train = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/train.csv') test = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/test.csv') # preprocessing ### mean imputations train['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True) test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### reducing fat content to only two categories train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat']) train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular']) test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat']) test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
## for calculating establishment year train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year'] test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']
### missing values for size train['Outlet_Size'].fillna('Small',inplace=True) test['Outlet_Size'].fillna('Small',inplace=True)
### label encoding cate. var. col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content'] test['Item_Outlet_Sales'] = 0 combi = train.append(test) number = LabelEncoder() for i in col: combi[i] = number.fit_transform(combi[i].astype('str')) combi[i] = combi[i].astype('int') train = combi[:train.shape[0]] test = combi[train.shape[0]:] test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## removing id variables training = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1) testing = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1) y_train = training['Item_Outlet_Sales'] training.drop('Item_Outlet_Sales',axis=1,inplace=True) features = training.columns target = 'Item_Outlet_Sales' X_train, X_test = training, testing
从不同的监督学习算法开始,让我们来看看哪一种算法给了我们最好的结果。
1 2 3 4 5 6 7 8
from xgboost import XGBRegressor from sklearn.linear_model import BayesianRidge, Ridge, ElasticNet from sklearn.neighbors import KNeighborsRegressor from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor, GradientBoostingRegressor #from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error from sklearn.model_selection import cross_val_score
## normal submission using xgb model = XGBRegressor() model.fit(X_train,y_train) pred = model.predict(X_test) ## saving file sub = pd.DataFrame(data = pred, columns=['Item_Outlet_Sales']) sub['Item_Identifier'] = test['Item_Identifier'] sub['Outlet_Identifier'] = test['Outlet_Identifier'] #sub.to_csv('bigmart-xgb.csv', index='False') cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8)
结果如下
1 2 3
array([-1206713.26379787, -1167261.04584799, -1160852.79913974, -1159134.1333961 , -1173283.13996661]) Xgb gives us the best results. on submission it gives an rmse of 1152.73
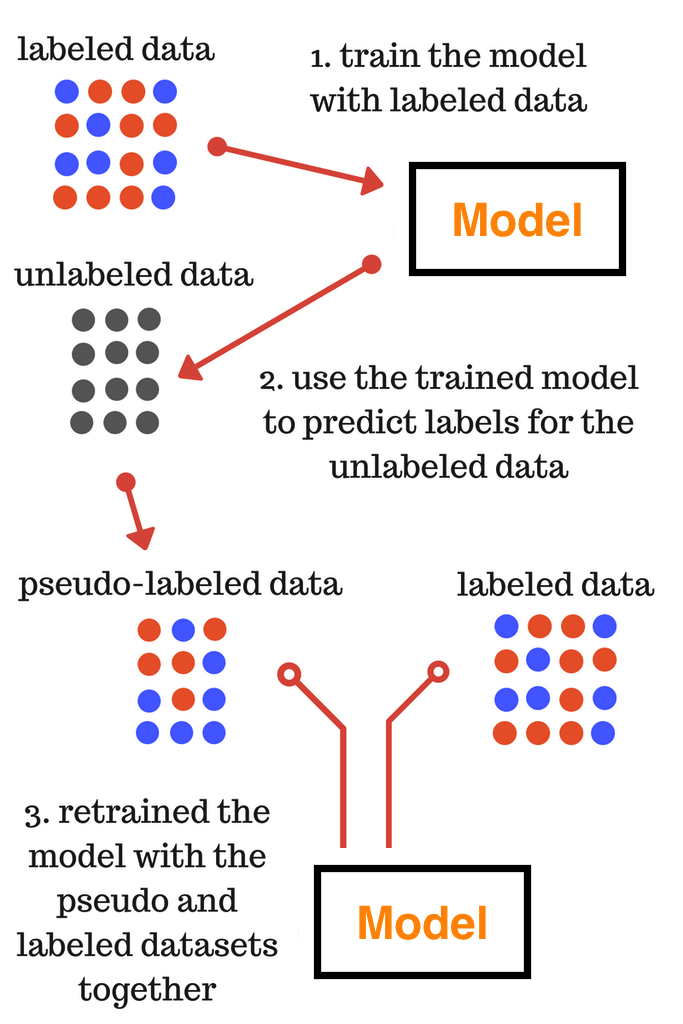
