在第3节 中,我们学习了如何将预训练好的卷积神经网络作为特征提取器。通过加载预训练好的模型,可以提取指定层的输出作为特征向量,并将特征向量保存到磁盘。有了特征向量之后,我们就可以在特征向量上训练传统的机器学习算法(比如在第3节 中我们使用的逻辑回归模型)。当然对于特征向量,我们也可以使用手工提取特征方法,比如SIFT[15],HOG[14],LBPs[16]等。
一般来说,在计算机视觉任务中,深度学习相关的迁移学习主要有两种类型:
1.将网络当作特征提取器。
2.删除现有网络的全连接层,添加新的FC层,并微调这些权重识别新的类别数据。
第3节 中,介绍了第一种方法。下面我们介绍另一种类型的迁移学习,如果有足够的数据,它实际上可以超越特征提取方法,这种方法称为微调,即我们利用新的数据对网络权重进行微调。首先,我们对预训练好的卷积神经网络(如VGG,ResNet或Inception等,一般是在大型数据集上训练得到的)的最后一组全连接层做截断处理(即删除网络中的top层),然后,我们用一组新的全连接层与截断的已训练好的模型进行拼接,组成一个新的完整模型,并随机初始化权重[注意 :这里的初始化权重只初始化新增的全连接层权重],全连接层即Top部以下的所有层权重都被冻结,一般而言,训练时候是不更新,即后向传播是不在训练好的模型之间进行传播的。
在微调过程中,一般使用非常小的学习率来训练网络,这样新的全连接层就可以开始从已训练好的网络中学习新的模式。当然我们也可以对其他层的权重进行训练,这可能需要根据具体的数据来设置。利用微调技术,我们就不用重新开始训练模型,即可以节省大量的时间和精力,又可以获得更高的准确度。
在本章的其余部分,我们将更详细地讨论微调方法,以及如何对网络进行处理。最后,我们将应用于Flowers-17数据集中。
迁移学习和微调
微调方法是迁移学习的另一种类型。对于新数据集,我们首先加载预先训练好的模型,这时加载的模型一般并不适合于新数据,但是,该模型又具有良好的特征学习能力,想要保持该模型的强大区分能力,那怎么做呢?我们首先删除已有模型的全连接层,冻结剩余层的权重(包括在训练过程),然后构建一组新的全连接层,与已有的截断模型进行拼接,并对新的全连接层的权重进行初始化,最后,给定较小的学习率,将‘新’模型在新的数据上进行训练。通常,使用的预训练好的网络都是当前比较好的网络,如VGG、ResNet和Inception等,它们已经在大型数据集ImageNet上训练过。
正如我们在第3节 讨论,这些预训练好的网络结构包含大量具有判别能力的过滤器,这些过滤器可用于新的数据集[虽然过滤器无法对新数据进行预测,但是可以提取有用的特征]。在这节,我们将对预训练好的网络结构进行修改,这样我们只需要训练修改的的部分网络参数,而不是重新开始训练整个网络。
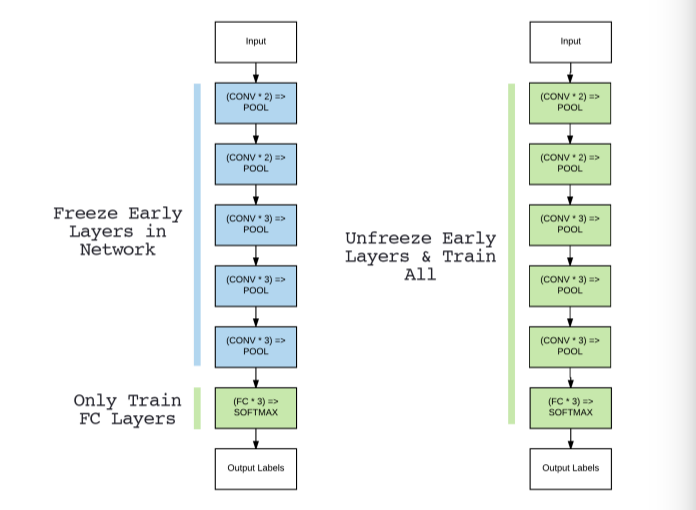
图5.1 左:原始的VGG16网络结构, 右:网络结构的调整
我们以图5.1来理解微调是如何工作的。图5.1显示的是VGG16网络。从左图可以看到,最后一组(即“头”部分)主要是由全连接层和sofrmax分类器组成。使用微调方法时,我们对已有模型的网络结构进行修改,主要是删除头部,就像在[第3节](http://lonepatient.top/2018/02/25/Deep_Learning_For_Computer_Vision_With_Python_PB_03.html)提到的提取特征一样操作。然而不同的是,微调过程中,我们**实际上构建了一个新的由全连接层和softmax分类器组成的‘头’部,并与原始结构进行拼接,如图5.1右所示。**
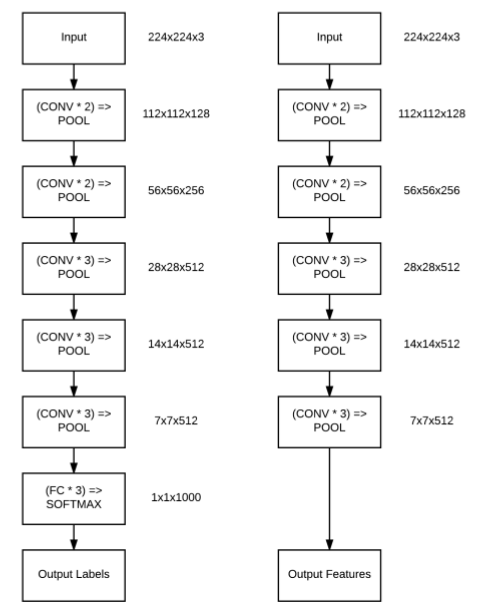
在大多数情况下,新增的头部全连接层的参数会比原来的参数更少[当然实际上取决于你的特定数据集]。在大型数据上训练得到的模型往往具有强大的区分能力,而新增的全连接层是全新的且完全随机的。如果我们让这些随机值的梯度反向传播到整个网络,那么就可能破坏这些强大的特征。为了避开这个问题,我们仅训练头部全连接层参数,而“冻结”网络中其他层权重,如图5.2(左)所示。
图5.2 左:冻结所有conv层,微调全连接层, 右:全网络进行微调(调整全连接层之后)
微调训练过程中,前向传播是在整个网络之间进行传播,但是,后向传播只在新的全连接层之间进行,这样全连接层就可以从具有高区分能力的Conv层中学习特征。一般情况下,整个训练过程中,都不对全连接层之外的层进行训练。因为新的全连接层可能已经获得了相当好的准确度。但是,对于某些数据集,微调部分原始层参数可能会得到更好的效果,比如图5.2右。
