BERT的两个任务主要是MLM和NSP,虽然取得了先进的性能,但是作者认为其并未充分利用句子的语言结构。作者将语言结构信息引入到预训练任务中,提出了一种新型的上下文表示模型-StructBERT,本质上,StructBERT的模型架构和BERT一样,不同点在于新增了两个预训练目标来增强模型的预训练,即:Word Structural Objective和Sentence Structural Objective
方法
本文作者提出的StructBERT模型结果如下所示:
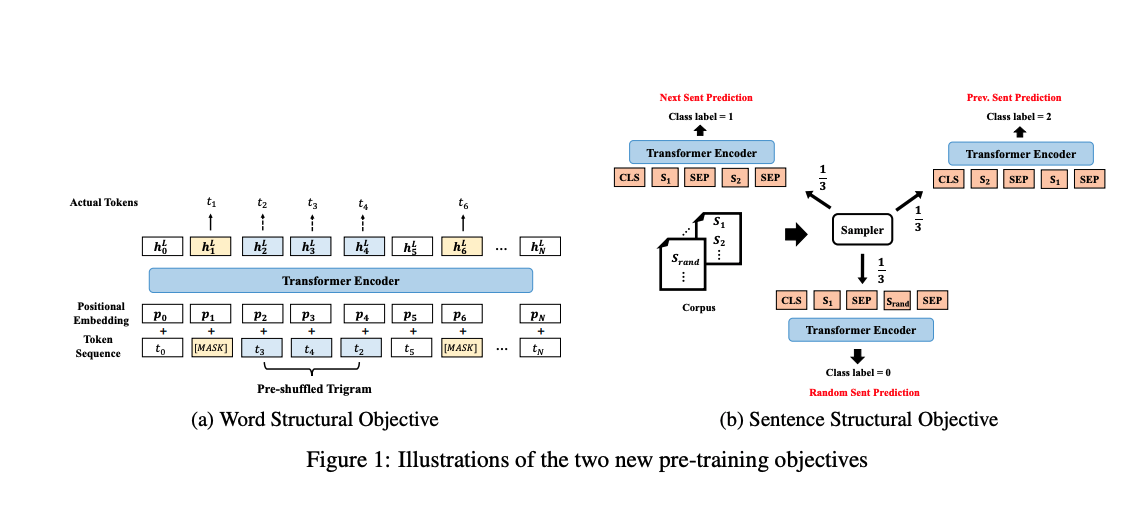
具体来说,原模型还是BERT,主要在预训练任务上做了改进,主要有:WSO和SSO。
Word Structural Objective
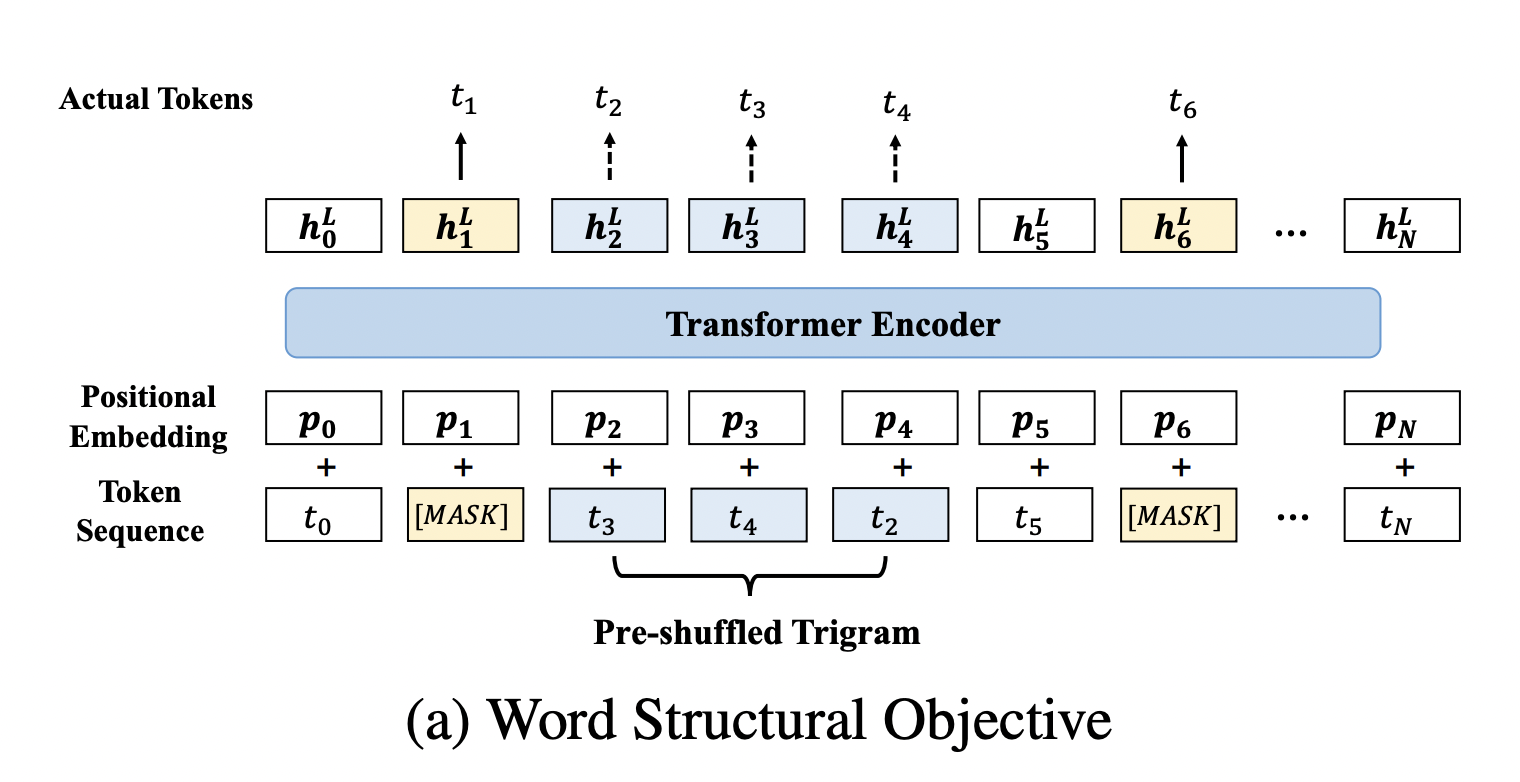
