部署产品级的深度学习模型充满挑战,其难度远远超过训练一个性能不俗的模型。为了部署一个产品级的深度学习系统,还需要设计和开发以下几个部分(见下图):
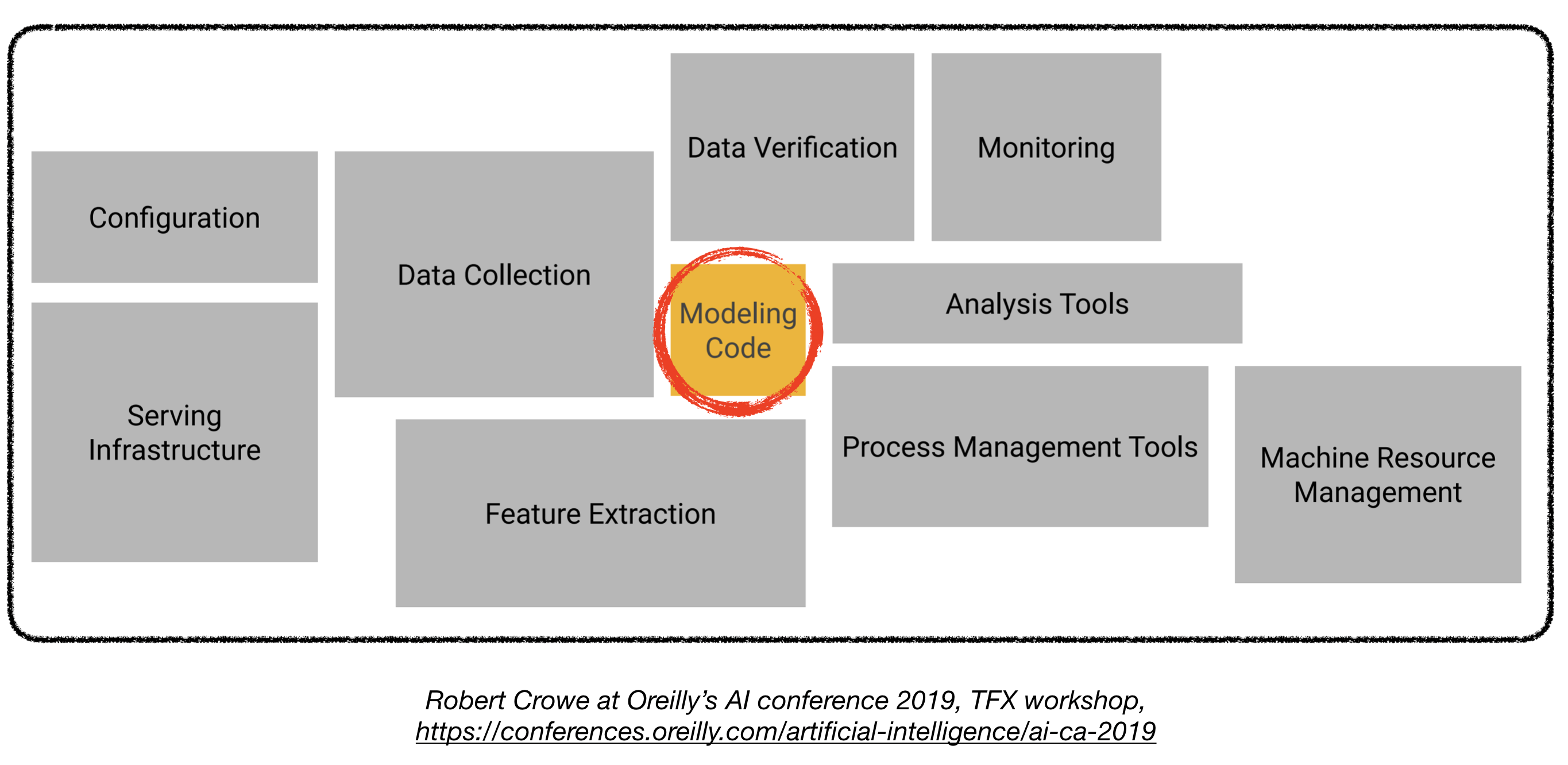
本文可以作为一篇工程指南去构建一个产品级的深度学习系统,并且该系统可以部署在真实的生产环境中。
本文借鉴了如下文章:
Full Stack Deep Learning Bootcamp (by Pieter Abbeel at UC Berkeley, Josh Tobin at OpenAI, and Sergey Karayev at Turnitin), TFX workshop by Robert Crowe, and Pipeline.ai’s Advanced KubeFlow Meetup by Chris Fregly.
