交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距,下面将主要介绍交叉熵损失。
交叉熵损失函数
理想地,我们希望神经网络可以从错误中快速地学习。在实践中,这种情况经常出现吗?为了回答这个问题,让我们看看一个小例子。这个例子包含一个只有一个输入的神经元:
我们会训练这个神经元来做一件非常简单的事:让输入1 转化为0。当然,这很简单了,手工找到合适的权重和偏置就可以了,不需要什么学习算法。然而,看起来使用梯度下降的方式来学习权重和偏置是很有启发的。所以,我们来看看神经元如何学习。
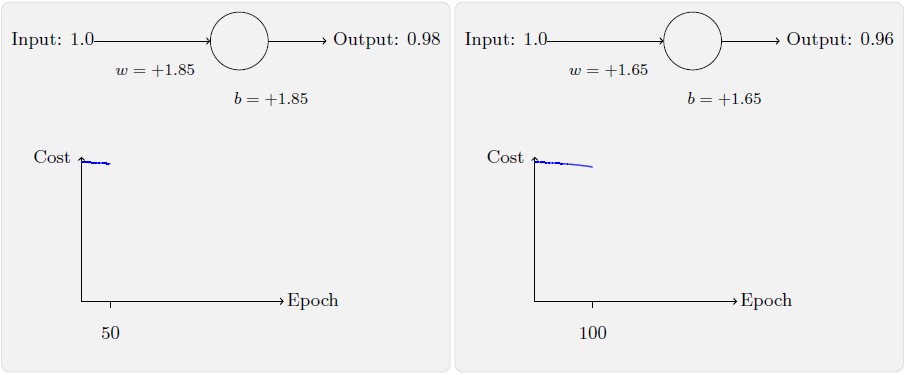
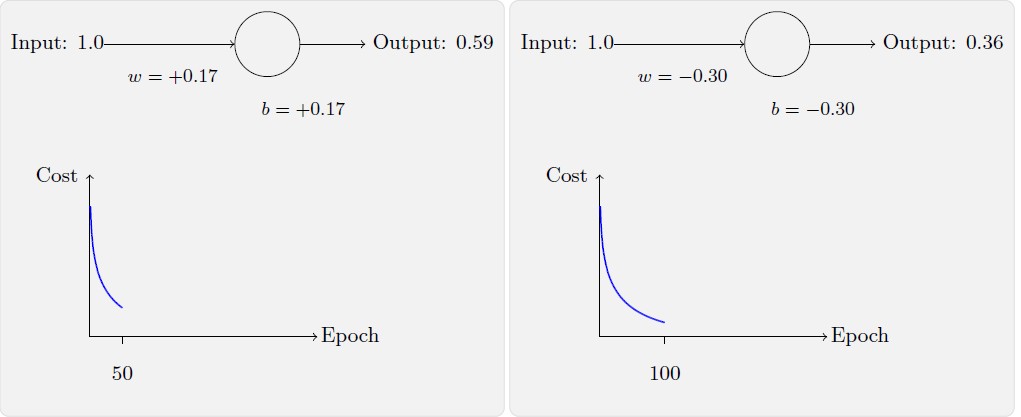
为了让这个例子更明确,我们会首先将权重和偏置初始化为0.6 和0.9。这些就是一般的开始学习的选择,并没有任何刻意的想法。