任何机器学习模型对所需数据的规范和格式都有一定的要求,在深度学习中通常要求输入算法的数据为一个多维矩阵的形式,因此,在建模之前都要对原始数据进行处理.
Keras针对几种常见的输入数据形态,提供了几个易于使用的工具来处理数据,包括针对序列模型的数据预处理,针对文本模型的文字预处理,以及针对图片输入的预处理.所有函数都在Keras.preprocessing这个模块里面.
文字预处理
在文本建模实践中,一般都需要把原始文本进行分词,标记化处理,对于已经读入的文字的预处理包含以下几个步骤:
- 分词
- 建立索引
- 序列补齐
- 转化为矩阵
- 批处理
分词
分词主要利用到text.text_to_word_sequence函数,可以按照给定的分隔符进行分割文本,
1 | keras.preprocessing.text.text_to_word_sequence(text, |
本函数将一个句子拆分成单词构成的列表
参数说明:
- text:字符串,待处理的文本
- filters:需要滤除的字符的列表或连接形成的字符串,例如标点符号。默认值为 ‘!"#$%&()*+,-./:;<=>?@[]^_`{|}~\t\n’,包含标点符号,制表符和换行符等
- lower:布尔值,是否将序列设为小写形式(只英文模式下才有大小之分)
- split:字符串,单词的分隔符,如空格
返回的是一个字符串列表,比如:
1 | #encoding:utf-8 |
结果是:
1 | ['those', 'that', 'come', 'through', 'the', 'ivory', 'gate', 'cheat', 'us', 'with', 'empty', 'promises', 'that', 'never', 'see', 'fulfillemnt'] |
如果输入的是中文话,建议使用专门为中文设计的分词工具进行分词处理,比如jieba,
1 | import jieba |
结果是:
1 | ['他','来到','了','网易','杭研'] |
详细的jieba语法可以点击github.
建立索引
完成分词之后,得到的字或者单词列表并不能直接用于建模,还需要转化为数字符号,Keras提供了one_hot编码法的函数来实现:
1 | keras.preprocessing.text.one_hot(text, |
本函数将一段文本编码为one-hot形式的码,即仅记录词在词典中的下标。
【Tips】 从定义上,当字典长为n时,每个单词应形成一个长为n的向量,其中仅有单词本身在字典中下标的位置为1,其余均为0,这称为one-hot。
为了方便起见,函数在这里仅把“1”的位置,即字典中词的下标记录下来。
参数说明:
- n:整数,字典长度
返回整数列表,每个整数是[1,n]之间的值,代表一个单词(不保证唯一性,即如果词典长度不够,不同的单词可能会被编为同一个码)。
序列对齐
最终索引之后的文字信息会被按照索引编号放入多维矩阵中来建模,在建模之前,需要先进行序列补齐的工作.这是因为将一段话拆分成单一的词之后,丢失了重要的上下文信息.因此将上下文的一组词放在一起建模能保持原来的上下文信息.序列补齐分两种情况.
- 一种是自然的文本序列,
- 另一种是将一个大的单词序列拆分成很多个小块的连续子串,这种情况一般是一大段文字按照固定长度移动一个窗口,将窗口内的单词索引加载到多维矩阵的每一行,比如
word2vec算法.
对于序列对齐,可以使用keras中的sequence.pad_sequences函数
1 | keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None, dtype='int32', |
将长为nb_samples的序列(标量序列)转化为形如(nb_samples,nb_timesteps)2D numpy array。如果提供了参数maxlen,nb_timesteps=maxlen,否则其值为最长序列的长度。其他短于该长度的序列都会在后部填充0以达到该长度。长于nb_timesteps的序列将会被截断,以使其匹配目标长度。padding和截断发生的位置分别取决于padding和truncating.
参数说明:
- sequences:浮点数或整数构成的两层嵌套列表
- maxlen:None或整数,为序列的最大长度。大于此长度的序列将被截短,小于此长度的序列将在后部填0.
- dtype:返回的numpy array的数据类型
- padding:‘pre’或‘post’,确定当需要补0时,在序列的起始还是结尾补
- truncating:‘pre’或‘post’,确定当需要截断序列时,从起始还是结尾截断
- value:浮点数,此值将在填充时代替默认的填充值0
返回一个2维张量,比如
1 | from keras.preprocessing import text,sequence |
结果显示如下;
1 | y0: |
批处理
当有多个文本文件时候,使用批处理是一个比较高效的方法,Keras同样提供了一个Tokenizer类来进行文本处理.