Machine Learning Projects 机器学习项目
[译者注]原作者在文中既使用了Mechine Learning(机器学习),又使用了Deep Learning(深度学习,大部分工具可以两者都适用)
有趣的真相 :flushed: fact: 85%的AI项目会失败. 1 潜在的原因如下:
- 技术上不可行,或者无法广泛应用
- 没能转化为产品
- 不清晰的成功标准或指标
- 糟糕的团队管理
1. ML Projects lifecycle 机器学习项目的生命周期
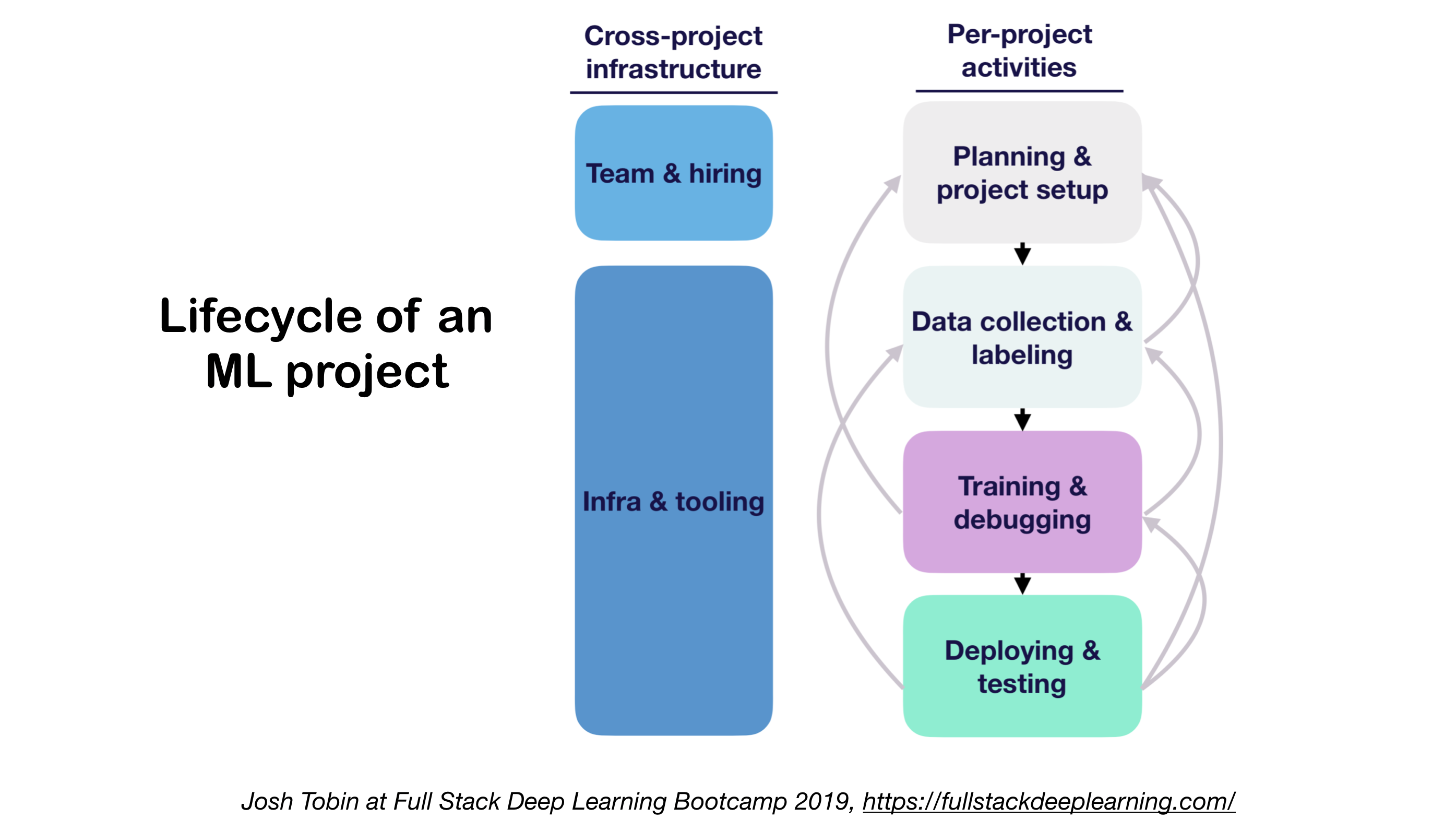
- 了解你所在领域的技术现状的重要性:
- 可以知道什么是可能可以实现的
- 可以知道下一步尝试的方向
2. Mental Model for ML project 机器学习项目的心智模型
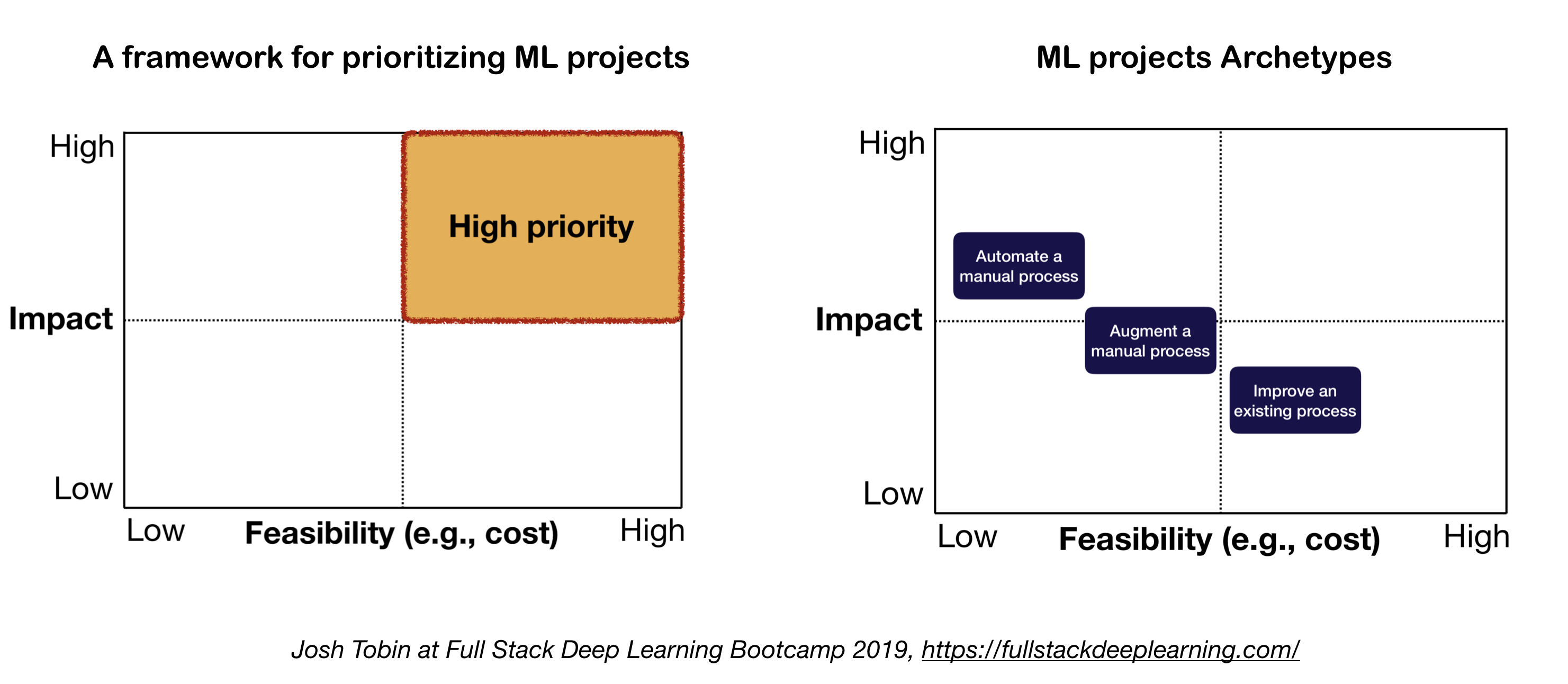
当对机器学习项目的重要性和紧急性排序时,需要考虑两个重要的因素:
- 高收益:
- 工作流中的复杂部分
- 快速进行”廉价预测“(小的数据量,标签,计算量情况下,得到小模型进行简单的预测,能给工作开个好头)
- 将复杂的手动处理过程进行自动化很有用
- 低成本:
- 成本主要由以下几部分决定:
- 获得有效的数据
- 高性能需求:成本随着精确度要求超线性增长