from sklearn.utils import shuffle from sklearn.base import BaseEstimator, RegressorMixin classPseudoLabeler(BaseEstimator, RegressorMixin): ''' Sci-kit learn wrapper for creating pseudo-lebeled estimators. ''' def__init__(self, model, unlabled_data, features, target, sample_rate=0.2, seed=42): ''' @sample_rate - percent of samples used as pseudo-labelled data from the unlabled dataset ''' assert sample_rate <= 1.0, 'Sample_rate should be between 0.0 and 1.0.' self.sample_rate = sample_rate self.seed = seed self.model = model self.model.seed = seed self.unlabled_data = unlabled_data self.features = features self.target = target defget_params(self, deep=True): return { "sample_rate": self.sample_rate, "seed": self.seed, "model": self.model, "unlabled_data": self.unlabled_data, "features": self.features, "target": self.target } defset_params(self, **parameters): for parameter, value in parameters.items(): setattr(self, parameter, value) returnself deffit(self, X, y): ''' Fit the data using pseudo labeling. ''' augemented_train = self.__create_augmented_train(X, y) self.model.fit( augemented_train[self.features], augemented_train[self.target] ) returnself def__create_augmented_train(self, X, y): ''' Create and return the augmented_train set that consists of pseudo-labeled and labeled data. ''' num_of_samples = int(len(self.unlabled_data) * self.sample_rate) # Train the model and creat the pseudo-labels self.model.fit(X, y) pseudo_labels = self.model.predict(self.unlabled_data[self.features]) # Add the pseudo-labels to the test set pseudo_data = self.unlabled_data.copy(deep=True) pseudo_data[self.target] = pseudo_labels # Take a subset of the test set with pseudo-labels and append in onto # the training set sampled_pseudo_data = pseudo_data.sample(n=num_of_samples) temp_train = pd.concat([X, y], axis=1) augemented_train = pd.concat([sampled_pseudo_data, temp_train]) return shuffle(augemented_train) defpredict(self, X): ''' Returns the predicted values. ''' returnself.model.predict(X) defget_model_name(self): returnself.model.__class__.__name__
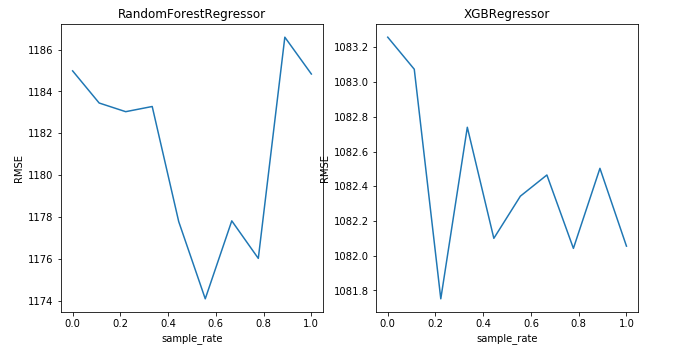
sample_rates = np.linspace(0, 1, 10) defpseudo_label_wrapper(model): return PseudoLabeler(model, test, features, target) # List of all models to test model_factory = [ RandomForestRegressor(n_jobs=1), XGBRegressor(), ] # Apply the PseudoLabeler class to each model model_factory = map(pseudo_label_wrapper, model_factory) # Train each model with different sample rates results = {} num_folds = 5 for model in model_factory: model_name = model.get_model_name() print('%s' % model_name) results[model_name] = list() for sample_rate in sample_rates: model.sample_rate = sample_rate # Calculate the CV-3 R2 score and store it scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8) results[model_name].append(np.sqrt(scores.mean()*-1))
1 2 3 4 5 6 7 8 9 10
plt.figure(figsize=(16, 18)) i= 1 for model_name, performance in results.items(): plt.subplot(3, 3, i) i += 1 plt.plot(sample_rates, performance) plt.title(model_name) plt.xlabel('sample_rate') plt.ylabel('RMSE') plt.show()