一开始的神经元的输出是0.82,所以这离我们的目标输出0.0 还差得很远。从下图来看看神经元如何学习到让输出接近0.0 的。注意这些图像实际上是正在进行梯度的计算,然后使用梯度更新来对权重和偏置进行更新,并且展示结果。设置学习速率η=0.15 进行学习,一方面足够慢的让我们跟随学习的过程,另一方面也保证了学习的时间不会太久,几秒钟应该就足够了。损失函数我们使用二次损失函数。
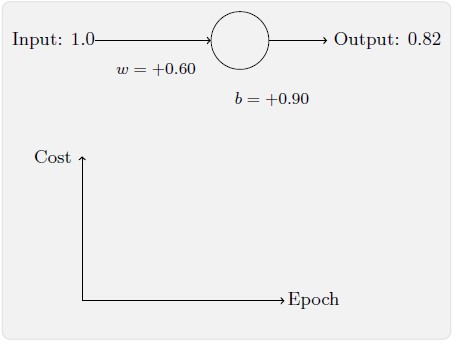
随着迭代次数的增加,神经元的输出、权重、偏置和损失的变化如下面一系列图形所示:
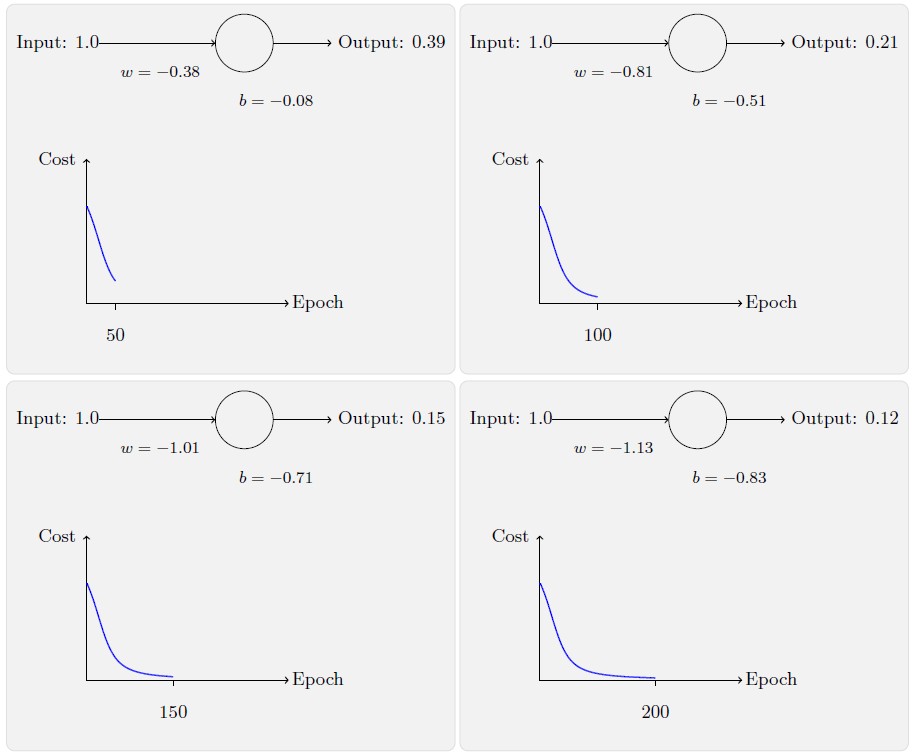
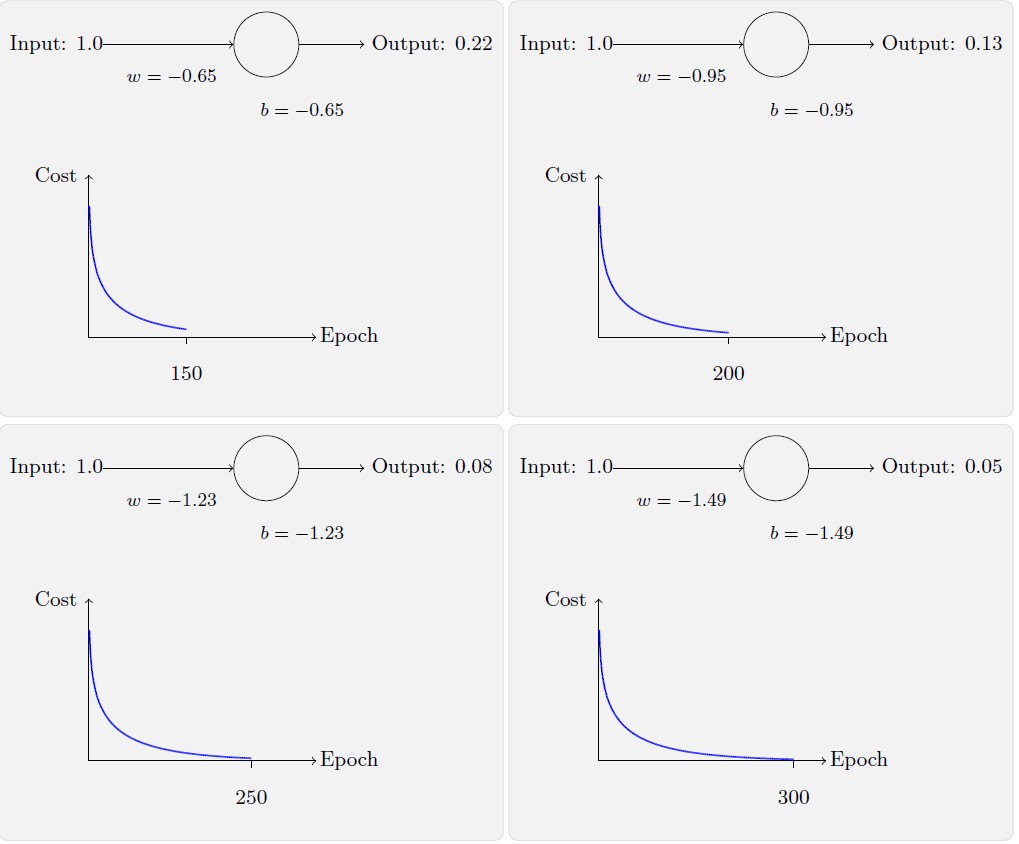
如上所示,神经元快速地学到了使得损失函数下降的权重和偏置,给出了最终的输出为0.09。这虽然不是我们的目标输出0.0,但是已经挺好了。假设我们现在将初始权重和偏置都设置为2.0。此时初始输出为0.98,这是和目标值的差距相当大的。现在看看神经元学习的过程。