- 问题的难度:
- 一些高难度的问题包括:非监督学习,增强学习,某些类别的监督学习
- 成本主要由以下几部分决定:
Full stack pipeline 全栈流水线
下图高度概括了产品级深度学习系统相关的各个不同的组成模块:
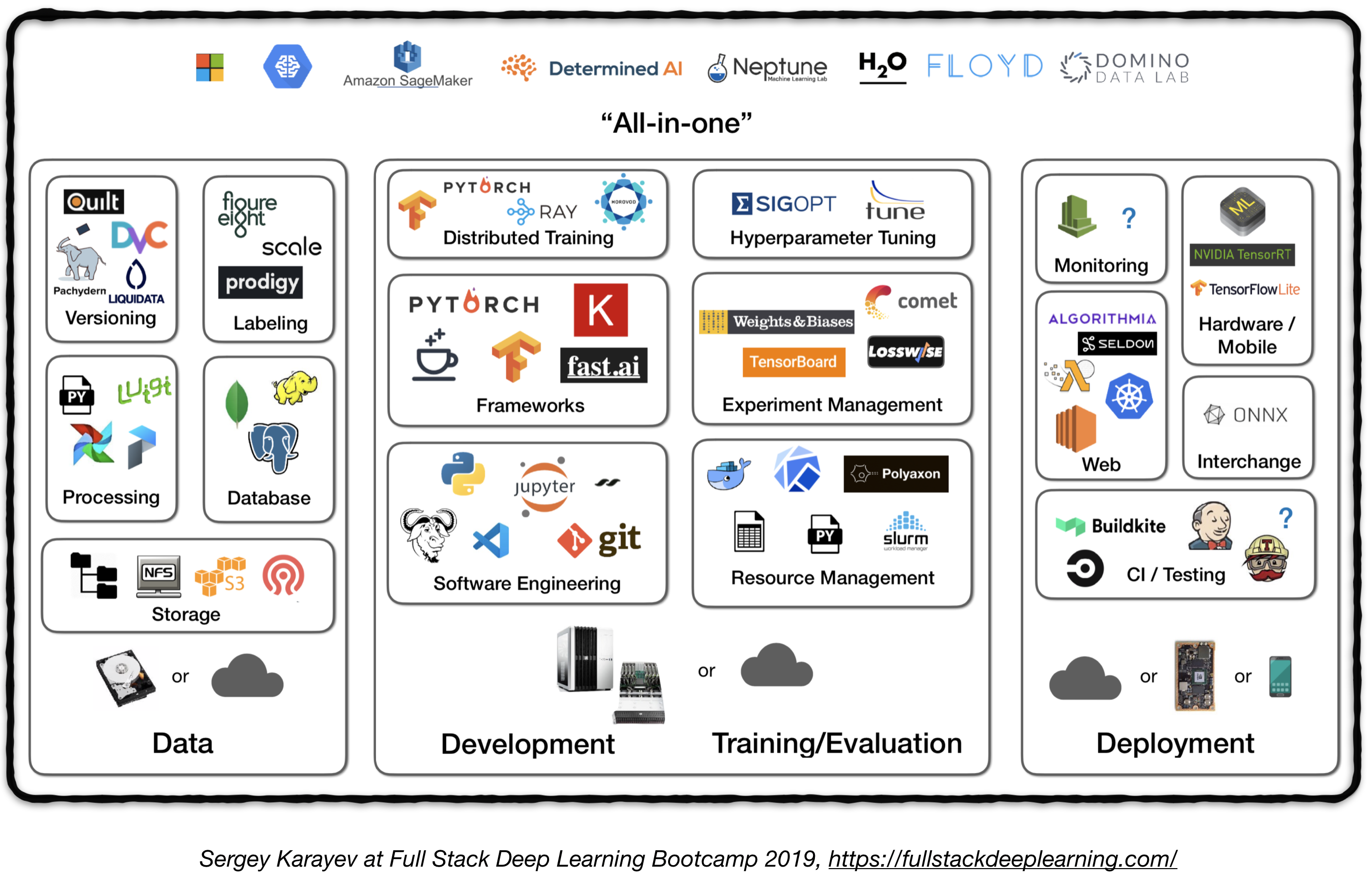
接下来,我们将会讲解每一个模块,以及从实践者出发推荐的适合该模块的工具集和框架。
1. Data Management 数据管理
1.1 Data Sources 数据来源
- 监督深度学习需要大量的打标签数据
- 对自己的数据打标签是很昂贵的!
- 下面是一些可供选择的数据来源:
- 开源数据(适合入门,但不适合进阶)
- 数据增强(对于机器视觉是必选,对于NLP可选)
- 合成数据(入门首选,尤其是NLP领域)
1.2 Data Labeling 数据标记
- 要求:独立的软件栈(标签平台),临时工,以及质量控制
- 人工打标签:
- 众包:便宜,可扩展,可靠性较差,需要质量控制
- 招聘数据标记人员:质量较好,昂贵,扩展很慢
- 数据标记服务公司:
- 标记平台:
1.3. Data Storage 数据存储
- 可供选择的数据存储方案有:
- 对象存储: 存储二进制数据(图片,声音文件,压缩的文本)
- 数据库: 存储元数据(文件路径,标签,用户行为等).
