在Starter Bundle第10章中,我们提到了训练一个神经网络模型所需要的四个因素,即:
- 数据集
- loss函数
- 神经网络结构
- 优化算法
有了这四个因素,实际上我们是可以训练任何深度学习模型,但是,我们如何训练得到一个最优的深度学习模型?如果效果达不到理想效果,又该如何去优化模型?
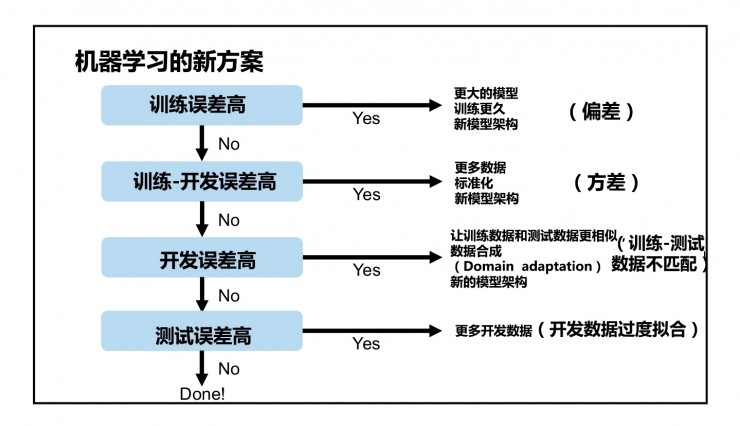
在深度学习实践中,你会发现,深度学习最难的部分其实是如何根据模型的准确性/损失曲线来进行下一步操作。如果模型的训练错误率太高,该如何处理?如果模型的验证错误率很高,又该如何处理?当验证错误率与训练错误率相差不大,而测试集错误率很高,这又该如何处理?
在这一章中,我们将讨论深度学习在应用时的一些技巧,首先是经验准则,根据经验准则来优化模型。然后是决策准则,根据决策准则来决定是从头开始训练深度学习模型还是应用迁移学习。通过本章内容,你将会对专业的深度学习实践者在训练他们自己的网络时使用的经验法则有一个很好的理解。
训练准则
以下内容主要来自于在第30届神经信息处理系统大会(NIPS 2016)中,吴恩达教授发表演讲:《利用深度学习开发人工智能应用的基本要点(Nuts and Bolts of Building Applications using Deep Learning)》。这次演讲的主要内容是:你应该怎样将深度学习用于你的业务、产品或科研?高扩展性的深度学习技术的兴起正在改变人们解决人工智能问题的最佳方式。这包括:如何定义你的训练/开发/测试(train/dev/test)分配,如何组织你的数据,应该如何在各种有希望的模型架构中选择你研究所需的架构,以及甚至你可以怎样开发新的人工智能驱动的产品。在这个 tutorial 中,你将了解到这个新兴领域中涌现出的最佳实践。你还将了解当你的团队在开发深度学习应用时,如何更好地组织你和你的团队的工作。
在构建深度学习应用中,大多数的问题都是训练数据集与测试数据集的分布不相似,当然,有些情况下,两者分布是一致的。但是,在实际中,你会发现往往训练数据集和测试数据集的分布是不同的– Andrew Ng (summarized by Malisiewicz)
Ng和Malisiewicz都提到的是,你应该确保你的训练数据能够代表你的验证集和测试集,也就是说训练数据集和验证数据集、测试数据集类似于同分布的。我们知道数据获取、数据注释和数据标记是一个非常耗时的工作,甚至也是一个昂贵的工作。在某些情况下,深度学习方法很好的进行应用,但是,并不是所有机器学习模型产品都可以获得成功。
例如,假设我们的任务是构建一个深度学习系统,主要功能是识别由摄像机抓拍到行驶在道路上的车辆的类型和品牌。如图8.1左所示:

通过爬取数据,我们不用花费大量的时间在数据标记工作中。然后我们将这个数据集分成两部分:训练集和验证集,接着,对训练数据训练一个深度学习模型,使其达到较高的精度(> 90%)。
然而,当我们将训练好的模型应用到示例图像(如图8.1(左))中时,我们发现结果很糟糕——在实际应用中,我们只获得了5%的准确率。这是为什么呢?
