本文探讨了大型语言模型(LLM)产生一个连贯的思维链的能力——一系列的短句子,模仿一个人在回答一个问题时可能拥有的推理过程。通过Chain of Thoughts(CoT,即推理中间过程),提升大型语言模型(LLM)推理能力,在三个LLM上证明了CoT能够显著提升算术、常识、符号推理能力。
方法
语言模型的规模达到 100B 的参数量之后,就能够在像情感分类 、主题分类等这种分类任务上取得非常好的结果,作者将这类任务归纳为 system-1,也就是能够人类很快很直观地理解的任务。还有一类任务需要很慢而且是很仔细的考虑,作者将其归纳为 system-2 (比如一些设计逻辑、常识的推理任务),作者发现,即便语言模型的规模达到了几百B的参数量,也很难在 system-2 这类任务上获得很好的表现。
作者将这种现象称为 flat scaling curves:如果将语言模型参数量作为横坐标,在 system-2 这类任务上的表现作为纵坐标,则折线就会变得相当平缓,不会像在 system-1 这类任务上那么容易就实现模型的性能随着模型参数量的增长而提升,也就是说,在 system-2 这类任务上语言模型就很难大力出奇迹了。
在此前关于大规模语言模型的推理任务中,有两种方法:
-
针对下游任务对模型进行微调。
-
为模型提供少量的输入输出样例进行学习。
但是这两种方法都有着局限性,前者微调计算成本太高,后者采用传统的输入输出样例在推理任务上效果很差,而且不会随着语言模型规模的增加而有实质性的改善。
针对这个问题,作者提出了 chain of thought (CoT)这种方法来利用大语言模型求解推理任务,具体案例如下所示:

上图(左) 为standard prompting形式,为<input, output>,标准的prompt方法来解决推理任务,首先这是一个少样本学习的方法,需要给出一些问题和答案的样例,然后拼接这正想要求解的问题,最后再拼接一个字符串“A:”之后输入到大语言模型中,让大语言模型进行续写。大语言模型会在所提供的问题和答案的样例中学习如何求解,结果发现很容易出错,也就是上面提到的大语言模型在 system-2 上很容易遇到瓶颈。
上图(右) 为本文方法提出的CoT Prompt的例子,为<input, chain-of-thought, output>,其中高亮部分为chain-of-thought。CoT 与 Standard prompting 唯一的区别就是,CoT 在样例中在给出问题的同时,不仅给出了答案,在答案之前还给出了人为写的中间推理步骤。在把问题、中间推理步骤和答案的若干样例拼接上所想要求解的问题和字符串“A”,再输入到语言模型之后,语言模型会自动地先续写中间推理步骤,有了这些推理步骤之后,它就会更容易地给出正确答案,也就是能够更好地解决 system-2 这类的问题。
相较于一般的小样本提示学习,思维链提示学习有几个吸引人的性质:
- 在思维链的加持下,模型可以将需要进行多步推理的问题分解为一系列的中间步骤,这可以将额外的计算资源分配到需要推理的问题上。
- 思维链为模型的推理行为提供了一个可解释的窗口,使通过调试推理路径来探测黑盒语言模型成为了可能。
- 思维链推理应用广泛,不仅可以用于数学应用题求解、常识推理和符号操作等任务,而且可能适用任何需要通过语言解决的问题。
- 思维链使用方式非常简单,可以非常容易地融入语境学习(in-contextlearning),从而诱导大语言模型展现出推理能力。
实验
下图是本文实验所提到的数据集的一些示例。数学推理任务为绿色,常识推理为橙色,蓝色为符号推理。

实验结果
作者人工设计了一套 8 个带有 CoT 的 few-shot 样例,而且作者在五个数据集中统一使用了这 8 个带有 CoT 推的 few-shot 样例
其中的一个原因是因为人工构造 CoT 的 few-shot 样例的成本是很高的,因为不仅要找到具有代表性的问题,还要为每个问题设计中间推理步骤以及答案,而最后的性能对这些人工设计非常敏感,所以需要反复进行调试。

