从这节开始,我们将讨论关于迁移学习的内容,即用预先训练好的模型(往往是在大型数据上训练得到的)对新的数据进行学习.
首先,从传统的机器学习场景出发,即考虑两个分类任务:
-
第一个任务是训练一个卷积神经网络来识别图像中的狗和猫。
-
第二个任务是训练一个卷积神经网络识别三种不同的熊,即灰熊、北极熊和大熊猫。
正常情况下,当我们使用机器学习、神经网络和深度学习等进行实践时,我们会将这两个任务视为两个独立的问题。首先,我们将收集足够多的带有标记的狗和猫的数据集,然后在该数据集上训练一个模型。一般而言,对于不同的数据,都是不断地重复这个过程,即在第二个任务中,收集足够多的带有标记的熊品种的数据集,然后在该数据集上训练一个模型。
上面两个任务中,我们独立地对每一个任务收集数据,训练模型,两个任务之间是相互独立的。而迁移学习却是另外一种不同的训练模式——假如我们加载现有预先训练好的模型,并将其作为新分类任务的训练拟合过程开始点?比如上面两个任务,首先,我们在猫和狗的数据集上训练一个卷积神经网络。然后,我们使用从猫和狗数据集中训练得到的卷积神经网络去区分熊的种类,注意的是:训练模型的数据并没有把熊数据与狗和猫的数据进行混合。
是不是听起来很神奇?两个不同任务之间可以存在关联,实际上并不是。在目前迁移学习任务中,在大型数据集(如ImageNet)上训练得到的深度神经网络是相当优秀的。这些模型学习到了一组丰富的、有区分度的特征来识别1000个不同的类别数据。因此,我们可以考虑将这些模型重新用于新的分类任务中而不用重新开始训练CNN模型。
一般来说,在计算机视觉任务中,深度学习相关的迁移学习主要有两种类型:
- 1.将网络当作特征提取器。
- 2.删除现有网络的全连接层,添加新的FC层,并微调这些权重识别新的类别数据。
说明:第2种类型即当我们使用现有的模型进行新的分类任务时,我们控制全连接之前的模型权重不变,而利用新的数据对新的全连接层的权重进行微调(当然也可以选择微调全连接层之前的)。
在本章的后面,将演示如何使用预先训练好的CNNs(特别是VGG16)和Keras库对图像数据集(如Animals、CALTECH-101和Flowers-17)提取特征,并对特征数据训练模型。需要说明的是这三个数据集都不包含在用于训练VGG6网络的图像数据中。以往,遇到新的分类任务时,一般的流程都是重新构建模型以及对模型从头开始训练,这种方式即耗时又耗精力,但是通过转移学习,我们可以不费多大力气就可构建出高精度的图像分类器。诀窍在于特征的提取,另外,对于提取到特征,我们主要使用HDF5进行存储。
这一节,我们主要关注第一种迁移学习方法,将网络视为特征提取器。然后,我们将在第5章讨论如何根据特定的分类任务对网络的权值进行调整。
CNN模型提取特征
到目前为止,我们都是把卷积神经网络当作一个端到端的图像分类器来使用,即:
- 1.对模型输入一张图片
- 2.图片通过前向传播遍历整个网络
- 3.获得网络的分类概率结果
但是,图像一定需要在整个网络中传播吗?其实,我们可以中断在任意层(如激活层或池化层)的传播,并从当前网络层中提取信息当作特征向量。例如,我们考虑VGG16网络架构(图3.1,左)。
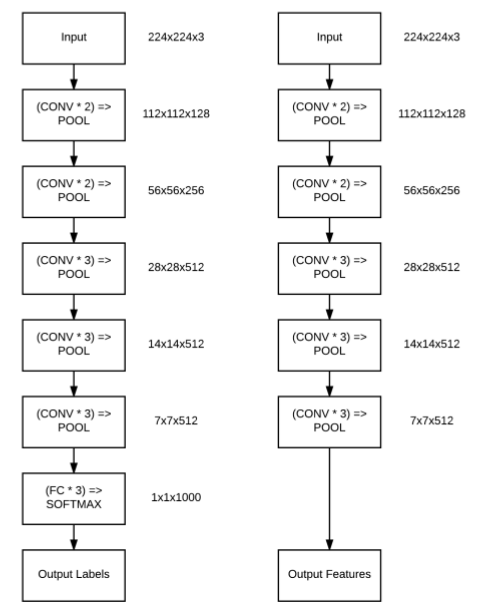
在图3.1右中,我们将最大池化层当作最后一层,其中输出的shape为7×7×512,说明有512个大小为7x7的过滤器。我们可以将这些7×7×512 =25088个值当作一张图像的矢量化表征。
假如有N张图像,不断地重复这个过程,将得到一个Nx25088的矩阵,其中25088列用来表征每一张图像的内容(即我们常说的特征向量)。得到特征向量矩阵之后,我们可以利用这些特征向量训练一个现成的机器学习模型,如支持向量机、逻辑回归或随机森林等,从而获得一个新的图像识别模型。
备注: 我们截断的CNN网络(如图3.1右)本身并不能识别这些新类别数据,相反,我们使用截断的CNN网络模型作为中间特征提取器,并在特征上训练一个机器学习模型来识别这些新类别数据。
下面将演示如何使用预先训练好的CNN模型(特别是VGG16)和Keras库来对图像数据集(如动物、CALTECH-101和Flowers-17)进行识别,并获得约95%的分类精度。在对图像数据提取特征之前,我们先来介绍下存储特征的工具——HDF5。
HDF5