主要原因在于我们的数据,我们从网上爬取的的训练数据集与实际生活中的数据不一致,从Autotrader, CarMax和eBay上爬取的数据(如图8.1,右)并不能代表测试数据集(如图8.1左)。虽然我们的深度学习系统可以很好地识别出像图8.1右的车辆的品牌和类型,但它不能识别出实际生活中摄像头抓拍到的车辆的品牌和类型,比如图8.1左。
如果你希望深度学习系统在给定的真实环境中能够获得高准确度,那么请确保这个深度学习系统是针对其实际应用的真实图像数据集进行训练的——否则你可能会得到很差的性能。
假如我们已经收集了足够的训练数据集,这些数据代表了我们正在尝试解决的分类任务,Andrew Ng提供了一个四步过程来帮助我们进行训练[34]。
- 训练数据集
- 训练-验证数据集 (也就是Ng提到的开发数据集)
- 验证集
- 测试集
前面,我们训练模型时使用到了训练数据集,验证数据集和测试数据集,原本是只有三组数据集,这里提到了一种新的数据集——”训练-验证“数据集,这种新的“训练-验证”数据集是什么呢?Ng建议我们将所有的数据按照6-4划分,即60%用于训练和40%用于测试。然后再将测试数据分成两部分:一部分用于验证,另一部分用于真正的测试(这一部分数据是当做完全未知的)。接着,我们从训练集中取出一小部分,并将其添加到我们的“训练-验证集”中。训练集主要用来评估模型的偏差,而训练-验证集主要用来评估模型的方差。比如:
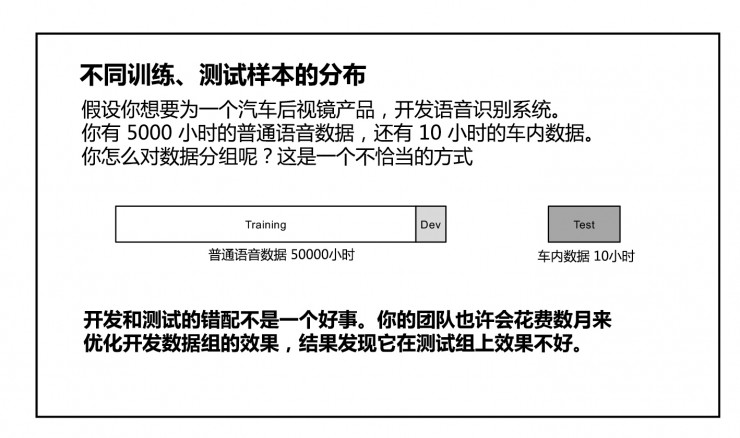