- Postgres Postgresql对于大多数应用来说是正确的选择,它有着一流的SQL语言支持,以及对非结构化JSON格式的最佳支持。
- 数据湖: 用以聚合无法从数据库获得的特征(比如日志数据)
- 特征存储: 存储,访问,以及分享机器学习的特征
(特征提取的计算成本很高,并且几乎无法扩展,因此能够在不同模型和团队之间复用特征是提高效能的关键)。- FEAST (Google cloud, 开源)
- Michelangelo Palette (Uber)
- 建议: 在训练阶段,复制数据到本地文件系统或者NFS。 1
1.4. Data Versioning 数据版本管理
- 对于已部署的机器学习模型,“必须”有其对应的训练数据版本:
已部署的机器学习模型,由数据和代码共同组成. 1 没有数据版本的管理,就意味着没有模型版本的管理。 - 数据版本管理平台:
1.5. Data Processing 数据处理工作流
- 对于模型的训练数据可能来自于不同的数据源,包括:存储在数据库的数据, 包括 存储在数据库的数据, 日志数据, 和其他分类模型的输出.
- 在任务和任务之间有依赖,一个任务的开启需要另外一个任务的完结。比如,在一个新的日志数据上训练任务,必须在某个预处理流程之后进行。
- Makefiles用来完成此工作比较流缺乏伸缩性,在这个场景下,工作流管理工具十分重要。
- 工作流编排:
2. Development, Training, and Evaluation 开发,训练,模型评估
2.1. Software engineering 软件工程
- 编程语言大赢家:Python
- 编辑器:
- 电脑建议 1:
- 针对个人开发者或者创业公司
- 模型开发:一台4块图灵架构GPU的PC(目前图灵架构的GPU有RTX2080Ti(本文主要指这款),Tesla T4(企业数据中心使用,搭载在服务器),Quodro RTX5/6/8000(多用于图形渲染工作站))
- 训练/评估:使用同样的4卡GPU的PC, 当运行很多任务时,也可以使用共享计算资源或者使用云服务。
- 对于大公司:
- 开发:为每位机器学习科学及购买一台4卡图灵架构的PC,或者给他们上V100的机器。
- 训练/评估:使用云服务,有充分的资源供应和故障处理
- 针对个人开发者或者创业公司
- 使用云服务:
- GCP: 可以选择将任何实例运行在GPU上,并且有TPU资源
- AWS:
2.2. Resource Management 资源管理
- 给程序分配任意的计算资源
- 如果选择计算资源管理,有如下选项:
2.3. DL Frameworks 深度学习框架
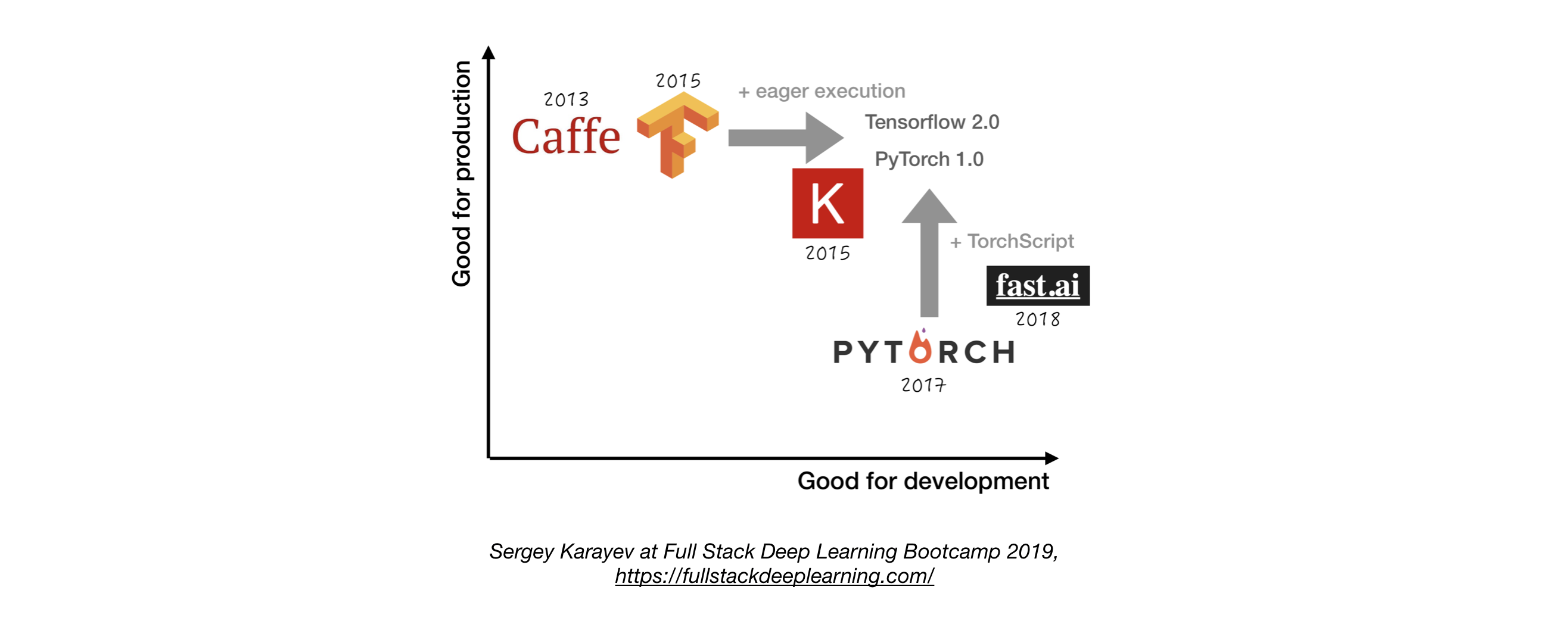
- 除非有着充分的理由,否则建议使用Tensorflow/Keras或者Pytorch. 1