HDF5是二进制数据格式,用于在磁盘上存储巨大的数值数据集(数据太大无法存储在内存中),同时便于对数据集的行进行遍历和计算。HDF5中的数据是分层存储的,类似于文件系统存储数据的方式。它可以存储两类数据对象;
-
1.dataset:类比于文件系统中的文件,可以操作list/ndarray的方式老操作它
-
2.group:类比于文件系统的文件夹,可以用操作dict的方式来操作它
数据是定义在group中,group类似层次容器的结构,可以包含零个或多个group或dataset的实例,以及支持元数据(metadata)。一旦定义了一个group,就可以在group中创建一个dataset。dataset可以理解为是一个多维数组(例如一个NumPy数组),注意:同一个多维数组中数据类型是相同的(整数、浮点数、unicode等)。图3.2显示了一个包含具有多个dataset的group的HDF5文件示例。本文我们将编写一个定制的Python类,使我们能够有效地接受输入数据并将其写入HDF5数据集。

这个标准库最主要的一点在于开发者对它的积极维护以及在向下兼容方面花费的巨大精力。标准库的向下兼容不仅仅是API的兼容,亦包括文件格式的兼容,这意味着以HDF5格式存储的数据集本质上是可移植性的,可以被使用不同编程语言(如C、MATLAB和Java)的其他开发人员访问。
接下来,我们将自定义一个Python类,使我们能够有效地接受输入数据并将其写入HDF5数据集。该类的主要功能有两个:
-
1.提取VGG16中的特征并以有效的方式将其写入HDF5数据集,方便我们进行迁移学习。
-
2.直接对原始图像生成HDF5数据集,可以加速训练速度。
使用HDF5保存特征
在提取VGG16(其他CNN)网络特征之前,我们先定义存储特征的模块—HDF5DatasetWriter类,顾名思义,它负责接收一组NumPy数组(无论是特征、原始图像等)并将它们写入HDF5格式。同样,在pyimagesearch项目中创建一个新的子模块io,并在io模块中新建一个名为hdf5datasetwriter.py的文件,如下结构所示:
1 | --- pyimagesearch |
打开hdf5datasetwriter.py,写入以下代码:
1 | #encoding:utf-8 |
HDF5DatasetWriter类主要有四个参数,其中两个参数可选,两个参数必选。
- dims:数据的维度,可以将dims看作NumPy数组的.shape。
如果我们存储原始的28x28=784MNIST数据集,即28x28的矩阵被拉平为(784,)向量,则dims=(70000,784),其中70000表示样本总数,784表示每个样本的维数。如果我们想存储原始CIFAR-10图像数据,则dims=(60000,32,32,3),即总共有60000图像样本,每个样本为32×32×3的RGB图像。
上文中提到,我们将使用VGG16网络的最后一个池化层的输出作为特征向量,从图3.1右中可以看到最后一个池化层的输出是512×7×7,拉平之后产生一个长度为25088的特征向量。因此,在使用VGG16进行特征提取时,我们将设置dims=(N, 25088),其中N为数据集中的图像总数。
- outputPath:输出HDF5文件将存储在磁盘上的路径。
- dataKey:用来表示数据集的名称。默认值为“images”
在大多数情况下,我们将以HDF5格式存储原始图像,所以默认值为‘image’,在本例中,主要使用HDF5DatasetWriter来保存从CNN中提取到的特征,因此。这里将设设置为dataKey = "features’。
- bufSize:缓存的大小,默认为1000个特征向量或者原始图像,当达到bufSize时,将缓存数据写入HDF5数据集中。
接下来,实现add方法,主要是将数据add到buffer中:
1 | def add(self,rows,labels): |
add主要包含两个参数:
- rows:行数据
- labels:对应的标签
如果缓冲区buffer被填满,则调用flush方法将缓冲区写入文件并重新设置它们。flush方法如下:
1 | def flush(self): |
把HDF5数据集看作一个大的NumPy数组,那么需要将当前索引跟踪到下一个可用的行,定位到新的数据(不重写现有数据)。