假设你想要为一个汽车后视镜产品,开发语音识别系统。你有 5000 小时的普通语音数据,还有 10 小时的车内数据。你怎么对数据分组呢?这是一个不恰当的方式:
更好的方式:让开发和测试集来自同样的分配机制。

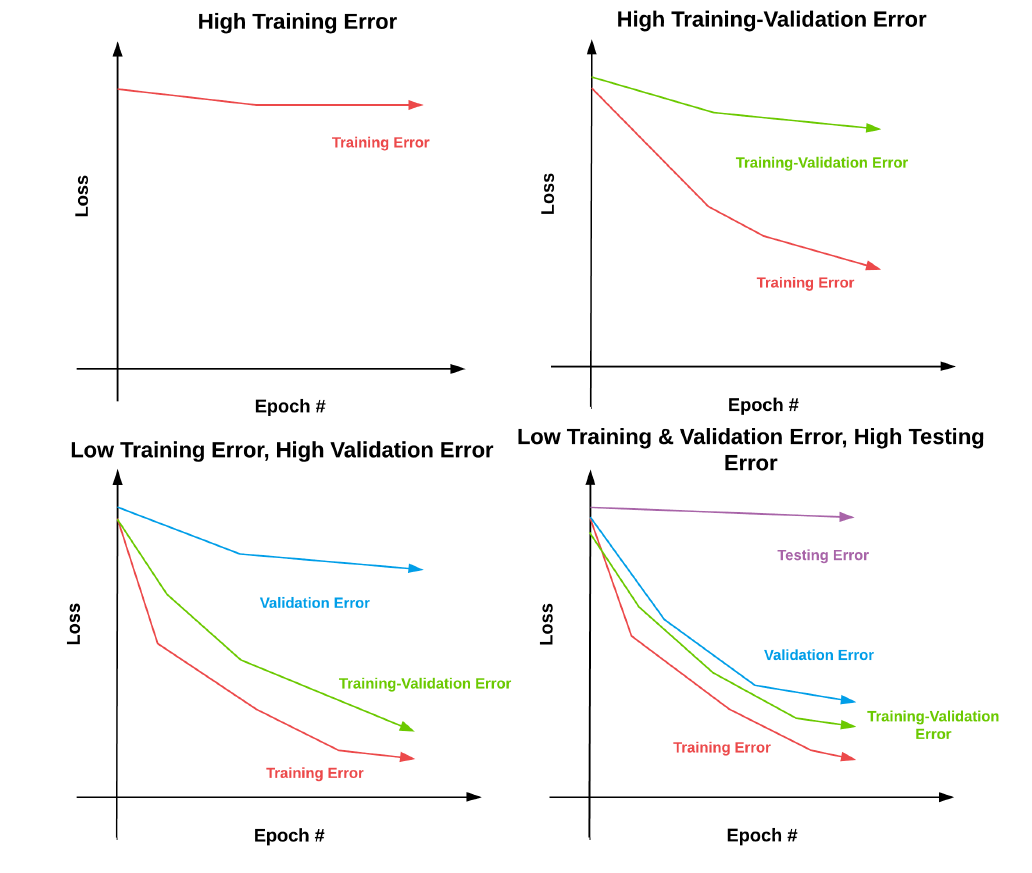
如图8.3左上角所示,那么我们可以考虑通过添加更多的层和神经元来加深我们当前的模型结构。我们也可以考虑加大训练时间(比如训练更多的epochs)并调整我们的学习率——使用更小的学习率可以让你训练更长时间,同时有助于防止过拟合。如果对当前的模型结构和学习率进行了多次实验之后,发现并没有多大作用,那么我们可能需要尝试一种完全不同的模型结构。
- 如果模型的训练-验证错误率很高
如图8.3右上角所示,一般而言,这种情况往往是模型发生了过拟合现象,可以考虑对模型加入正则化技术。比如使用Dropout技术,或者使用数据增强来增加数据量,或者对loss函数增加正则化项。当然我们需要通过实验来衡量哪种正则化技术好或者哪几种组合使用较好。
您还可以考虑收集更多的训练数据(再一次注意这些训练数据需要与实际数据相符合)——一般情况下,训练数据当然是越多越好。若还无法达到想要的效果,这时候可能需要考虑尝试一种完全不同的模型结构。
- 如果模型的训练-验证错误率很低,但是验证集错误率很高
如图8.3左下角所示,一般这种情况,我们需要更仔细地检查我们的训练数据。训练数据是否与验证数据相似?