- 下图基于*“易开发性”和“产品表现”*两个维度,展示了不同的深度学习框架对比图。
2.4. Experiment management 实验管理
- 开发,训练,以及评估策略:
- 以简单的方法快速开始
- 以小批量数据训练一个小的模型,如果有效果,扩展到更大的数据和模型,以及进行超参数调优。
- 实验管理工具:
- Tensorboard
- 提供可视化以及机器学习实验相关的工具
- Losswise (可以对机器学习进行监控)
- Comet: 可以追踪代码,实验,以及机器学习项目的结果
- Weights & Biases: 记录和可视化你与同事协同研究中的所有细节
- MLFlow Tracking: 记录参数,代码版本,指标,输出文件,以及结果的可视化
- 在python中用一行代码进行自动化的实验追踪
- 实验之间的比对
- 超参调优
- 支持K8S
- 以简单的方法快速开始
2.5. Hyperparameter Tuning 超参调优
- 策略
- 网格搜索
- 随机搜索
- 贝叶斯优化
- HyperBand (以及ASHA,Asynchronous Successive Halving Algorithm 异步减半算法)
[译者注]Hyperband算法对 Jamieson & Talwlkar(2015)提出的SuccessiveHalving算法做了扩展。SuccessiveHalving算法:假设有nn组超参数组合,然后对这nn组超参数均匀地分配预算并进行验证评估,根据验证结果淘汰一半表现差的超参数组,然后重复迭代上述过程直到找到最终的一个最优超参数组合。
* Population-based Training(兼顾并行调优和串行调优)
- Platforms:
超参调优平台- RayTune: RayTune是一个Python库,能够在任何规模下进行超参调优(主要专注深度学习和增强学习)。支持几乎任何机器学习框架,包括PyTorch, XGBoost, MXNet, 和Keras等.
- Katib: 针对超参调优和神经网络架构搜索的K8S原生系统, 受这篇论文启发 [Google vizier](https://static.googleusercontent.com/media/ research.google.com/ja//pubs/archive/ bcb15507f4b52991a0783013df4222240e942381.pdf),并且支持多种机器学习框架(比如Tensorflow, MXNet,和PyTorch)
- Hyperas: 基于hyperopt的简单封装, 针对keras的,通过模板参数填写来定义超参范围,并进行调优。
- SIGOPT: 可扩展的,企业级的优化平台