从上图可以看出,CoT 会随着模型规模的提高会涌现出更强大的能力。也就是说 CoT 对于小规模模型没有太大影响,只有在使用参数为 100B 以上的模型时才会产生性能提升。并且作者发现,在较小规模的模型中产生了流畅但不符合逻辑的 CoT,导致了比 Standard prompt 更低的表现。
其次,CoT 对于更复杂的问题有更大的性能提升。例如,对于 GSM8K(baseline 性能最低的数据集),最大的 GPT 和 PaLM 模型的性能提高了一倍以上。而对于 SingleOp(MAWPS中最简单的子集,只需要一个步骤就可以解决),性能的提高要么是负数,要么是非常小。
在 GPT 和 PaLM 模型下,CoT 超越了之前的 sota(之前的 sota 采用的是在特定任务下对模型进行微调的模式)
消融实验
Equation Only:把 CoT 替换成只包含 CoT 中的算式部分。
Variable compute only:把 CoT 替换成与中间 CoT 长度相等的…
Thought after answer:把中间推理步骤放在答案的后面。

结果发现上述两种方法都比 CoT 差了很多,这就说明了 CoT 虽然简单,但是不能再简单了,而且这也更能体现出 CoT 中自然语言所起的作用。
实验结果显示:把中间推理步骤放在答案的后面所得到的结果也不是很好,这就说明,在训练数据集中大部分情况下依然还是先给出中间推理步骤再给出答案,而不是先给出答案再给出中间推理步骤
鲁棒性实验
在本节的最后,作者也提到 CoT 的性能可能也会对人工设计的 prompt 比较敏感,因此有必要评测所提出的方法的鲁棒性
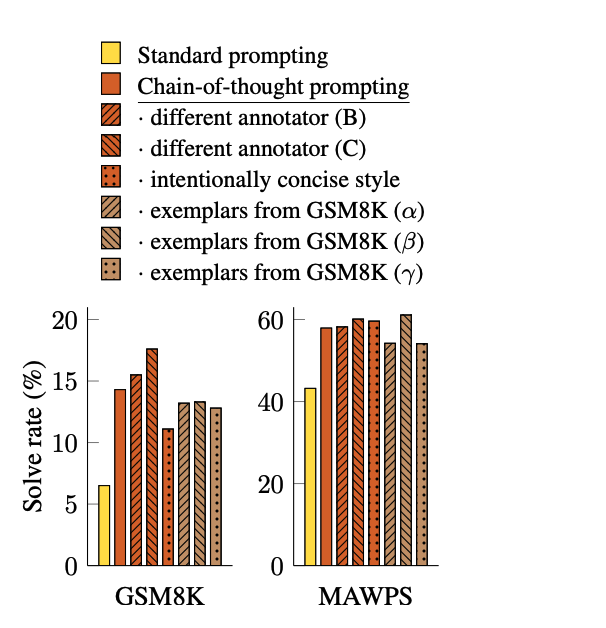
different annotator 表示有三个作者分别设计了一套带有 CoT 的样例
concise style 表示作者专门又设计了一套更加简单的带有 CoT 的样例
exemplars 从带有中间推理步骤的数据集中随机地选取一些问题,并附上这些数据集中自带的中间推理步骤构成 CoT 的样例,再拼接上答案来进行评测
最后的结果显示:带 CoT 的方法都要比不带 CoT 的 standard prompting 要带来更加显著的性能提升,尤其是在图三中的两个更加困难的数学推理数据集中,这种性能提升更加明显.
讨论
在文章的末尾,作者强调,在 CoT 诞生之前的标准的 prompting 只是大语言模型语言能力的一个下限,虽然 CoT 模拟了人类推理的思维过程,但这并不能回答神经网络是否真的“推理”,我们将其作为一个悬而未决的问题。在大规模语言模型上使用 CoT 推理使得在实际应用中服务的成本很高;进一步的研究可以探索如何在较小的模型中进行推理。