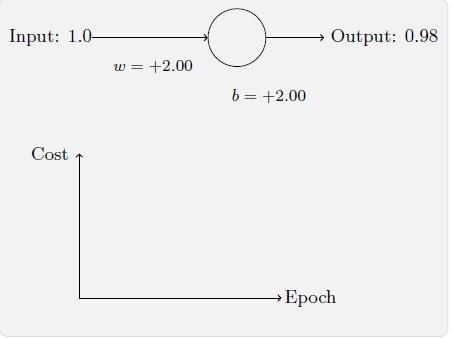
你将看到如下的一系列变化:
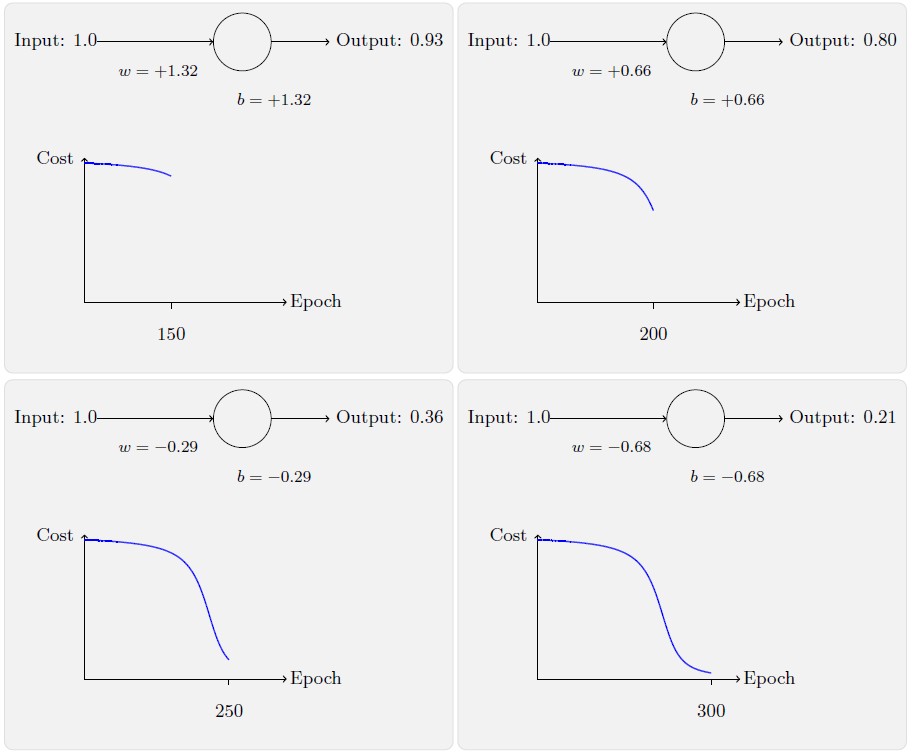
虽然这个例子使用的了同样的学习速率η=0.15,我们可以看到刚开始的学习速度是比较缓慢的。对前150 左右的学习次数,权重和偏置并没有发生太大的变化。随后学习速度加快,与上一个例子中类似了,神经网络的输出也迅速接近0.0。这种行为看起来和人类学习差为差异很大。正如我在此节开头所说,我们通常是在犯错比较明显的时候学习的速度最快。但是我们已经看到了人工神经元在其犯错较大的情况下其实学习很有难度。并且,这种现象不仅仅是在这个小例子中出现,也会在更加一般的神经网络中出现。为何学习如此缓慢?我们能够找到避免这种情况的方法吗?
