预训练模型在捕捉深度语境表征方面的成功是有目共睹的。本文提出一个面向中文NLU任务的模型,名为NEZHA(NEural contextualiZed representation for CHinese lAnguage understanding,面向中文理解的神经语境表征模型,哪吒)。NEZHA相较于BERT有如下改进:
- 函数式相对位置编码
- 全词覆盖
- 混合精度训练
- 训练过程中使用 LAMB 优化器
前两者是模型改进,后两者是训练优化。
NEZHA在以下数个中文自然处理任务上取得了SOTA的结果:
- 命名实体识别(人民日报NER数据集)
- 句子相似匹配(LCQMC,口语化描述的语义相似度匹配)
- 中文情感分类(ChnSenti)
- 中文自然语言推断(XNLI)
介绍
预训练模型大部分是基于英文语料(BooksCorpus和English Wikipedia),中文的预训练模型目前现有如下几个:Google的中文BERT(只有base版)、ERNIE-Baidu、BERT-WWM(科大讯飞)。这些模型都是基于Transformer,且在遮蔽语言模型(MLM)和下一句预测(NSP)这两个无监督任务上进行预训练。这些中文模型之间主要差别在于MLM中使用的词遮蔽策略。Google的中文版BERT独立地遮蔽掉每个汉字或WordPiece token。ERNIE-Baidu在MLM中进一步将实体或者短语视为一个整体,如此一个实体或短语包含多个汉字。BERT-WWM的策略相似,称为全词覆盖(Whole Word Masking,WWM)。WWM强制要求所有属于同一中文词的字都要一起被覆盖掉。ERNIE-Baidu 2.0则又额外引入了其他预训练任务,如Token-Document关系预测和句子重排任务。
本文提出的NEZHA整体上是基于BERT的改进。在NEZHA中使用的是函数式相对位置编码,而在原始的Transformer和BERT中每个词使用的是绝对位置编码。位置编码信息直接加到词嵌入作为Transformer的输入。位置编码一般有2种方式:
- 函数式编码。通过预定义函数(如正弦函数)直接给出位置编码。
- 参数式编码。此时的位置编码作为模型参数的一部分,通过学习得到。
参数式位置编码涉及两个概念,一个是距离,表示这个词离“我”有多远,另一个是维度,Word Embedding一般有几百维,比如512维,每一维有一个值,通过位置和维度两个参数来确定一个位置编码的值。
在BERT模型预训练时,很多数据的真实数据长度达不到最大长度,因此靠后位置的位置向量训练的次数要比靠前位置的位置向量的次数少,造成靠后的参数位置编码学习的不够。在计算当前位置的向量的时候,应该考虑与它相互依赖的token之间相对位置关系,可以更好地学习到信息之间的交互传递。
