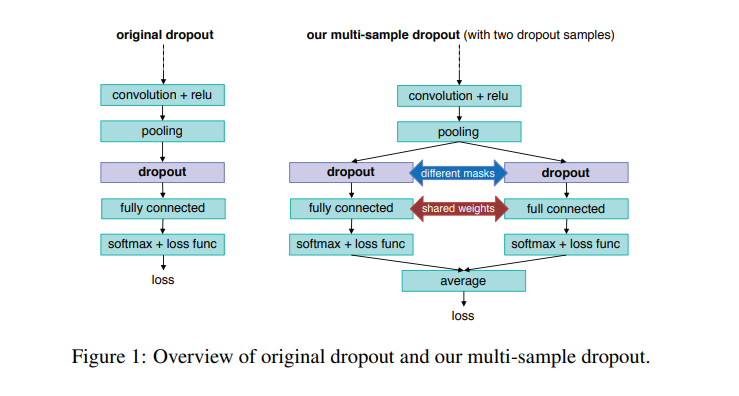
近年来,深度神经网络在各个领域都取得了令人瞩目的成功。在训练大规模的模型时,正则化技术是防止模型过拟合现象不可缺少的模块,同时具备提升模型的泛化(generalization)能力,其中,Dropout 是一个常见的正则化技术。本文作者在Dropout方法的基础上提出了一个正则方法R-Drop(Regularized Dropout),通过在一个batch中,每个数据样本经过两次带有 Dropout 的同一个模型,并使用 KL-divergence 约束两次的输出一致。实验结果表明,R-Drop在5个常用的包含 NLP 和 CV 的任务上(一共18个数据集)取得了不错的效果。
方法
本文作者提出的R-Drop模型结构如下所示:
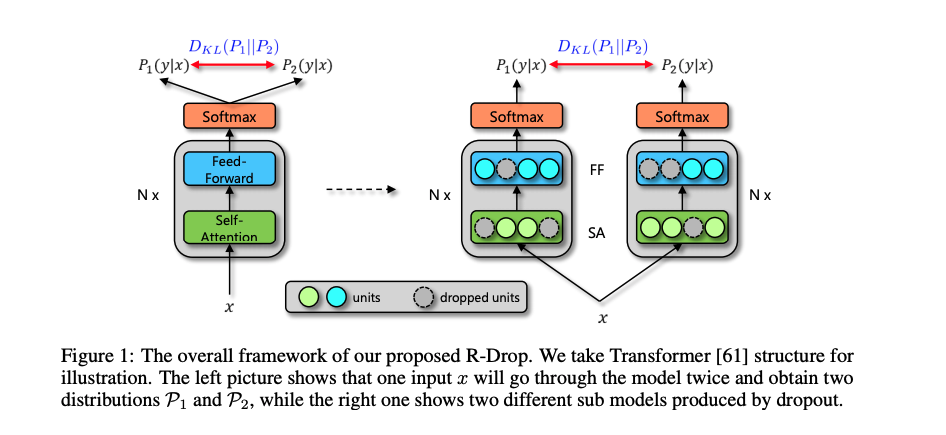
具体来说,当给定训练数据 后,对于每个训练样本 ,会经过两次网络的前向传播,从而得到两次输出预测:和。由于 Dropout 随机性,因此 和 是经过两个不同的子网络(同一个模型)得到的不同的两个预测概率,即对于相同的输入,会得到两个不同的输出和。为了让不同 Dropout 的模型输出尽可能一致,R-Drop 采用了对称的 Kullback-Leibler (KL) divergence 来对 和 进行约束,即:
对于一般任务,常使用最大似然损失函数,即:
因此,最终的训练损失函数为:
其中, 是用来控制 的系数。
因此,整个模型的训练非常简单。在实际实现中,数据 不需要过两次模型,而只需要把 在同一个 batch 中复制一份即可。直观地说,在训练时,Dropout 希望每一个子模型的输出都接近真实的分布,然而在测试时,Dropout 关闭使得模型仅在参数空间上进行了平均,因此训练和测试存在不一致性。而 R-Drop 则在训练过程中通过刻意对于子模型之间的输出进行约束,来约束参数空间,让不同的输出都能一致,从而降低了训练和测试的不一致性(具体理论分析见论文原文,或者参考文献)。
实验
为了验证 R-Drop 的作用,本文作者在5个不同的 NLP 以及 CV 的任务(总计包含18个数据集)上进行了实验:机器翻译、文本摘要、语言模型、语言理解、图像分类。
实验结果
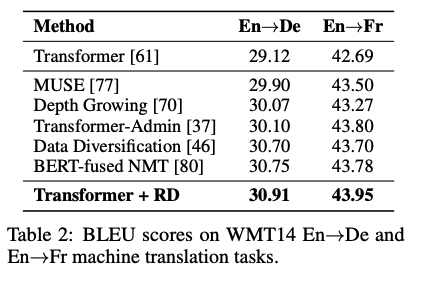
在机器翻译实验中,基于最基础的Transformer 模型,R-Drop 的训练在 WMT14英语->德语以及英语->法语的任务上取得了最优的 BLEU 分数(30.91/43.95),超过了其他各类复杂、结合预训练模型、或更大规模模型的结果。