为了理解这个问题的源头,想想我们的神经元是通过改变权重和偏置,并以一个损失函数的偏导数(∂C/∂w和∂C/∂b)决定的速度学习。所以,我们在说“学习慢”时,实际上就是说这些偏导数很小。理解他们为何这么小就是我们面临的挑战。为了理解这些,让我们计算偏导数看看。我们一直在用的是二次损失函数,定义如下:
C=2(y−a)2(1)
其中a 是神经元的输出,训练输入为x=1,y=0 则是目标输出。显式地使用权重和偏置来表达这个,我们有a=σ(z),其中z=wx+b。使用链式法则来求权重和偏置的偏导数就有:
∂w∂C=(a−y)σ′(z)x=aσ′(z)(2)
∂b∂C=(a−y)σ′(z)=aσ′(z)(3)
其中我们将x=1 和y=0 代入了。为了理解这些表达式的行为,让我们仔细看σ′(z) 这一项。假设σ 函数为:
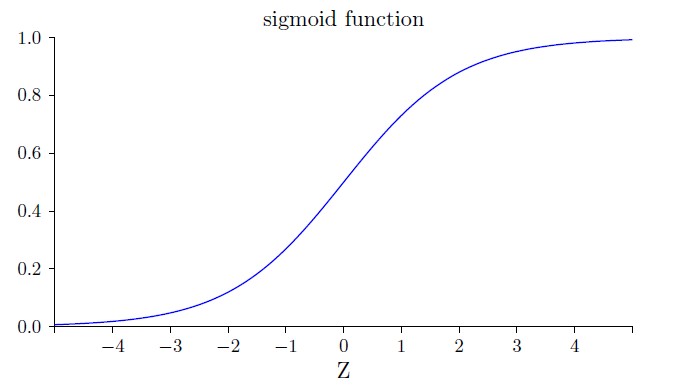
我们可以从这幅图看出,当神经元的输出接近1 的时候,曲线变得相当平,所以σ′(z) 就很小了。方程(2) 和(3) 也告诉我们(∂C/∂w和∂C/∂b) 会非常小。这其实就是学习缓慢的原因所在。并且,我们后面也会提到,这种学习速度下降的原因实际上也是更加一般的神经网络学习缓慢的原因,并不仅仅是在这个特例中特有的。
1. 引入交叉熵代价函数
那么我们如何解决这个问题呢?研究表明,我们可以通过使用交叉熵损失函数来替换二次损失函数。为了理解什么是交叉熵,我们稍微改变一下之前的简单例子。假设,我们现在要训练一个包含若干输入变量的的神经元,x1,x2,....对应的权重为w1,w2,.... 和偏置b:
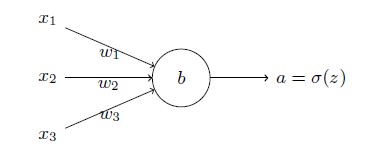
神经元的输出就是a=σ(z),其中z=∑jwjxj+b是输入的带权和。我们如下定义这个神经元的交叉熵损失函数:
C=−n1x∑[ylna+(1−y)ln(1−a)](4)