- Sweeps from [Weights & Biases] (https://www.wandb.com/): 参数不需要开发人员显式地指定,一开始只有大概的范围,然后通过机器学习模型来学习而确定。
- Keras Tuner: 针对keras的超参调优工具,适合于基于Tensorflow2.0的tf.keras
2.6. Distributed Training 分布式训练
-
数据并行:当迭代时间很长时,使用这种方案(tensorflow和PyTorch都支持)
-
模型并行:当模型不适合于单个GPU时,使用这个方案
-
其他方案:
- Horovod
[译者注]由于 TensorFlow 集群太不友好,业内也一直在尝试新的集群方案。
2017 年 Facebook 发布了《Accurate, large minibatch SGD: Training ImageNet in 1 hour 》验证了大数据并行的高效性,同年百度发表了《Bringing HPC techniques to deep learning 》,验证了全新的梯度同步和权值更新算法的可行性。受这两篇论文的启发,Uber 开发了 Horovod 集群方案。
3. Troubleshooting [TBD]排错[待完成]
4. Testing and Deployment 测试和部署
4.1. Testing and CI/CD 测试以及CI/CD
比起传统的软件,机器学习产品软件需要更多样的测试工具:
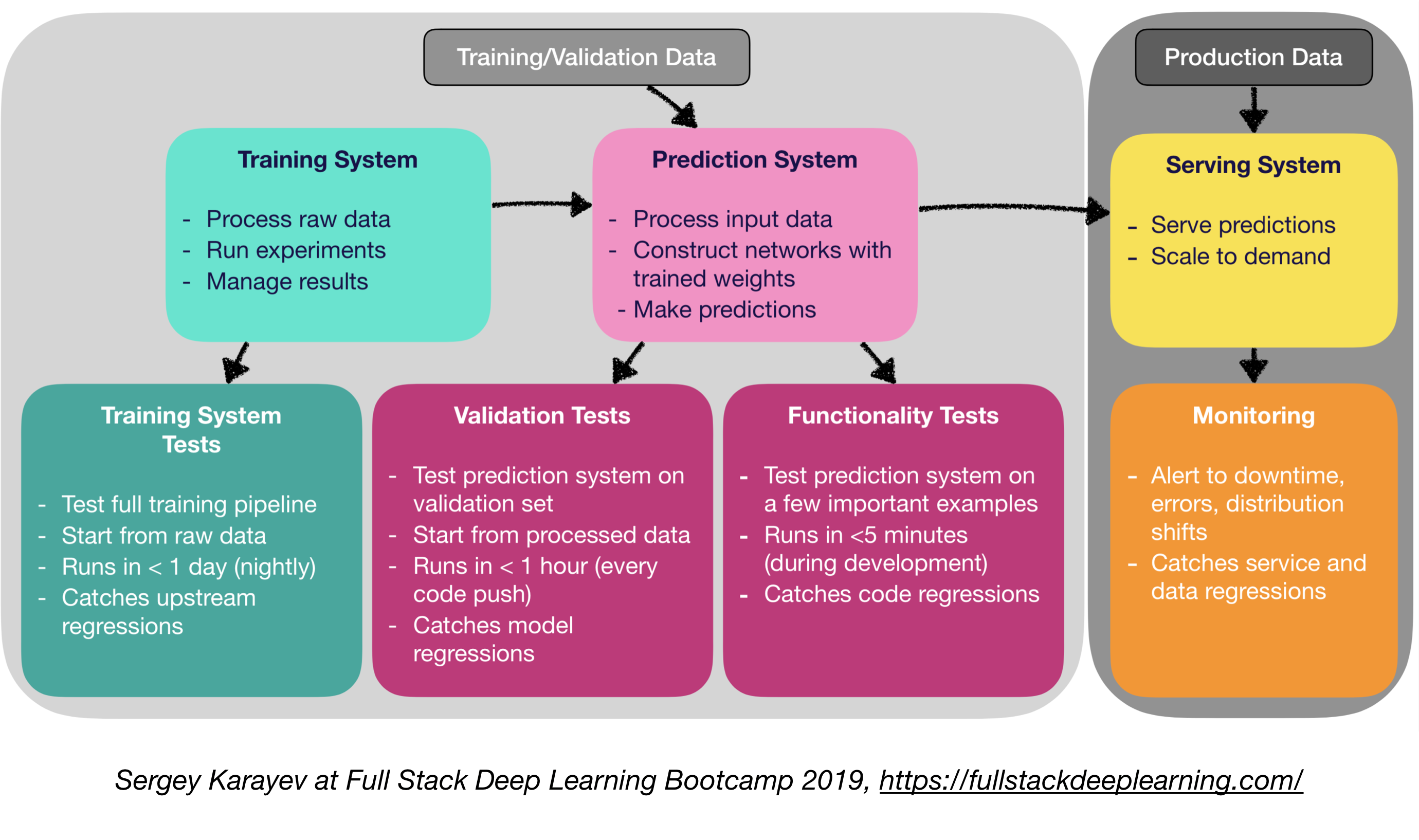
- 单元测试和集成测试
- 测试类型
- 训练系统测试:测试训练流水线
- 验证测试:在验证数据集上测试预测系统
- 功能测试:在不那么重要的场景里使用预测系统
- 测试类型
- 持续集成:当有代码更新时就自动推送到仓库里并进行测试
- 针对持续集成的SaaS服务
4.2. Web Depolyment Web部署
-
由预测系统和服务系统组成
- 预测系统:程序输入数据,产生预测的结果
- 服务系统(Web服务):
- 在一定规模下提供预测
- 使用REST API提供预测服务
- 调用预测系统进行实际的计算
-
服务的类型:
-
- 部署在虚拟机上,通过增加节点扩容
-
- 以容器形式部署,通过编排扩容
- 容器技术
- Docker
- 容器编排
- K8S(当前最流行)
- MESOS
- Marathon
-
- 部署代码为 “serverless function”
-
- 通过模型服务方案来实现
-
-
模型服务:
- 特质针对机器学习模型的web服务部署
- 批量请求通过GPU来做计算
- 框架:
- Tensorflow serving
- MXNet Model server
- Clipper (Berkeley)
- SaaS solutions