接下来定义一个函数storeClassLabels,主要在存储类标签的原始字符串名称:
1 | def storeClassLabels(self,classLabels): |
最后,关闭dataset:
1 | def close(self): |
正如你所看到的,HDF5DatasetWriter类与机器学习和深度学习没有多大关系——它只是一个用来帮助我们以HDF5格式存储数据的类。当你不断地实践深度学习任务时,你会注意到,当建立一个新问题时,你要做的大部分工作就是把数据转换成你可以使用的格式。一旦你的数据以一种易于操作的格式进行,那么你将更加容易地将机器学习和深度学习技术应用到数据中。
因此,HDF5DatasetWriter类是一个实用类,并不是针对深度学习和计算机视觉的。现在我们的HDF5DatasetWriter已经实现,接下来我们将使用预先训练好的卷积神经网络来提取特征。
特征提取
定义一个Python脚本,该脚本可用于从任意图像数据集中提取特征(如果输入数据集遵循特定的目录结构)。打开一个新文件,名为extract_features.py,并写入以下代码:
1 | #encoding:utf-8 |
其中progressbar是以个很实用的模块,提供基于文本的可视化进度条,通常用在显示下载进度、显示任务的执行进度等等。比如:
1 | Extracting Features 30% |############ | ETA: 0:00:18 |
接下来,定义命令行参数:
1 | ap = argparse.ArgumentParser() |
extract_features.py脚本总有四个命令行参数,两个必选,两个可选,其中:
- –dataset:输入图像数据路径
- –ouput: 保存HDF5数据文件路径
- –batch_size: 一次输入模型的图像个数,默认值为32,可以很据你的显存或者内存大小进行调整
- –buffer_size:控制提取特征或者图像在内存中的大小
接着,从磁盘中获取数据,并进行混洗以及对标签进行编码:
1 | bs = args['batch_size'] |
iamgePaths读取的是磁盘上所有图片的路径数据,然后进行混洗,需要说明的是由于数据太大,我们无法把所有数据都加载到内存中进行混洗,因此,采取的策略是在提取特征之前,对图像的路径进行混洗。上述从路径中提取图像标签,需要对数据的路径满足一定的结构,如下:
1 | dataset_name/{class_label}/example.jpg |
接下来,加载VGG16网络权值,并初始化HDF5DatasetWriter:
1 | # 加载 VGG16网络 |
首先,我们从磁盘中加载预先训练好的VGG16网络,其中需要注意的是参数include_top=False——False表明model不包含最后三个全连接层。因此,当对模型输入一张图像时,我们将获得最后一个池化层的特征值,而不是FC层中softmax分类器产生的概率。
备注: 若磁盘不存在VGG16网络,则脚本会自动下载,模型保存的路径主要在;~/.keras/model/中
接下来进行特征提取:
1 | # 初始化进度条 |
初始化进度条,这样可以查看整个数据集提取特征的进度信息。下面进行图像数据预处理:
1 | for (j,imagePath) in enumerate(batchPaths): |
图像预处理跟上节内容差不多,主要是新增一个维度和标准化。
注意: 这里的标准化,需要调用预训练VGG16模型的数据进行标准化,保证数据一致性。
保存特征:
1 | # 使用模型的预测值作为特征向量 |
我们使用numpy.vstack方法来“垂直叠加”图像数据,使它们具有形状(N, 224, 224, 3),其中N是batch的大小。
调用model.predict方法得到batch大小的特征向量集合——注意,我们删除了VGG16的全连接层,所以得到的特征向量是最后一个最大池化层输出的值。但是,最大池化层输出的形状是(N,512 7,7),这意味着有512个大小7×7的过滤器。要将这些值转化为特征向量,我们需要将它们拉平成一个具有形状(N, 25088)的数组,即reshape((features.shape[0],512 * 7* 7))。
提取特征代码完成之后,我们将使用预先训练好的CNN模型从各种数据集中提取特征。