本文的NEZHA使用函数式相对位置编码,通过预定义函数的方式在自注意力层编码相对位置。实验结果表明,该方法是一种有效的位置编码方案,并在实验中取得了一致的效果。此外,NEZHA在训练过程中使用了三种已被证明是有效的预训练BERT技术,即全词覆盖,混合精度训练和LAMB优化。
NEZHA 模型
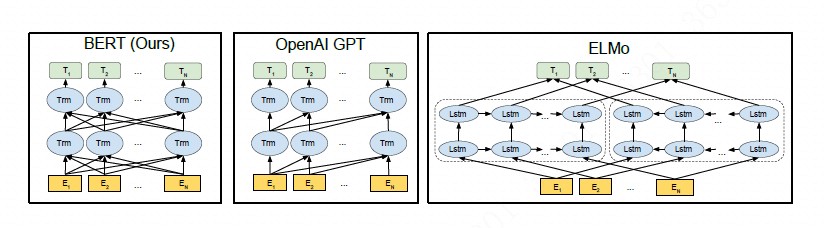
由于NEZHA也是基于BERT,所以关于Transformer和BERT的详情请直接阅读原始论文。在此不赘述。
函数式相对位置编码
在Transformer 中,每个词之间互相都要Attending,并不知道每个词离自己的距离有多远,这样把每个词平等的对待,是会有问题的。
NEZHA中的函数式相对位置编码,通过使用相对位置的正弦函数计算输出和attention的得分。该想法源于Transformer中使用的函数式绝对位置编码。在本文的模型中,和都是正弦函数,且在训练过程固定不变。为了简化起见,直接将和简写为,维度为和的 分别如下:
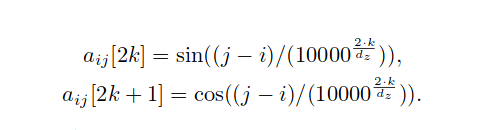
位置i和位置j的相对位置编码由2部分组成,维度为2k和2k+1。假设 ,那么k的取值从0,1,255。由此可以看出,位置编码的每个维度都由正弦函数决定。不同维度(即不同)的正弦函数会有不同的波长。上述公式中,表示NEZHA模型的每个head的隐含层大小。波长是一个从到的几何级数。选择固定正弦函数,可以使该模型具有更强的扩展性;即当它遇到比训练中序列长度更长的序列时,依然可以发挥作用。
全词覆盖
在初始的BERT中,每个token或者每个汉字都是随机覆盖的。而 NEZHA 预训练模型,则采用了全词覆盖(WWM)策略,当一个汉字被覆盖时,属于同一个汉字的其他汉字都被一起覆盖。该策略被证明比 BERT 中的随机覆盖训练(即每个符号或汉字都被随机屏蔽)更有效。在 NEZHA 的 WWM 实现中,使用了一个Jieba进行中文分词。在 WWM 训练数据中,每个样本包含多个覆盖汉字,覆盖汉字的总数约占其长度的 12%,随机替换的占 1.5%。尽管这样预测整个词运算难度有所增加,但最终取得的效果更好。
混合精度训练和LAMB优化器
在 NEZHA 模型的预训练中采用了混合精度训练技术。该技术可以使训练速度提高2-3倍,同时也减少模型的空间占用,从而可以利用较大的batch size。
传统的深度神经网络训练使用 FP32 (即单精度浮点格式)来表示训练中涉及的所有变量(包括模型参数和梯度);而混合精度训练在训练中采用了多精度。具体来说,它重点维持模型中权重的单精度副本(称为主权重),即在每次训练迭代中,将主权重舍入为FP16(即半精度浮点格式),并使用 FP16 格式存储的权重、激活和梯度执行向前和向后传递;最后将梯度转换为FP32格式,并使用FP32梯度更新主权重。