SaaS的解决方案- Seldon: 可以基于K8S对任何框架提供“模型服务”和扩容
- Algorithmia
-
计算资源选择:CPU还是GPU?
- CPU推理:
- 如果满足要求,最好使用CPU进行推理
- 通过增加服务器,或者微服务模式来进行扩容
- GPU推理
- TF serving or Clipper
- 在批量进行推理的场景中很有用
- CPU推理:
-
(Bonus) 部署Jupyter Notebooks:
- Kubeflow Fairing 一个混合部署的工具包,可以让你部署你的Jupyter Notebooks代码
4.5 Service Mesh and Traffic Routing 服务网格和流量路由
- 从单机程序过渡到分布式微服务架构具有较大的挑战
- A Service mesh (由微服务和网格组成)减少了此类部署的复杂性,并降低了团队的工作量。
- Istio: 一种服务网格,通过负载均衡,服务间认证,监控来创建服务的网络,业务本身的代码只需要做很少的改动,或者不需要改动。
4.6. Monitoring 监控:
- 监控的目的:
- 停机,错误,漂移时发出告警
- 捕获服务以及数据回归
- 可选择云供应商方案
- Kiali: 能够可视化管理Istio,能够回答以下问题:微服务之间如何连接,它们性能如何?
Are we done?

4.7. Deploying on Embedded and Mobile Devices 部署在嵌入式和移动设备上
-
主要的挑战:内存占用和算力限制
-
解决方案:
- 模型量化
[译者注]Quantization模型量化即以较低的推理精度损失将连续取值(或者大量可能的离散取值)的浮点型模型权重或流经模型的张量数据定点近似(通常为int8)为有限多个(或较少的)离散值的过程,它是以更少位数的数据类型用于近似表示32位有限范围浮点型数据的过程,而模型的输入输出依然是浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。
- 减少模型的尺寸
- MobileNets
- 知识蒸馏
[译者注]Knowledge Distillation知识蒸馏(KD)是想将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,一般来说,teacher具有强大的能力和表现,而student则更为紧凑。通过知识蒸馏,希望student能尽可能逼近亦或是超过teacher,从而用更少的复杂度来获得类似的预测效果。Hinton在Distilling the Knowledge in a Neural Network中首次提出了知识蒸馏的概念,通过引入teacher的软目标(soft targets)以诱导学生网络的训练。