其中$n 是训练数据的总数,求和是在所有的训练输人x$ 上进行的,y 是对应的目标输出。表达式(4) 是否解决学习缓慢的问题并不明显。实际上,甚至将这个定义看做是损失函数也不是显而易见的!在解决学习缓慢前,我们来看看交叉熵为何能够解释成一个损失函数。
将交叉熵看做是损失函数有两点原因:
- 第一,它是非负的,C>0。可以看出:表达式(4) 中的求和中的所有独立的项都是负数的,因为对数函数的定义域是(0,1);求和前面有一个负号。
- 第二,如果对于所有的训练输入x,神经元实际的输出接近目标值,那么交叉熵将接近0。
假设在这个例子中,y=0 和a≈0。这是我们想得到的结果。我们看到公式(4) 中第一个项就消去了,因为y=0,而第二项实际上就是−ln(1−a)≈0。反之,y=1 而a≈1。所以在实际输出和目标输出之间的差距越小,最终的交叉熵的值就越低了。
综上所述,交叉熵是非负的,在神经元达到很好的正确率的时候会接近0。这些其实就是我们想要的损失函数的特性。其实这些特性也是二次损失函数具备的。所以,交叉熵就是很好的选择了。但是交叉熵损失函数有一个比二次损失函数更好的特性就是它避免了学习速度下降的问题。为了弄清楚这个情况,我们来算算交叉熵函数关于权重的偏导数。我们将a=σ(z) 代入到(4) 中应用两次链式法则,得到:
∂wj∂C==−n1x∑(σ(z)y−1−σ(z)(1−y))∂wj∂σ−n1x∑(σ(z)y−1−σ(z)(1−y))σ′(z)xj.
将结果合并一下,简化成:
∂wj∂C=n1x∑σ(z)(1−σ(z))σ′(z)xj(σ(z)−y)(7)
根据前面我们假设σ(z)=1/(1+e−z),则可知:
σ′(z)=====(−1+e−z1)’(1+e−z)2e−z(1+e−z)21+e−z−1(−1+e−z1)(1−1+e−z1)σ(z)(1−σ(z))
因此,我们可以得到σ′(z)=σ(z)(1−σ(z))。将此结果代入公式(7),我们看到σ′(z)=σ(z)(1−σ(z))这两项在方程中直接约去了,所以最终形式就是:
∂wj∂C=n1x∑xj(σ(z)−y)(8)