BERT无法直接显式的对单词顺序和高阶依赖性建模。而将一句话中的单词打乱,一个好的语言模型应该能够通过重组单词顺序恢复句子的正确排列。为了能在StructBERT中实现,用Word Structural Objective使得打乱的句子重构成正确的句子顺序。具体的做法是从一句话中未被mask的单词中选取一定长度的子序列(论文中的超参K表示序列长度),将子序列中的单词打乱,然后让模型恢复正确顺序,为了更好理解,下图充分说明了做法。
优化目标为:
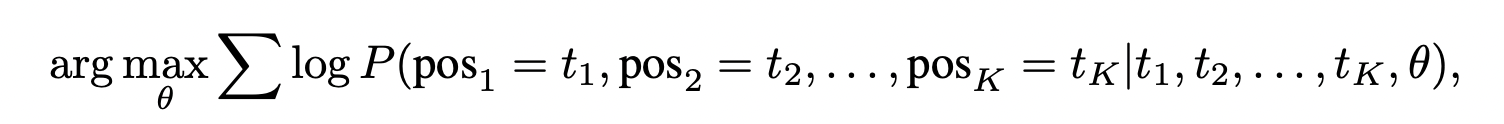
其中为模型的参数,K为子序列长度,且:
- 如果K越大,则输入更多的干扰数据,模型学习相对而言比较难,重构能力大,但是噪声多。
- 如果K越小,则输入更少的干扰数据,模型学习相对而言比较简单,重构能力会下降。
