最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准方面取得了实质性进展。虽然这种方法在体系结构中通常是任务无关的,但它仍然需要数千或上万个示例的特定于任务的微调数据集。相比之下,人类通常只能通过几个例子或简单的指令来执行一项新的语言任务,而当前的NLP系统在很大程度上仍难以做到这一点。在这里,论文展示了扩展语言模型可以极大地提高任务无关性、few-shot性能,有时甚至可以与以前最先进的微调方法相媲美。具体而言,论文训练了GPT-3,这是一个具有1750亿个参数的自回归语言模型,比以往任何非稀疏语言模型都多10倍,并在few-shot设置下测试了其性能。所有任务应用GPT-3模型时均不进行任何梯度更新或微调,而只是通过与模型的文本交互指定任务和少样本学习演示。GPT-3在许多NLP数据集上都取得了很好的性能,包括机器翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,例如解读单词、在句子中使用新单词或执行3位数算术。同时,论文还确定了一些GPT-3的zero-shot学习仍然困难的数据集,以及一些GPT-3面临与大型网络语料库培训相关的方法学问题的数据集。最后,论文发现GPT-3可以生成新闻文章的样本,而人类评价者很难将其与人类撰写的文章区分开来。论文讨论了这一发现和GPT-3的广泛社会影响。
论文源码地址: https://github.com/openai/gpt-3
GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
-
对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
-
对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛化能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
方法
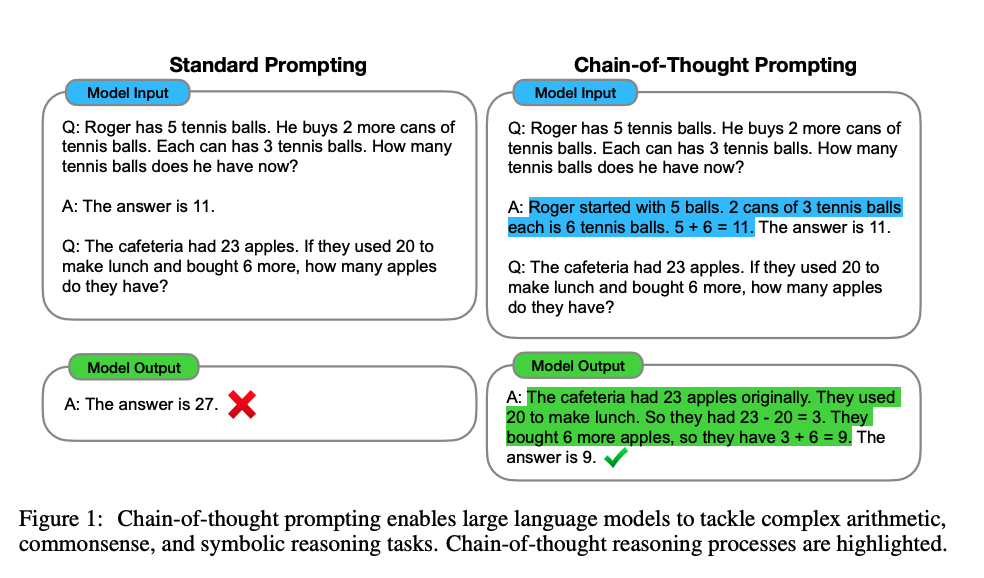
传统上,预训练的模型是通过微调来学习适应新的任务的。模型的微调需要大量的数据来解决我们正在解决的问题,也需要更新模型的权重。现有的微调方法如下图所示。
GPT-3采用了不同的学习方法。不需要大量标记数据来推断新问题。相反,它可以不从数据(零次学习 Zero-Shot Learning )中学习,只从一个例子(一次学习 one-Shot Learning)或几个例子中学习。

其中:
- Fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数
- Zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
- One-shot:预训练 + task description + example + prompt,预测。不更新模型参数
- Few-shot:预训练 + task description + examples + prompt,预测。不更新模型参数
模型结构
GPT-3 使用与 GPT-2 相同的模型和架构,包括其中修改的初始化,预归一化和其中描述的可逆分词,不同之处是我们在Transformer的各层中交替使用稠密和局部带状稀疏注意力模式,类似于稀疏Transformer。
GPT-3共训练了8种不同大小的模型,范围从1.25亿参数到1,750亿参数,超过三个数量级,最后一个模型称为GPT-3。

训练数据
使用CommonCrawl数据集,采取了3个步骤来提高数据集的平均质量:
- 基于与一系列高质量参考语料库的相似性,我们下载并筛选了CommonCrawl的一个版本;
- 在文档级别、数据集内部和数据集之间执行了模糊重复数据消除,以防止冗余,并保留完整验证集作为一种精确的过拟合度量
- 将已知的高质量参考语料库添加到训练组合中,以增强CommonCrawl并增加其多样性。
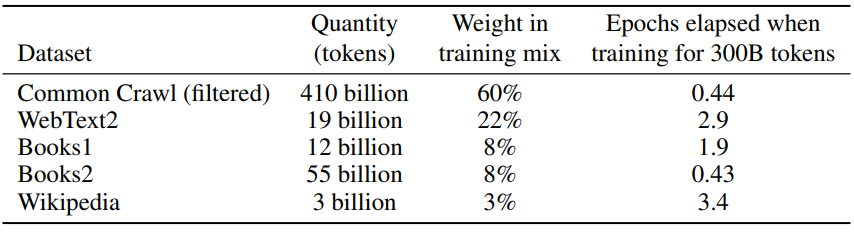
CommonCrawl数据是从2016年至2019年的每月CommonCrawl的41个分片中下载的,构成了过滤前的45TB压缩明文和过滤后的570GB,大致相当于4000亿字节对编码的分词符号。在训练过程中,并非按大小比例对数据集进行采样,而是对我们视为更高质量的数据集进行更高频采样,例如CommonCrawl和Books2数据集在训练期间的采样次数少于一次,而其他数据集则采样2 -3次。从本质上讲,这会接受少量的过度拟合,以换取更高质量的训练数据。
总结
论文提出了一个1750亿参数的语言模型,该模型在zero-shot、one-shot和few-shot设置下的许多NLP任务和基准测试中显示出强大的性能,在某些情况下几乎与最先进的微调系统的性能相匹配,并且在动态定义的任务中生成高质量的样本和强大的定性性能。论文记录了在不使用微调的情况下性能扩展的大致可预测趋势。论文还讨论了这类模型的社会影响。尽管有许多局限性和弱点,这些结果表明,非常大的语言模型可能是开发适应性强的通用语言系统的一个重要因素。