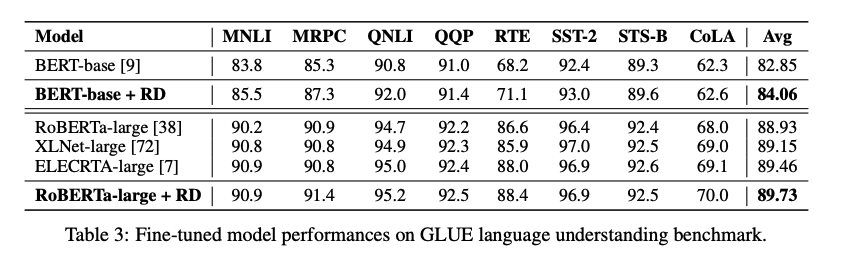
在NLU 语言理解实验中,R-Drop 在预训练 BERT-base 以及 RoBERTa-large 的骨架网络上进行微调之后,在 GLEU 基础数据集上轻松取得了超过1.2和0.8个点的平均分数提升。
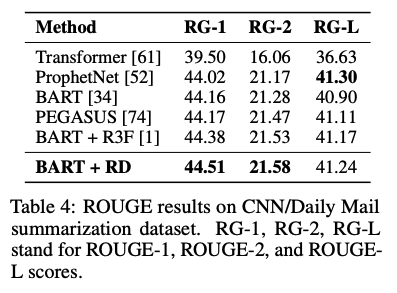
在文本摘要实验中,R-Drop 基于 BART 的预训练模型,在 CNN/Daily Mail 数据上微调之后也取得了当前最优的结果。
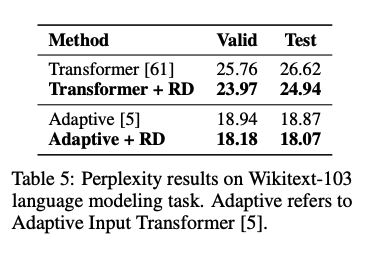
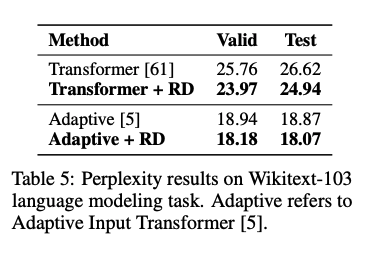
在语言模型实验中,基于原始 Transformer 以及 Adaptive Transformer,R-Drop 的训练在 Wikitext-103 数据集上取得了1.79和0.80的 ppl 提升:
在图像分类实验中,基于预训练好的 Vision Transformer(ViT)为骨架网络,R-Drop 在 CIFAR-100 数据集以及 ImageNet 数据集上微调之后,ViT-B/16 和 ViT-L/16 的模型均取得了明显的效果提升。
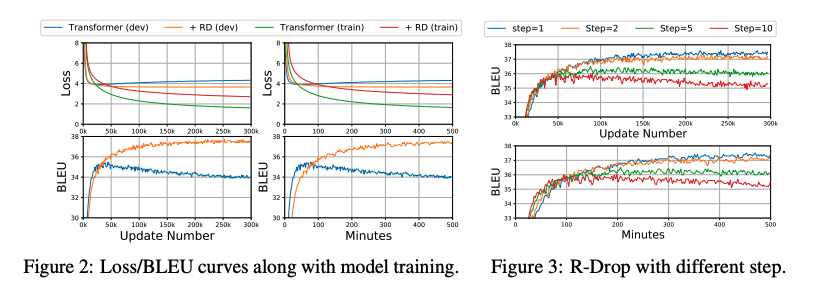
在模型训练过程实验中,从左图可以看出,R-drop能够一定程度上降低过拟合问题,并且R-Drop逐渐提高模型效果,因此需要更多的训练才能收敛。
虽然R-Drop可以获得较强的性能,但收敛性较低,本文作者研究了另一种训练策略,即在每k个step之后应用R-Drop以提高训练效率,而不是在每个step都应用。从上图右可以看出,虽然k越大,收敛速度越快,但模型容易过拟合,因此k不能设置太大。
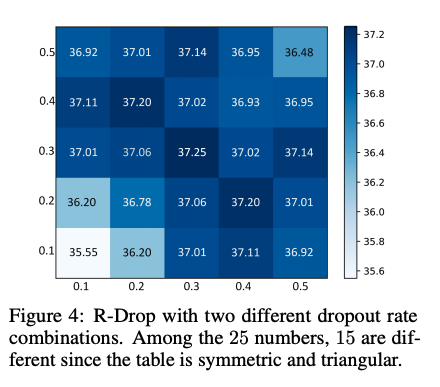
在dropout概率实验中。两个dropout概率同时设置为0.3时达到最优结果,并且设置在合理范围内(0.3∼0.5)且没有较大的性能差异时,R-Drop可以稳定地取得较大的结果。

在参数实验中。当取5时达到了最好的效果,太大或者太小的都会影响模型效果,因此实验时,我们应注意的取值。
小结
本文作者在Dropout方法的基础上提出了一个正则方法R-Drop(Regularized Dropout),通过在一个batch中,每个数据样本经过两次带有 Dropout 的同一个模型,并使用 KL-divergence 约束两次的输出一致。实验结果表明,R-Drop在5个常用的包含 NLP 和 CV 的任务上(一共18个数据集)取得了不错的效果。