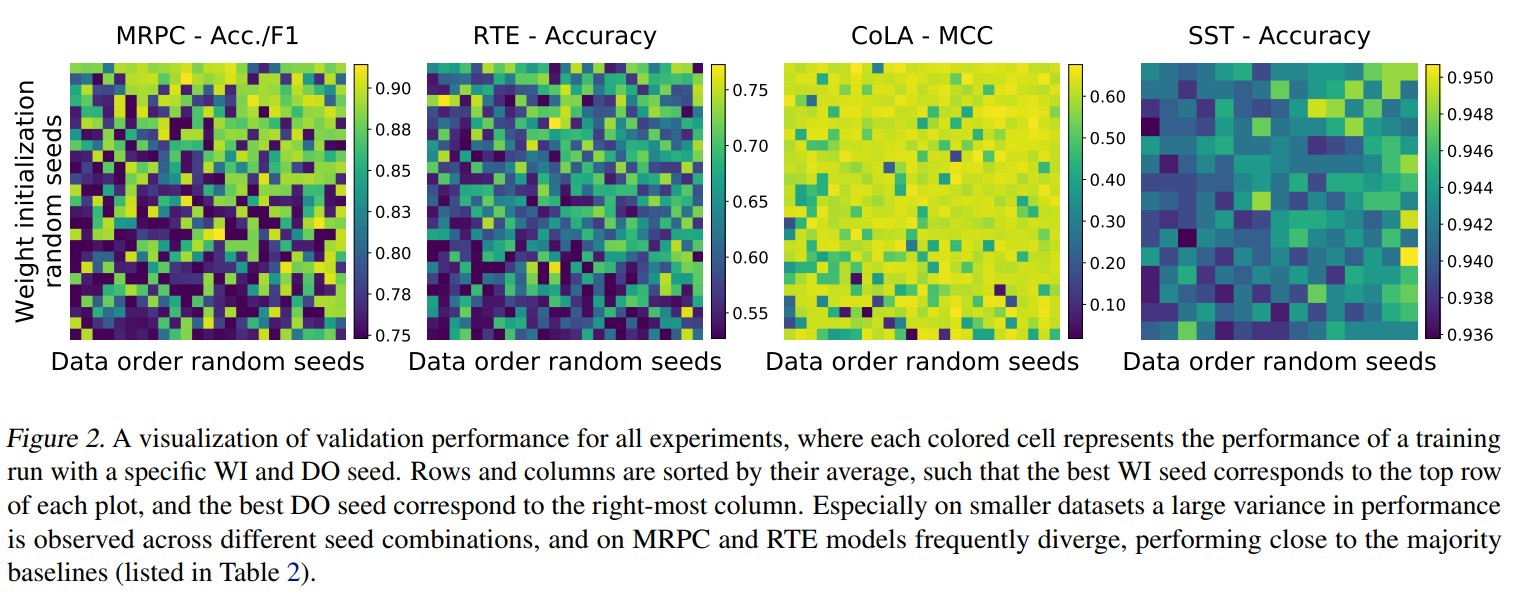
下面首先来看二者对结果的影响,如下图所示。横轴是不同的训练顺序,纵轴是不同的参数初始化值。可以看到,在四个数据集上,最后效果的差异都非常大,这说明不同随机种子导致的不同的参数初始化、不同的训练顺序对结果的方差是比较大的。而且,就算是同一个种子,在不同的数据集上表现也有可能不一样。
那么,有没有一些种子,它产生的初始化参数和训练顺序在所有数据集上都有比较好的效果呢?下图画出了实现最好(坏)效果的参数初始化和训练顺序的种子的核密度估计。可以看到,那些表现好的种子分布比较集中,在四个数据集上都能实现比较好的效果;而表现差的种子在各个数据集上表现不一,有好有坏,而且结果的方差也更大。这说明,的确存在一些种子,它能产生在四个数据集上都表现较好的初始化参数和训练顺序。

使用early stopping减少训练开销
那么一个问题是,一定要等到训练结束之后才能判断当前模型产生的结果是好是坏吗?一个简单的想法是,我们可以提前结束那些在一开始就表现不好的模型。
但是,一开始表现不好的模型不一定就意味着它在训练结束的时候也表现不好,我们需要知道它们有多大的相关性,如下图所示。可以看到,大多数一开始就坏掉的模型有极大可能在最后也无法收敛,而一开始就不错的模型很有可能会收敛,那么,这就启示我们一开始就停掉那些表现不好的模型

那么,怎么去提前终止呢?本文给出的方法是:首先同时跑个模型,然后训练到总体的的时候(比如),分别评估这个模型的效果,保留其中个最好的,丢掉其他的。这个算法的总体运行开销是,是训练一个完整模型的开销,其相对完整训练所有模型的开销是
从而,若越小,即选择继续训练的模型数越小,其训练开销就越小。
实验表明,在同样的计算资源预算下,使用提前终止方法可以有效提高最好模型的结果,或者说提高了训练找到最好模型的效率。
小结
本文从一个预训练模型普遍存在的现象出发——微调阶段产生的结果方差很大,研究预训练模型BERT对随机数种子的敏感程度。大量实验表明,预训练模型,至少BERT的最终结果非常容易受到随机数种子的影响。而随机数种子影响最明显的就是微调层的参数初始化和数据的训练数据,因此,参数初始化和训练顺序是影响模型最终结果比较重要的因素。本文还提出了一种简单的提前终止的方法,用于减少无谓的训练开销,更快寻找最佳模型(随机数种子)。
思考讨论
你认为健壮的模型应该是怎样的?它应该对随机数种子非常敏感吗?如果大规模调整随机数种子来找到表现(验证集上)最好的模型,这是不是一种“拟合随机数”?
见仁见智。笔者认为健壮的模型不应该是对随机数种子如此敏感的,单从本文的论述和方法上讲,有“拟合随机数”的嫌疑,或者说BERT在健壮性上是有缺陷的。
你认为导致微调阶段模型对随机数种子敏感的原因有哪些?
笔者认为,可以把预训练想象成一个搭积木的过程,这个过程就是把积木搭得比较高但是有些错落;而微调就是继续在这之上搭积木,如果一开始搭得太歪,就会导致积木垮塌,而放的位置比较好,就可以保持平衡。那么,随机种子的作用就是给你一样放积木的起点,它对结果的影响(平衡或崩塌)可以从三个方面解释:(1)基底不够稳定(健壮),也就是预训练结果不够稳定;(2)随机放置的方差太大,也就是初始化的方差太大,需要调整初始化策略;(3)先预训练后微调的方法不够健壮