这是一个优美的公式。它告诉我们权重学习的速度受到σ(z)−y,也就是输出中的误差的控制。更大的误差,更快的学习速度。这是我们直觉上期待的结果。特别地,这个损失函数还避免了像在二次损失函数中类似方程中σ′(z) 导致的学习缓慢,见方程(2)。当我们使用交叉熵的时候,σ′(z) 被约掉了,所以我们不再需要关心它是不是变得很小。这种约除就是交叉熵带来的特效。实际上,这也并不是非常奇迹的事情。我们在后面可以看到,交叉熵其实只是满足这种特性的一种选择罢了。
根据类似的方法,我们可以计算出关于偏置的偏导数。我这⾥不再给出详细的过程,你可以轻易验证得到
∂b∂C=n1x∑(σ(z)−y).(9)
再一次, 这避免了二次损失函数中类似方程(3) 中σ′(z) 项导致的学习缓慢。
让我们重回最原初的例子,来看看换成了交叉熵之后的学习过程。现在仍然按照前面的参数配置来初始化网络,开始权重为0.6,而偏置为0.9。
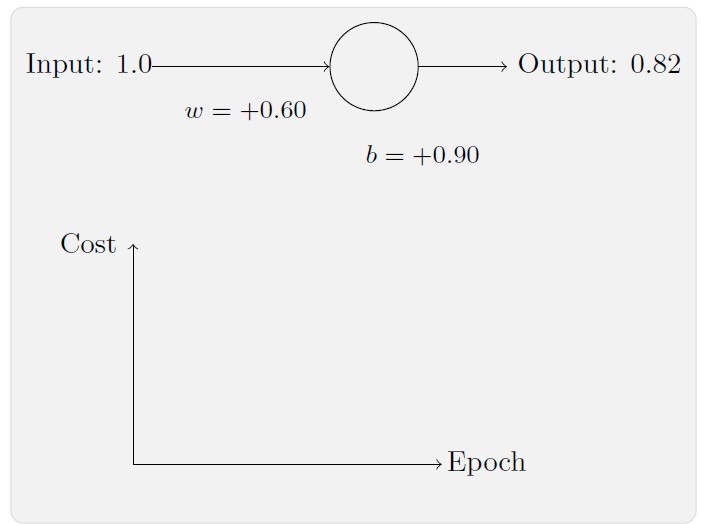
看看在换成交叉熵之后网络的学习情况,你将看到如下变化的曲线:
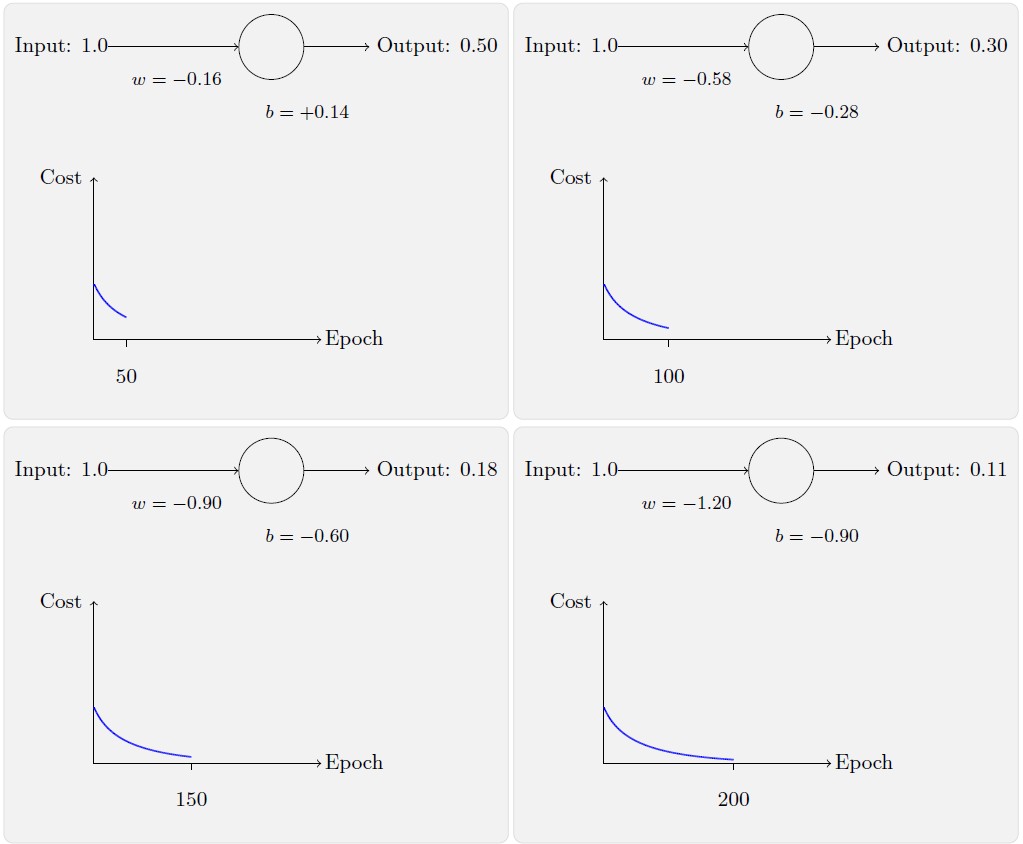
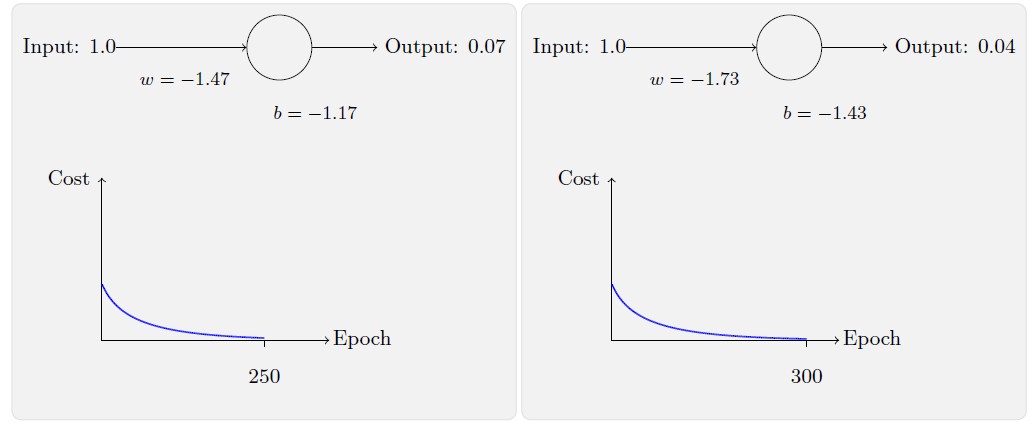
毫不奇怪,在这个例子中,神经元学习得相当出色,跟之前差不多。现在我们再看看之前出问题的那个例子,权重和偏置都初始化为2.0:
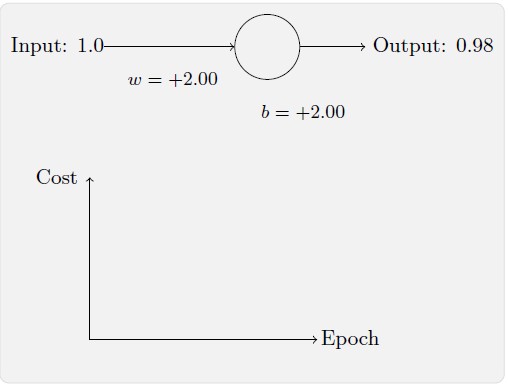
你将看到如下变化的曲线:
成功了!这次神经元的学习速度相当快,跟我们预期的那样。如果你观测的足够仔细,你可以发现损失函数曲线要二次损失函数训练前面部分要陡很多。那个交叉熵导致的陡度让我们高兴,这正是我们期待的当神经元开始出现严重错误时能以最快速度学习。
2. 交叉熵的含义?
我们对于交叉熵的讨论聚焦在代数分析。这虽然很有用,但是也留下了一个未能回答的更加宽泛的概念上的问题,如:交叉熵究竟表示什么?存在一些直觉上的思考交叉熵的方法吗?我们如何想到这个概念?
