尽管基于BERT的模型在诸多NLP任务中取得了不错的性能(通过有监督的Fine-tune),但其自身计算的句向量(不经过Fine-tune,而是直接通过对所有词向量求平均)往往被约束在一个很小的区域内,表现出很高的相似度(这种现象一般叫做"model Collapse"), 因而难以反映出两个句子的语义相似度。本文作者提出了一种基于对比学习的句子表示方法ConSERT (a Contrastive Framework for Self-Supervised SEntence Representation Transfer),通过在目标领域的无监督语料上微调,使模型生成的句子表示与下游任务的数据分布更加适配。实验结果表明,ConSERT在句子语义匹配任务上取得了state-of-the-art结果,并且在少样本场景下仍表现出较强的性能提升。
介绍
句向量表示学习在自然语言处理(NLP)领域占据重要位置,许多NLP任务的成功都离不开训练优质的句子表示向量。特别是在文本语义匹配、文本向量检索等任务上,模型通过计算两个句子编码后的Embedding在表示空间的相似度来衡量这两个句子语义上的相似度,从而决定其匹配分数。
尽管基于BERT的模型在诸多NLP任务中取得了不错的性能(通过有监督的Fine-tune),但其自身计算的句向量(不经过Fine-tune,而是直接通过对所有词向量求平均)质量较低,甚至比不上Glove的效果,因而难以反映出两个句子的语义相似度,如下所示:
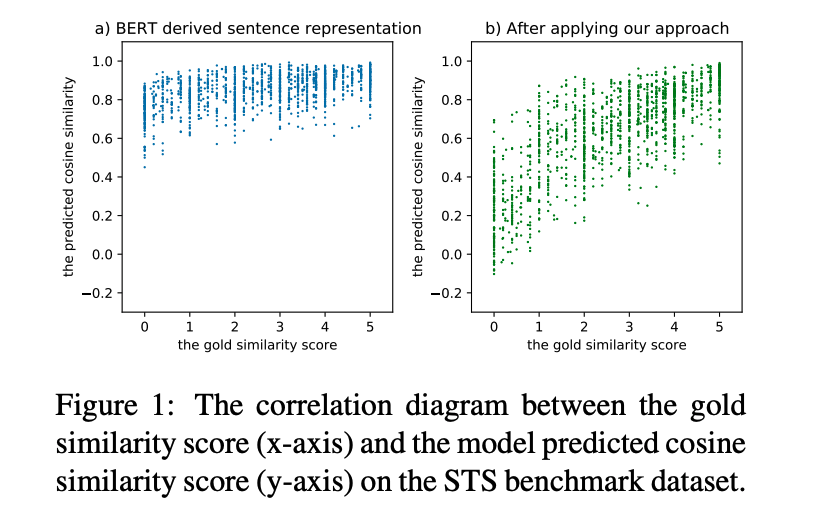
从上图可以看到,BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子都具有较高的相似度分数,即使是那些语义上完成无关的句子对。
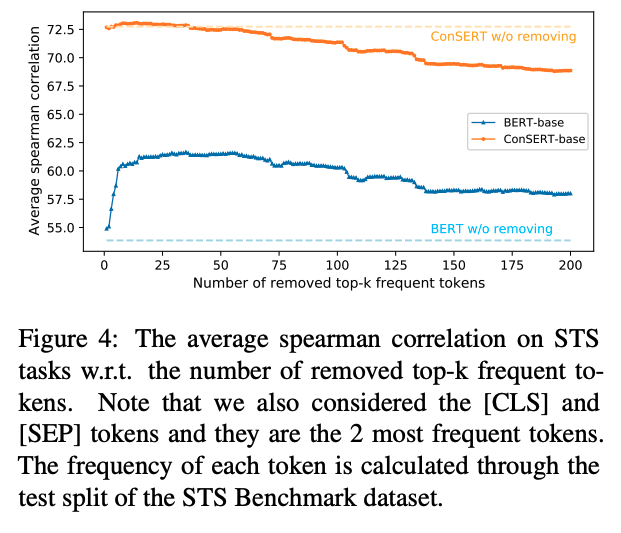
另外,从上图可以看到,BERT的句向量表示Collapse现象和句子中的高频词有关,具体来说,当通过平均词向量的方式计算句向量时,那些高频词的词向量将会主导句向量,使之难以体现其原本的语义,当计算句向量时去除若干高频词时,Collapse现象可以在一定程度上缓解。
方法
本文作者提出的ConSERT模型结构如下:
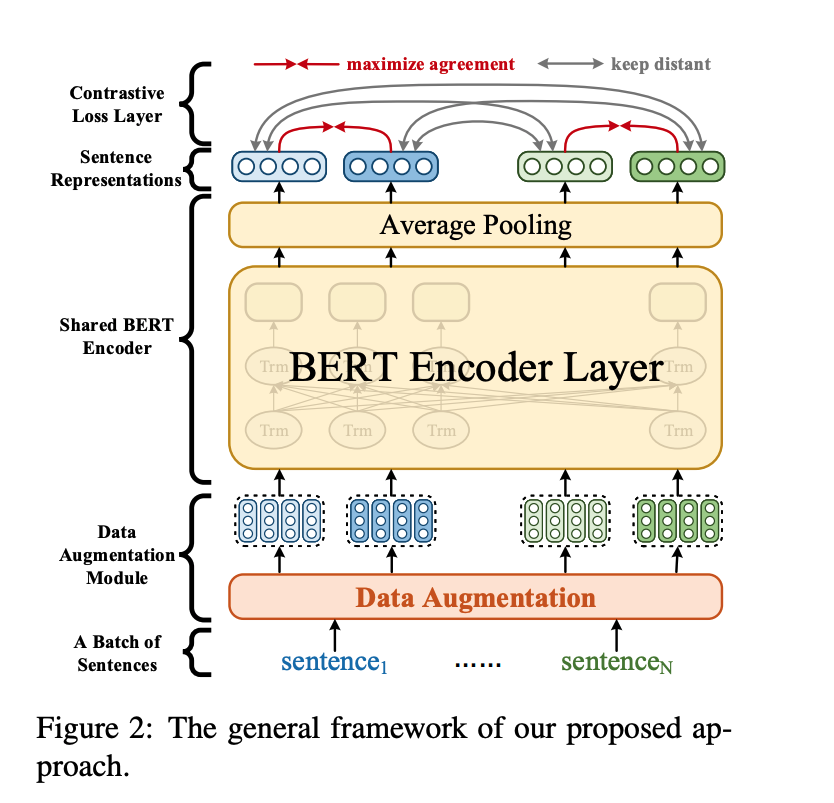
如上图所示,ConSERT借鉴了SimCLR,主要在编码器模块进行了改进:
- 数据增强模块: 作用于Embedding层,为同一个句子生成两个不同的增强版本(View)。
- 共享的BERT编码器,为输入的句子生成句向量。
- 对比损失层: 用于在一个Batch的样本中计算对比损失,其思想是最大化同一个样本不同增强版本句向量的相似度,同时使得不同样本的句向量相互远离。