1 | keras.preprocessing.text.Tokenizer(num_words=None, |
Tokenizer是一个用于向量化文本,或将文本转换为序列(即单词在字典中的下标构成的列表,从1算起)的类。
参数说明:
- 与text_to_word_sequence同名参数含义相同
- num_words:None或整数,处理的最大单词数量。若被设置为整数,则分词器将被限制为待处理数据集中最常见的num_words个单词
- char_level: 如果为 True, 每个字符将被视为一个标记
比如:
1 | from keras.preprocessing.text import Tokenizer |
结果显示如下:
1 | [[0 1 1 1 1 1 1 1 1 1 1 1 1 1 1] |
fit_on_texts函数的作用是对于输入的文本计算一些关键统计量,并建立索引.
序列处理
序列数据预处理,一般主要有两种,一种是上面提高的文本处理,另一种是时间序列数据处理,不过处理的方式都一样,都是将相邻的连续n个元素拼接在一起,类似与NLP中的n-gram算法一样.
当然除了连续一种形式,还有一跳跃的方式,类似于word2vec算法,在Keras中有一个skipgrams的函数,将一个词向量索引编号按照两种可选的方式转化为一系列两两元素的组合和标注z,
1 | keras.preprocessing.sequence.skipgrams(sequence, vocabulary_size, |
参数说明:
- sequence:下标的列表,如果使用sampling_tabel,则某个词的下标应该为它在数据库中的顺序。(从1开始)
- vocabulary_size:整数,字典大小
- window_size:整数,正样本对之间的最大距离
- negative_samples:大于0的浮点数,等于0代表没有负样本,等于1代表负样本与正样本数目相同,以此类推(即负样本的数目是正样本的negative_samples倍)
- shuffle:布尔值,确定是否随机打乱样本
- categorical:布尔值,确定是否要使得返回的标签具有确定类别
- sampling_table:形如(vocabulary_size,)的numpy array,其中sampling_table[i]代表没有负样本或随机负样本。等于1为与正样本的数目相同 采样到该下标为i的单词的概率(假定该单词是数据库中第i常见的单词)
如果和是紧挨着,则标注z为1,否则为0,
1 | from keras.preprocessing.sequence import skipgrams |
结果如下:
1 | ([3, 4], 1) |
图像处理
图像数据处理,主要是keras.preprocessing.image.ImageDataGenerator类,这是一个数据生成器对象,一般的主要功能是Data Augmentation.官方文档是说明:
1 | keras.preprocessing.image.ImageDataGenerator(featurewise_center=False, |
参数说明:
- featurewise_center:布尔值,使输入数据集去中心化(均值为0), 按feature执行
- samplewise_center:布尔值,使输入数据的每个样本均值为0
- featurewise_std_normalization:布尔值,将输入除以数据集的标准差以完成标准化, 按feature执行
- samplewise_std_normalization:布尔值,将输入的每个样本除以其自身的标准差
- zca_whitening:布尔值,对输入数据施加ZCA白化
- zca_epsilon: ZCA使用的eposilon,默认1e-6
- rotation_range:整数,数据提升时图片随机转动的角度
- width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
- height_shift_range:浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
- shear_range:浮点数,剪切强度(逆时针方向的剪切变换角度)
- zoom_range:浮点数或形如[lower,upper]的列表,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
- channel_shift_range:浮点数,随机通道偏移的幅度
- fill_mode:;‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理
- cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值
- horizontal_flip:布尔值,进行随机水平翻转
- vertical_flip:布尔值,进行随机竖直翻转
- rescale: 重放缩因子,默认为None. 如果为None或0则不进行放缩,否则会将该数值乘到数据上(在应用其他变换之前)
- preprocessing_function: 将被应用于每个输入的函数。该函数将在任何其他修改之前运行。该函数接受一个参数,为一张图片(秩为3的numpy array),并且输出一个具有相同shape的numpy array
- data_format:字符串,“channel_first”或“channel_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channel_last”对应原本的“tf”,“channel_first”对应原本的“th”。以128x128的RGB图像为例,“channel_first”应将数据组织为(3,128,128),而“channel_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channel_last”
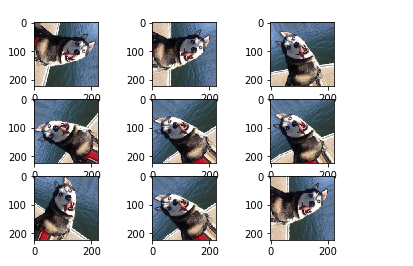
比如:
输入一张图片:

对其进行旋转,平移等可以得到:
1 | from keras.preprocessing.image import ImageDataGenerator |