让我们从最后一个问题开始回答:什么能够激发我们想到交叉熵?假设我们发现学习速度下降了,并理解其原因是因为在公式(2) 和(3) 中的σ′(z) 那一项。在研究了这些公式后,我们可能就会想到选择一个不包含σ′(z) 的损失函数。所以,这时候对一个训练样本x,其损失C=Cx满足:
∂wj∂C=xj(a−y)(10)
∂b∂C=(a−y)(11)
如果我们选择的损失函数满足这些条件,那么它们就能以简单的方式呈现这样的特性:初始误差越大,神经元学习得越快。这也能够解决学习速度下降的问题。实际上,从这些公式开始,现在我们就看看凭着我们数学的直觉推导出交叉熵的形式是可行的。我们来推一下,由链式法则,我们有
∂b∂C=∂a∂Cσ′(z)(12)
使σ′(z)=σ(z)(1−σ(z))=a(1−a),上个等式就变成:
∂b∂C=∂a∂Ca(1−a).(13)
对比等式(11),我们有
∂a∂C=a(1−a)a−y.(14)
对此方程关于a 进行积分,得到
C=−[ylna+(1−y)ln(1−a)]+constant,(15)
其中constant 是积分常量。这是一个单独的训练样本x 对损失函数的贡献。为了得到整个的损失函数,我们需要对所有的训练样本进行平均,得到了
C=−n1x∑[ylna+(1−y)ln(1−a)]+constant,(16)
而这里的常量就是所有单独的常量的平均。所以我们看到方程(10) 和(11) 唯一确定了交叉熵的形式,并加上了一个常量的项。这个交叉熵并不是凭空产出的。而是一种我们以自然和简单的方法获得的结果。
那么交叉熵直觉含义又是什么?我们如何看待它?深入解释这一点会将我们带到一个不大愿意讨论的领域。然而,还是值得提一下,有一种源自信息论的解释交叉熵的标准方式。粗略地说,交叉熵是“不确定性”的一种度量。特别地,我们的神经元想要计算函数x→y=y(x)。但是,它用函数x→a=a(x)进行了替换。假设我们将$a 想象成我们神经元估计为y = 1$ 的概率,而$1 - a 则是y = 0$ 的概率。那么交叉熵衡量我们学习到y 的正确值的平均起来的不确定性。如果输出我们期望的结果,不确定性就会小一点;反之,不确定性就大一些。