对于每一个样本,首先通过两种预设的数据增强方法和生成两个版本:, ,其中,是句子程度,是向量维度,然后通过共享的BERT编码器进行编码和一个平均池化层,得到句向量和。
训练时,先从数据集中采样一个Batch的文本,设Batch size为。通过数据增强模块,会得到总共条样本,借鉴SimCLR,通过NT-Xent损失对模型进行Fine-tune:
其中函数为余弦相似度函数;表示temperature。该损失从直观上理解,是让Batch内的每个样本都找到其对应的另一个增强版本,而Batch内的其他个样本将充当负样本。优化的结果就是让同一个样本的两个增强版本在表示空间中具有尽可能大的一致性,同时和其他的Batch内负样本相距尽可能远。
数据增强
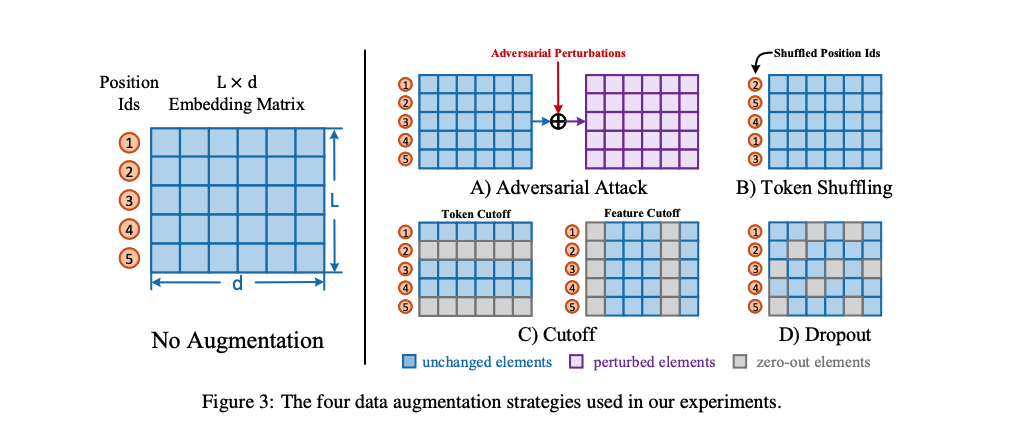
图像领域可以方便地对样本进行变换,如旋转、翻转、裁剪、去色、模糊等等,从而得到对应的增强版本。然而,由于语言天然的复杂性,很难找到高效的、同时又保留语义不变的数据增强方法。本文作者考虑了在Embedding层隐式生成增强样本的方法,如下图所示:
-
对抗攻击(Adversarial Attack):这一方法通过梯度反传生成对抗扰动,将该扰动加到原本的Embedding矩阵上,就能得到增强后的样本。由于生成对抗扰动需要梯度反传,因此这一数据增强方法仅适用于有监督训练的场景。