在论文中,作者选取的K为3(Trigram)的子序列(作者选取K=3来平衡语言的重构性和模型的鲁棒性)进行打乱,从上图中可以看出打乱的是t2,t3,t4,然后最后输出正确的顺序。在具体的实验中,作者从重新排列的子序列中选择5%,进行词序的打乱。
Sentence Structural Objective
在原始的BERT模型任务中,BERT很容易预测下一句话,在StructBERT中,增加上一句话的预测,使得语言模型以双向方式知道句子顺序。具体做法是给定句子对(S1,S2),预测S1是S2的上一句话、S2是S1的上一句话还是S1,S2来自不同的文本(即毫无关联性)。实验中,对于一个句子S,1/3的概率采样S的下一句组成句子对,1/3的概率采样S的上一句组成句子对,1/3的概率随机采样一个其他文档的句子组成句子对。下图可以更好的理解这种做法。
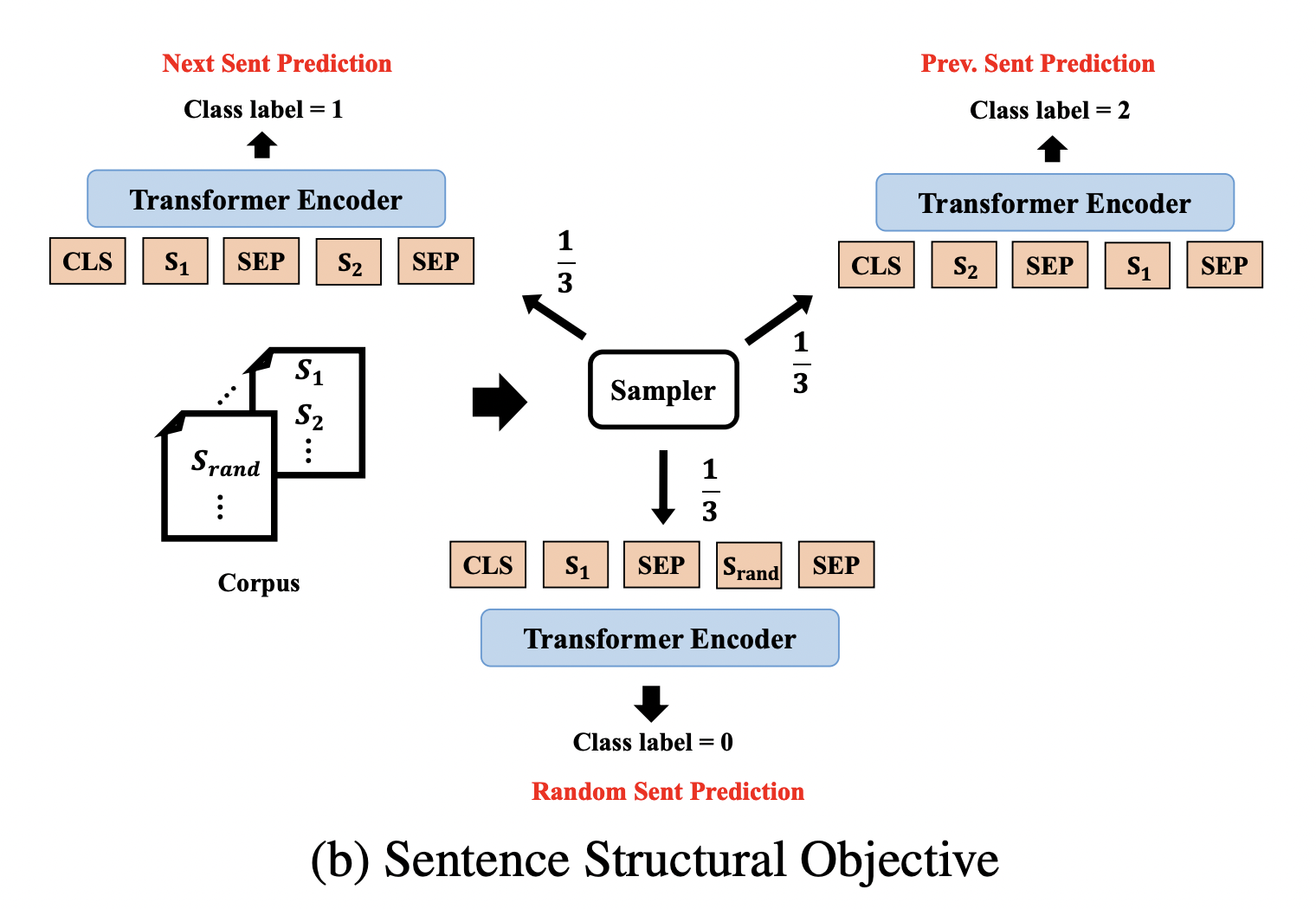
从图中可以看出,从BERT模型中S1和S2是否是上下文关系的二分类问题变成了这里的三分类问题。
实验结果
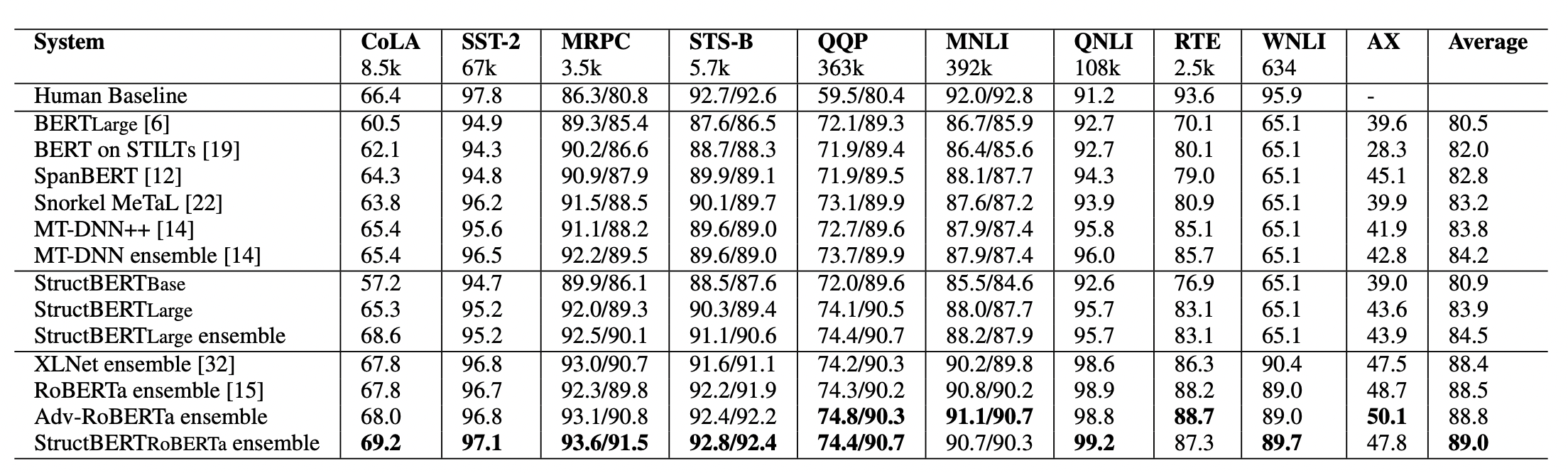
从表中可以看出,StructBERT在9个任务中在平均上超过现有的所有模型,而且在6个任务中表现最佳。在MNLI(-m/-mm)任务上,提升了0.3%/0.5%,但是只是对域内数据进行了微调,这里体现了模型的通用性。在CoLA任务中,可能是单词的排序任务和语法纠错任务存在着很强的相关性,使得该任务有显著的改进。在SST-2任务中,比BERT有进步,但是性能却不如MT-DNN,表明基于单句的情感分析从词序和句序中受益很少。