···* DistillBERT (for NLP) -
针对嵌入式和移动设备的框架:
- Tensorflow Lite
- PyTorch Mobile
- Core ML
- ML Kit
- FRITZ
- OpenVINO
-
模型转换:
- Open Neural Network Exchange (ONNX): 针对深度学习模型的开源格式化技术
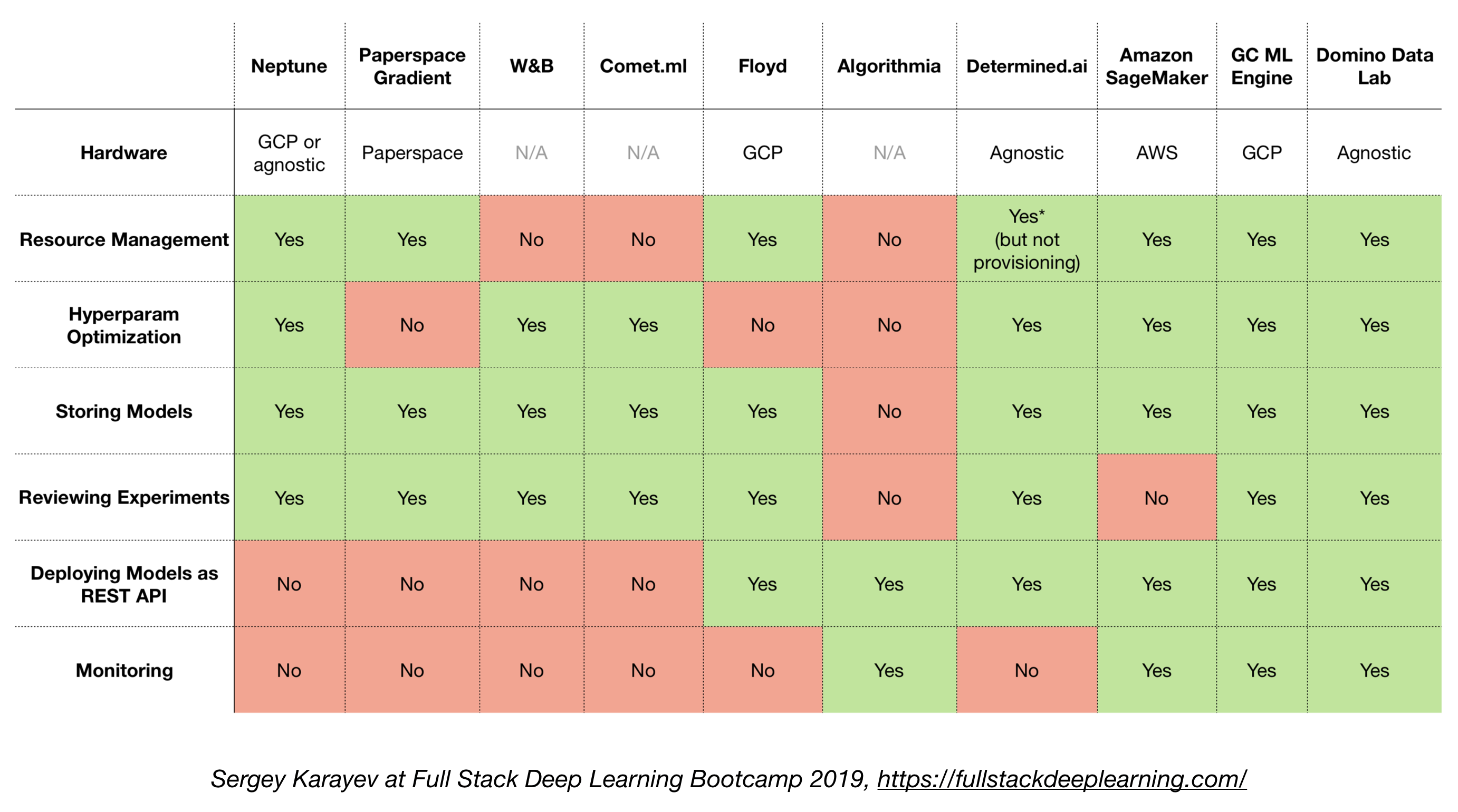
4.8. All-in-one solutions 一站式解决方案
- Tensorflow Extended (TFX)
- Michelangelo (Uber)
- Google Cloud AI Platform
- Amazon SageMaker
- Neptune
- FLOYD
- Paperspace
- Determined AI
- Domino data lab
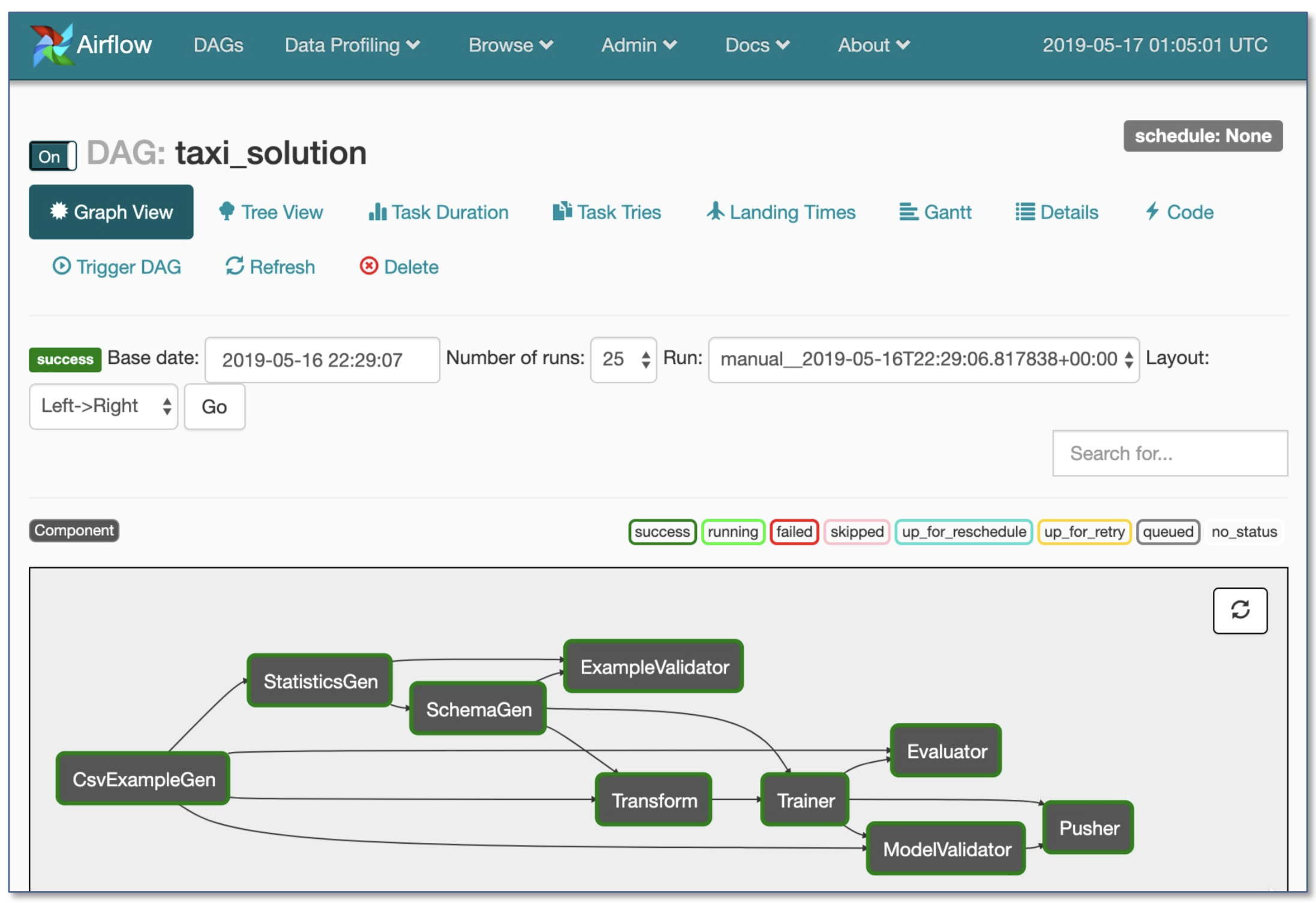
Tensorflow Extended (TFX) [TBD][待补充]
[译者注]tfx是构建在tf基础之上的一个包含了机器学习整个生命周期的完整系统,这个系统不只包含了tf所提供的模型训练等机器学习相关功能,还提供了如数据校验和验证、模型热启动、线上服务、模型发布等重要功能
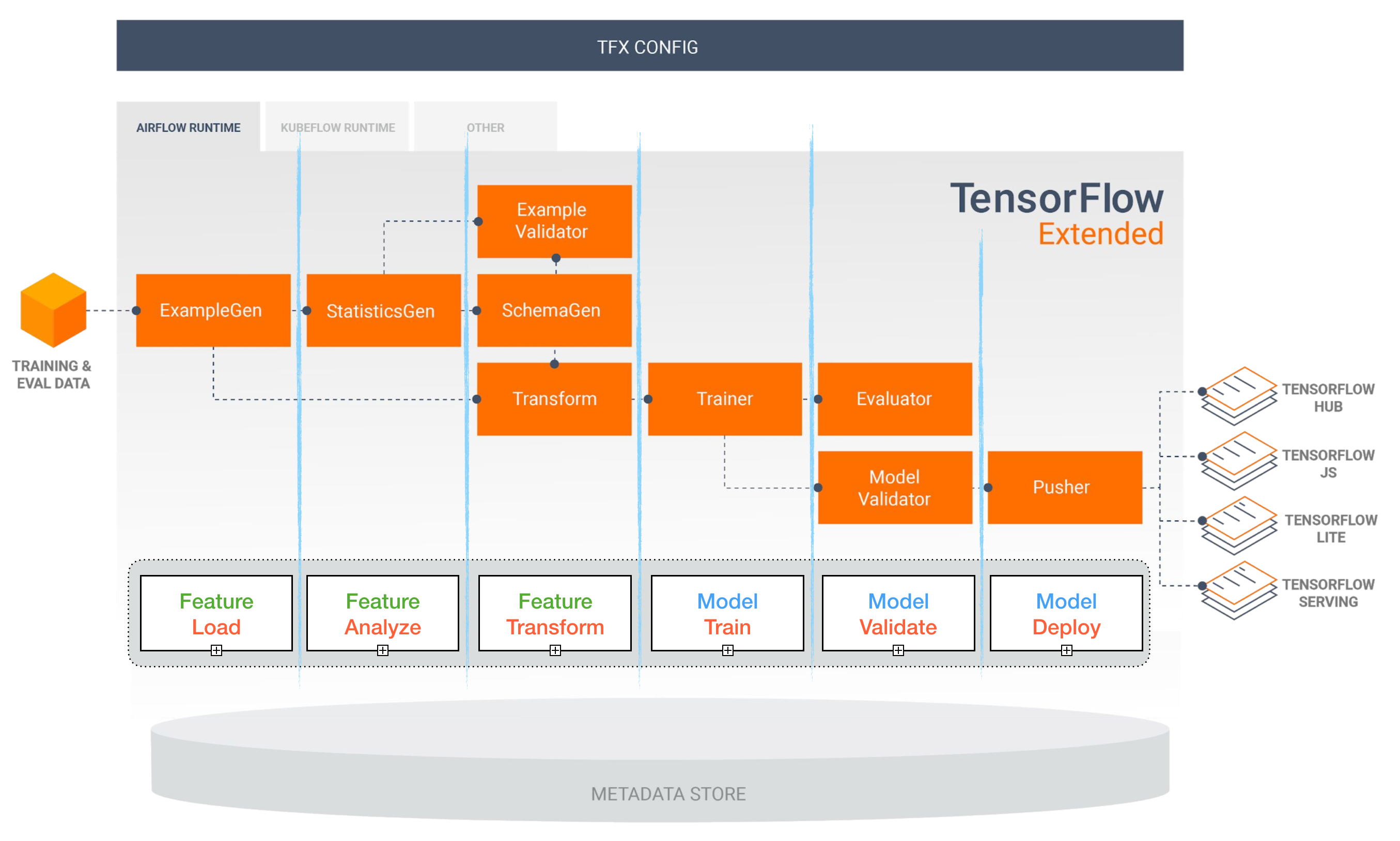
Airflow and KubeFlow ML Pipelines [TBD][待补充]

Other useful links 其他有用的链接:
- Lessons learned from building practical deep learning systems
- Machine Learning: The High Interest Credit Card of Technical Debt
Contributing
References:
[1]: Full Stack Deep Learning Bootcamp, Nov 2019.
[2]: Advanced KubeFlow Workshop by Pipeline.ai, 2019.
[3]: TFX: Real World Machine Learning in Production
原作者:Alireza Dirafzoon
翻译自:https://github.com/alirezadir/Production-Level-Deep-Learning/blob/master/README.md译者:Liu Yun
链接:https://github.com/liuyun1217/Production-Level-Deep-Learning