-
打乱词序(Token Shuffling):这一方法扰乱输入样本的词序。由于Transformer结构没有“位置”的概念,模型对Token位置的感知全靠Embedding中的Position Ids得到。因此在实现上,只需要将Position Ids进行Shuffle即可。
-
Token Cutoff:随机选取Token,将对应Token的Embedding整行置Dropout。
-
feature Cutoff:随机选取feature 维度,将对应Embedding整列置Dropout。
-
dropout:Embedding中的每一个元素都以一定概率置为零。
训练策略
除了无监督训练以外,作者还提出了几种进一步融合监督训练的策略:
-
联合训练(joint):有监督的损失和无监督的损失通过加权联合训练模型,即:,表示对比损失,表示CrossEntropy损失。
-
先有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用无监督的方法进行表示迁移。
-
联合训练再无监督(joint-unsup):先使用联合损失训练模型,再使用无监督的方法进行表示迁移。
实验
实验数据
为了验证ConSERT的有效性,本文在文本语义匹配任务共7个数据集上实验:
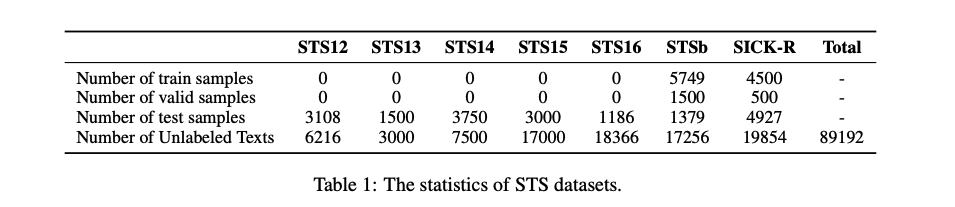
在实验中,作者删除了原始BERT模型中的droput层,具体的实验参数可阅读原文。
实验结果
- 无监督实验
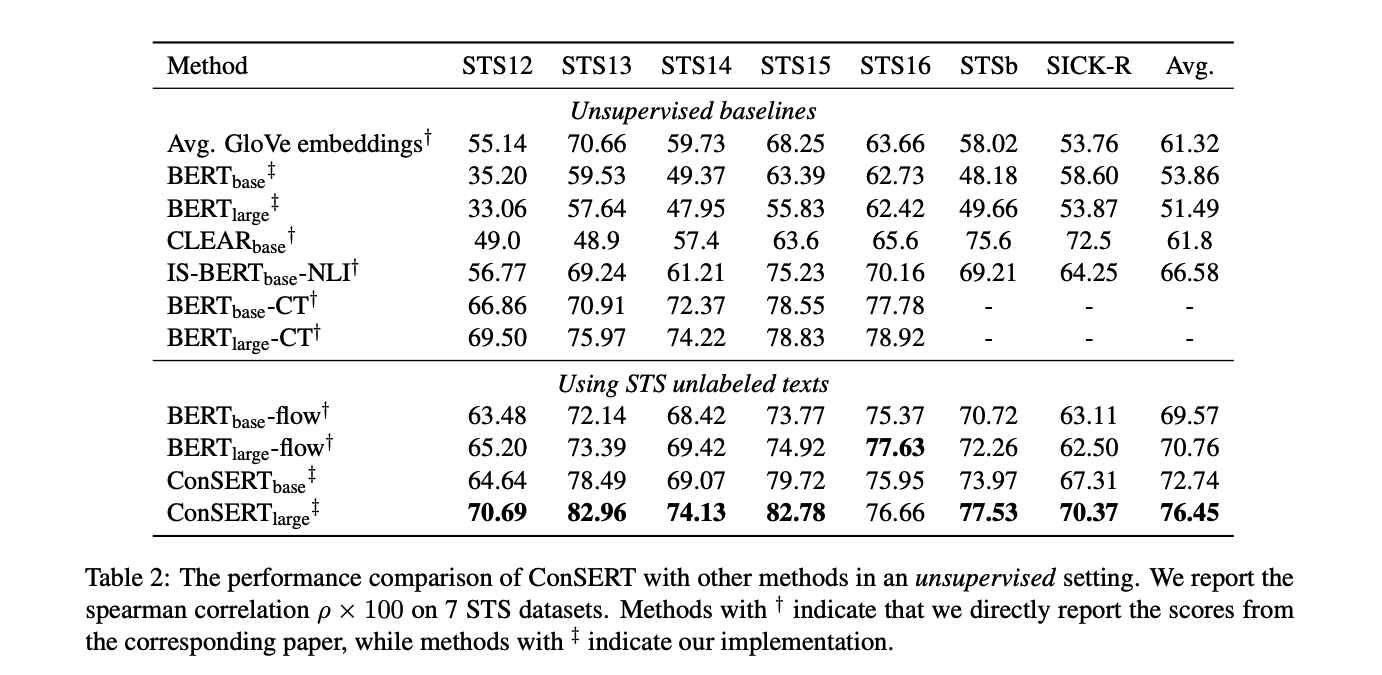
在无监督实验中,本文直接基于预训练的BERT在无标注的STS数据上进行Fine-tune。结果显示,ConSERT在完全一致的设置下大幅度超过之前的SOTA—BERT-flow,达到了8%的相对性能提升。
- 有监督实验
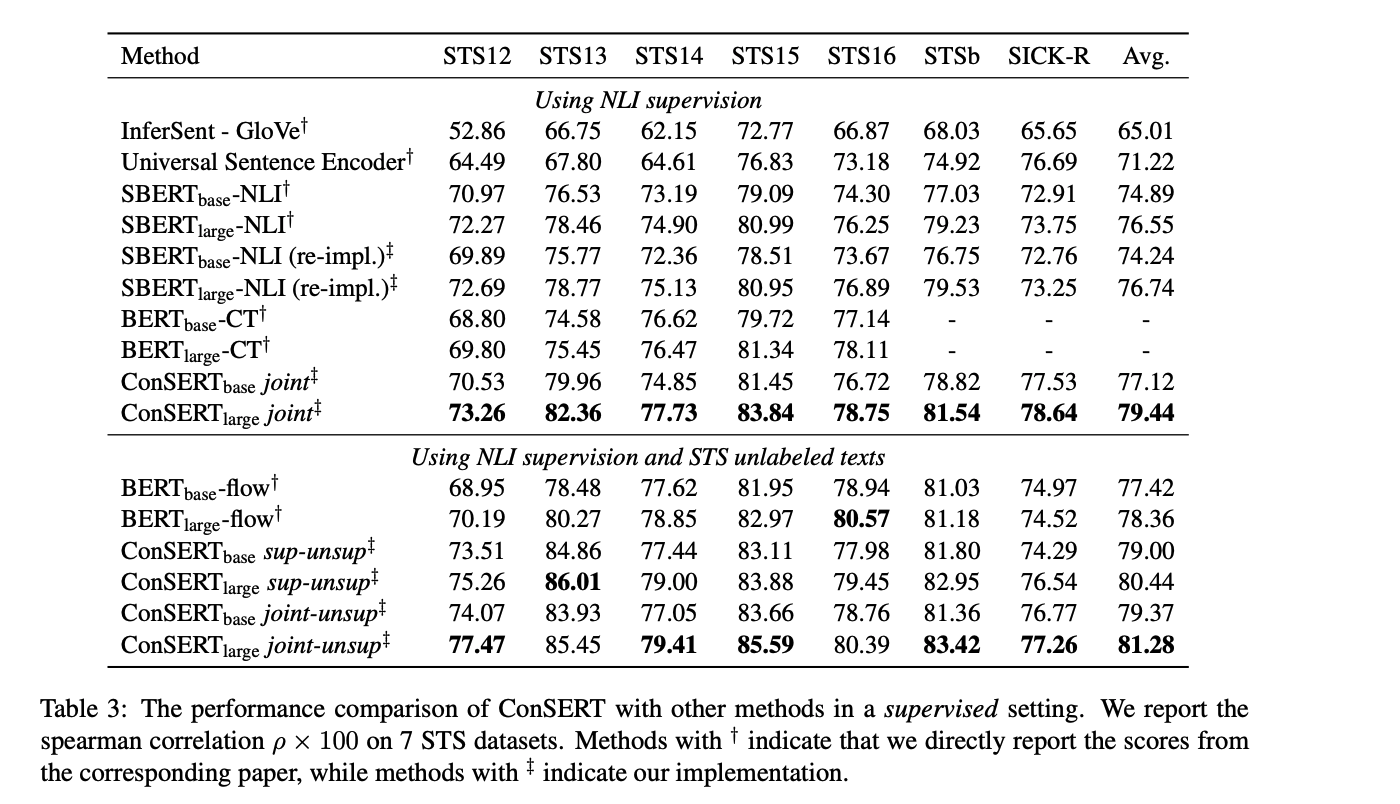
在有监督实验中,本文额外使用了来自SNLI和MNLI的训练数据,使用上述三种训练策略进行了实验。实验结果显示,ConSERT在“仅使用NLI有标注数据”和“使用NLI有标注数据 + STS无标注数据”的两种实验设置下均超过了基线。在三种训练策略的实验设置中,joint-unsup方法取得了最好的效果。
- 少样本实验
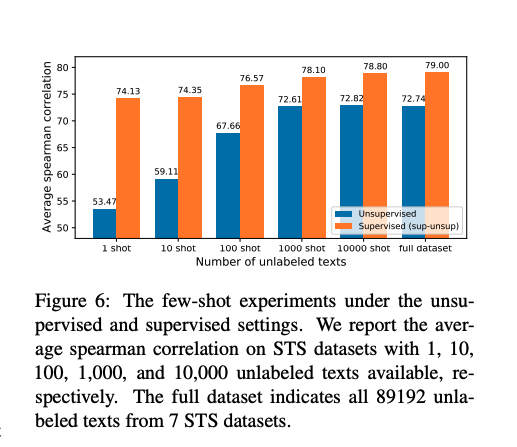
在少样本实验中,本文分别在样本数为1,10,100,1000,1000下进行了实验。结果显示,ConSERT仅需较少的样本就能近似达到全数据量的效果;同时,在样本量很少的情况下(如100条文本的情况下)仍相比于Baseline表现出不错的性能提升。