提取特征
首先,我们将使用VGG6模型对“animals”数据集提取特征,该数据集由3000张图片组成,包括三个类别:狗、猫和熊猫。执行以下命令,以获取特征向量:
1 | python extract_features.py --dataset youPath/data/animals/images \ |
执行玩之后,在animals/hdf5目录,您将看到一个名为features.hdf5的文件:
1 | ls youpath/data/animals/hdf5/ |
新开一个python shell,用来查看.hdf5数据的信息:
1 | python |
可以看到HDF5数据文件中包含三个dataset: features、label_names、labels。
从CALTECH-101中提取特征
与前面一样,运行下面命令,就可以得到CALTECH-101数据的特征,我们只需要修改数据的路径即可,:
1 | python extract_features.py --dataset youPath/data/caltech-101/images \ |
从Flowers-17中提取特征
运行下面命令进行特征提取:
1 | python extract_features.py --dataset youPath/data/flowers17/images \ |
训练模型
上面我们使用了预训练好的VGG16模型对animals、CALTECH-101和FLowers-17S数据集提取了特征。接下来,我们将对这些特征数据构建一个机器学习模型进行分类。
新建一个脚本,名为train_model.py,并写入下面代码:
1 | #encoding:utf-8 |
首先,加载所需要的模块,一开始我们使用简单的逻辑回归模型进行分类。
命令行解析参数;
1 | ap = argparse.ArgumentParser() |
其中:
- –db: hdf5数据的路径
- –model: 保存模型路径
- –jobs:模型调优时的并发数,默认-1值表示使用全部资源数
将数据划分为train和test数据:
1 | db = h5py.File(args['db'],'r') |
可以看到这里的划分数据跟之前使用train_test_split不一样,主要是数据太大,我们无法加载到内存中进行混洗。前面提到过在将相关的图像/特征向量写入HDF5数据集之前,我们对图像路径数据进行了混洗了——从而我们直接利用第二行代码划分数据即可。混洗完之后将使用前75%的数据作为train数据集,后25%的数据作为test数据集。
下面,我们将加载模型;
1 | # 模型调优 |
将模型保存到磁盘中,方便下次调取使用:
1 | # 保存模型到磁盘 |
完成模型训练部分代码之后,我们将对上面提取好的特征数据进行训练,并查看结果.
Animals数据结果
对Animals提取到的特征数据进行模型训练,运行下面命令;
1 | python train_model.py --db youPath/data/animals/hdf5/features.hdf5 \ |
将得到如下结果:
1 | precision recall f1-score support |
CALTECH-101的结果
运行下面命令:
1 | python train_model.py \ |
总结
在这一章中,我们讨论了迁移学习,主要使用预先训练好的卷积神经网络对新的类别数据进行分类。一般来说,在计算机视觉任务中,深度学习相关的迁移学习主要有两种类型:
- 1.将网络当作特征提取器。
- 2.删除现有网络的全连接层,并添加新的FC层,并微调这些权重识别新的类别数据
这节我们主要集中讨论关于特征提取内容,通过例子证明了卷积神经网络,比如VGG,Inception和ResNet,能够作为强大的特征提取模型,甚至比手工提取特征方法,比如HOG[14],SIFT[15]和Local Binary Patterns[16]等更加有效。当遇到深度学习特别是与卷积神经网络相关的问题时,可以考虑应用特征提取,然后训练机器学习算法,看看是否能够获得合理的准确度——如果可以,那么我们完全可以跳过网络训练过程,从而节省大量的时间和精力。
本文数据下载地址: googleDrive
本文完整的代码地址: github