LAMB 优化器是专为深度神经元网络大batch size同时分布式训练而设计。尽管使用大的batch size训练可以有效地加快 DNN 训练速度,但是如果不仔细调整学习率,当batch size处理的大小超过某个阈值时,模型的性能可能会受到很大影响。LAMB 优化器则不需要手动调整学习率,而是采用了一种通用的自适应策略。优化器通过使用非常大的batch size(实验中高达 30k 以上)来加速BERT的训练,而不会导致性能损失,甚至在许多任务中获得最先进的性能。值得注意的是,BERT的训练时间最终从3天显著缩短到 76 分钟。
实验结果
预训练
NEZHA预训练数据集:
- Chinese Wikipedia
- Baidu Baike
- Chinese News
Table 1 统计了各个预训练模型使用到的数据集情况:
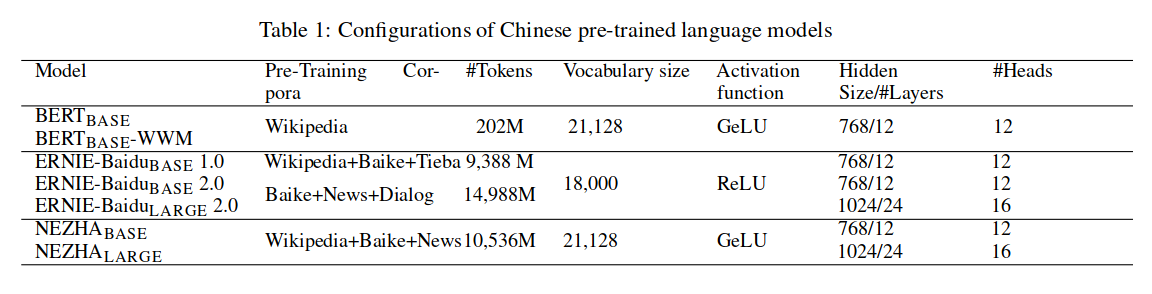
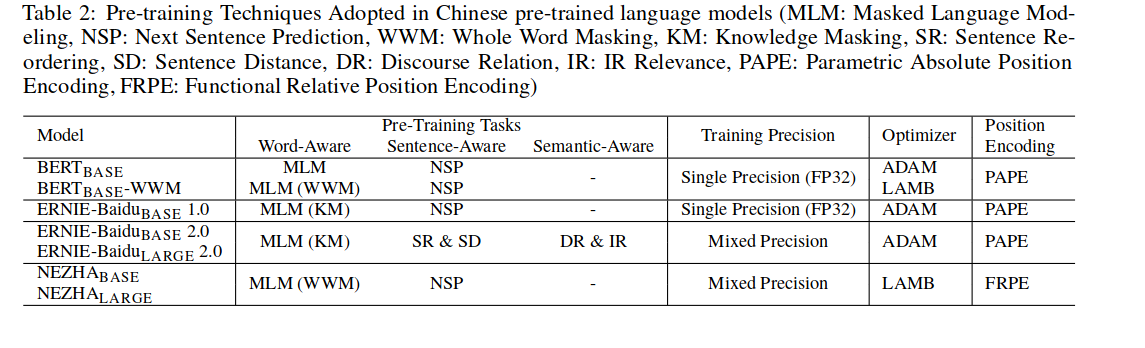
Table 2 展示了现有中文预训练模型中用到的预训练技巧:
实验结果
评测数据集:CMRC(中文阅读理解2018)、XNLI(跨语言自然语言推理)、LCQMC(大规模中文问题匹配语料)、PD-NER(人民日报命名实体实体数据集)、ChnSenti(中文情感分类数据集)
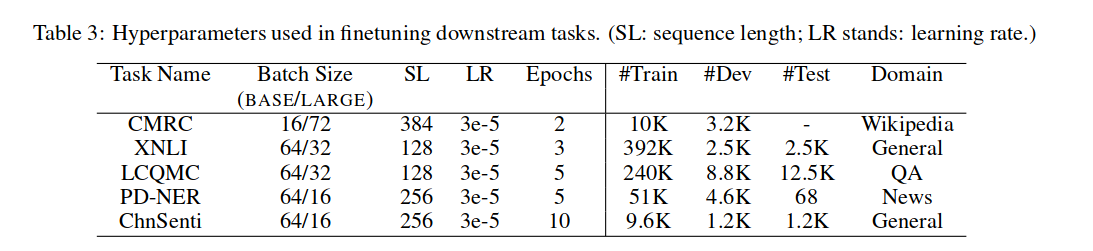
NEZHA在各个数据集finetuning的超参数如 Table 3:
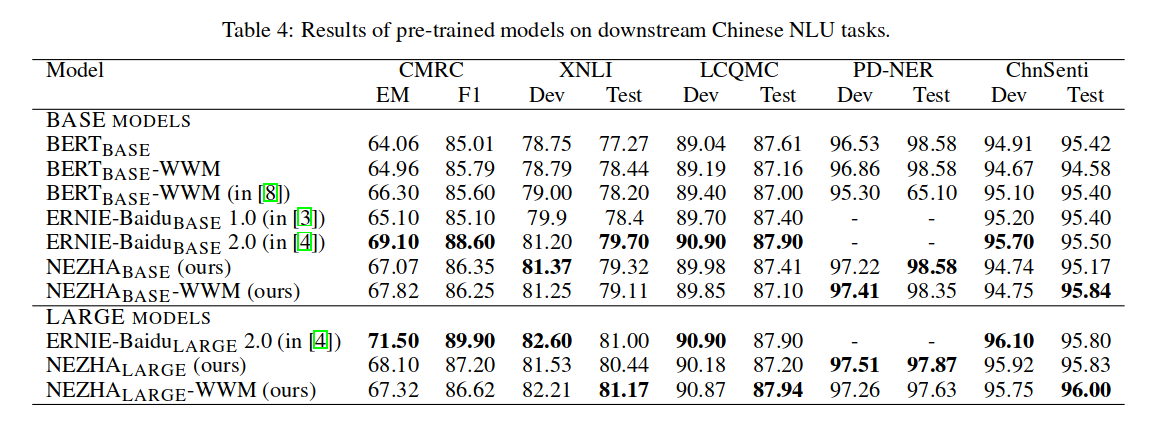
各个预训练模型在各个数据集上的评测结果如 Table 4 所示:
此外还对NEZHA模型中的位置编码、遮蔽策略、训练序列长度和训练语料进行消融研究。消融研究结果如 Table 5 所示:

从消融研究的实验结果可以看出,上述因素都能够促进下游任务性能的提升。对比函数式相对位置编码、参数式绝对位置编码和参数式相对位置编码,可以看出函数式相对位置编码显著优于其他位置编码方式。在CMRC任务中可以看出,相较于相对位置编码使用绝对位置编码真是弱爆了。
总结
本文提出一个基于中文语料的大规模预训练模型:NEZHA。其中最为重要的贡献在于使用了函数式相对位置编码,该方法显著优于其他位置编码方式。另外,NEZHA模型也集成了几项先进技术:全词覆盖、混合精度训练和LAMB优化器。NEZHA在数个中文自然语言理解任务中取得SOTA结果。
论文地址: https://arxiv.org/abs/1909.00204
华为官方源码: https://github.com/huawei-noah/Pretrained-Language-Model
Pytorch版本权重:https://github.com/lonePatient/NeZha_Chinese_PyTorch