- 不同数据增强方法实验
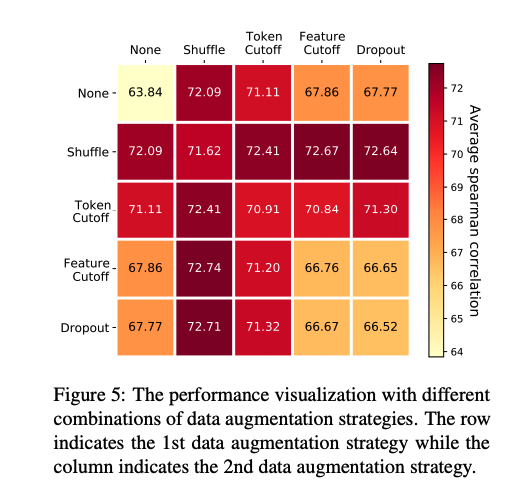
在不同数据增强方法实验中,本文对不同的数据增强组合方法进行了消融分析。结果显示,Token Shuffle和Feature Cutoff的组合取得了最优性能(72.74)。此外,就单种数据增强方法而言,Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None。
- 超参数实验
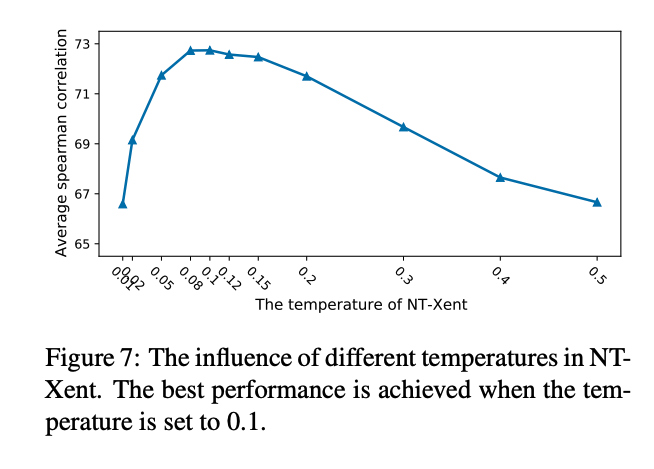
在超参数实验中,从上图可以看出,对比学习损失函数中的温度超参数对于结果有很大影响。当值在0.08到0.12之间时会得到最优结果。这个现象再次证明了BERT表示的Collapse问题,因为在句子表示都很接近的情况下,过大会使句子间相似度更平滑,编码器很难学到知识。而如果过小,任务就太过简单,所以需要调整到一个合适的范围内。
小结
本文作者提出了一种基于对比学习的句子表示方法,通过在目标领域的无监督语料上微调,使模型生成的句子表示与下游任务的数据分布更加适配。实验结果表明,该模型在句子语义匹配任务上取得了state-of-the-art结果,并且在少样本场景下仍表现出较强的性能提升。