我们都知道,如果训练数据集与验证数据集、测试数据集的分布不同,那么我们训练再好的深度学习模型都无法再实际数据中获得良好的结果。那么,这时候我们需要花时间收集更多的数据。另外,我们还可以核查正则化参数——正则化足够强吗?最后,我们也可以尝试新的模型架构。
- 如果模型的测试错误率很高
如图8.3右下角所示,模型在训练集和验证集上的错误率很低,但是在测试数据集上的错误率很高,有可能是模型发生了过拟合问题。因此,我们需要收集更多的验证集数据,以确定何时开始出现过拟合问题。
使用Andrew Ng提出的这种方法,当我们的实验没有如我们预期的那样进行时,我们可以更容易地就更新模型/数据集做出(正确的)决策。
迁移学习或从新训练
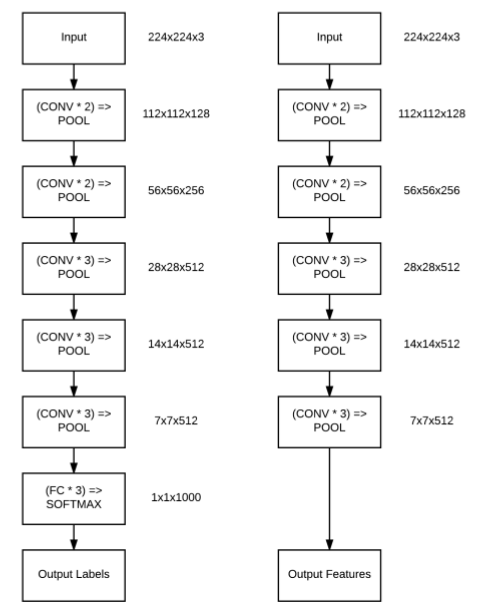
以下部分内容受斯坦福cs231n“迁移学习”课程的启发。从第3章关于特征提取和第5章关于微调中我们看到了使用迁移学习可以带来更高的准确度,那么什么时候应该使用迁移学习,什么时候应该从头开始训练模型。
如何判断?你需要考虑两个重要的因素:
- 数据集的大小。
- 新的数据集与预训练CNN模型的原始数据是否相似(通常是ImageNet数据)。
基于这些因素,我们通过一个图表来帮助我们决定是否需要应用迁移学习或从头开始训练(图8.4)。主要有以下四种可能性:

由于新的数据集很小,所以可能没有足够的训练数据来从头开始训练CNN(在深度学习实践中,理想情况下,每个类应该有1000 - 5000个样本)。此外,由于只有小量训练数据,尝试微调可能不是一个好主意,因为我们可能最终会发生过拟合问题。
相反,由于数据与预训练模型的训练数据相似度很高,因此,我们应该将网络视为一个提取特征器,并基于特征数据训练一个简单的机器学习分类器。需要注意的是,我们应该从预训练模型中更深的层中提取特征,因为往往这些特征具有很强的区分能力。
- 数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效,我们有足够的例子来应用微调而不发生过拟合问题。你可能也想从头开始训练自定义模型——这是一个值得进行的实验。但是,由于新的数据集与pre-trained model的训练数据相似,网络内部的filters可能已经具有足够的识别能力,从而获得一个合理的分类器。因此,最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上进行微调。
- 数据集小,数据相似度不高
同样,对于一个小的数据集,我们无法通过从头开始训练来获得一个高精度的深度学习模型。相反,我们应该再次应用特征提取并在它们之上训练一个标准的机器学习模型——但是由于新的数据与原始数据集不同,我们应该使用网络中较低的层作为特征提取器。
请记住,网络层越深,特征就越丰富且越细[对原始数据集有可能过拟合的风险],因此,由于新的数据集与原始数据集相似度不高,我们应该从网络中较低的层提取特征,而不能使用较深的层提取到的抽象特征。
- 数据集大,数据相似度不高
在这种情况下,我们有两个选择。考虑到我们有足够的训练数据,我们可以从头开始训练自定义网络架构。另外,我们可以从大数据集中(比如ImageNet)训练的模型中得到的权重作为权重初始化,即使这些数据集是不相关的。因此,我们进行两组实验:
- 在第一组实验中,对新的数据集尝试调整一个预先训练网络,并评估性能。
- 在第二组实验中,从头开始训练一个全新的模型并进行评估。
究竟哪种方法好呢?完全取决于你的数据集和分类问题。但是,我建议您首先尝试进行微调,因为微调相对于重新训练而言,可以快速得到一个结果,而且,可以把第一组实验结果当做一个baseline,然后根据baseline进行第二组实验。
总结
在本章中,我们探索了应用深度学习最佳途径。在收集训练数据时,请确保用于训练模型的数据能够代表在实际应用中的数据。如果你的输入数据与你的实际数据分布不同,那么你的深度学习模型不可能在实际数据上表现得很好。
我们还回顾了何时应该考虑迁移学习,而不是从头开始训练自己的网络。对于小数据集,您应该考虑特征提取。对于较大的数据集,首先考虑进行微调(建立baseline),然后再从头开始训练模型。