当前面的FC层训练完之后,我们可以考虑微调部分原始网络的层权重,让原始网络也对新的数据进行学习。为了不让原始Conv层的过滤器发生明显的变化,设置非常小的学习速率,继续训练,直到获得足够好的准确度。
可见,我们可以利用预训练好的CNNs模型对自定义数据集经过微调得到新的图像分类器,在大多数情况下可以比提取特征方式获得更高的准确度。当然,微调也存在缺点,由于我们对网络结构进行了一定修改,如何确定需要修改的部分网络结构以及重新训练模型都是需要时间投入,从实践中得到一个相对好的“新”模型,且新的FC层参数的选择对网络精度存在重要影响。
其次,对于小数据集,从网络顶部就开始训练分类器可能不是最好的选择,这包含更多的数据集特定特征。另外,从网络前部的激活函数开始训练分类器可能更好一点。
索引
在对网络结构进行修改之前,我们需要了解网络的结构,即每一层对应的名字和位置。因为我们将根据网络层对应的索引对预训练好的模型某些层的权重进行“冻结”或“解冻”操作。
接下来,我们打印VGG16中的层名和索引。新建一个名为inspect_model.py文件,写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from keras.applications import VGG16import argparseap = argparse.ArgumentParser() ap.add_argument('-i' ,'--include_top' ,type = int ,default=1 ,help ='whether or not to include top of CNN' ) args = vars (ap.parse_args()) print ('[INFO] loading network...' )model = VGG16(weights='imagenet' ,include_top=args['include_top' ]>0 ) print ("[INFO] showing layers..." )for (i,layer) in enumerate (model.layers): print ("[INFO] {}\t{}" .format (i,layer.__class__.__name__))
对于网络中的每一层,输出相应的索引i。根据这些信息,我们就会知道FC层从哪里开始。
执行下面命令,将在输出界面显示VGG16的网络结构:
1 $ python inspect_model.py
结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [INFO] showing layers... [INFO] 0 InputLayer [INFO] 1 Conv2D [INFO] 2 Conv2D [INFO] 3 MaxPooling2D [INFO] 4 Conv2D [INFO] 5 Conv2D [INFO] 6 MaxPooling2D [INFO] 7 Conv2D [INFO] 8 Conv2D [INFO] 9 Conv2D [INFO] 10 MaxPooling2D [INFO] 11 Conv2D [INFO] 12 Conv2D [INFO] 13 Conv2D [INFO] 14 MaxPooling2D [INFO] 15 Conv2D [INFO] 16 Conv2D [INFO] 17 Conv2D [INFO] 18 MaxPooling2D [INFO] 19 Flatten [INFO] 20 Dense [INFO] 21 Dense [INFO] 22 Dense
从结果中可以看到,20-22层是全连接层。接下来,将–include_top设置为-1,即不返回FC层:
1 $ python inspact_model.py --include_top -1
得到的结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [INFO] showing layers... [INFO] 0 InputLayer [INFO] 1 Conv2D [INFO] 2 Conv2D [INFO] 3 MaxPooling2D [INFO] 4 Conv2D [INFO] 5 Conv2D [INFO] 6 MaxPooling2D [INFO] 7 Conv2D [INFO] 8 Conv2D [INFO] 9 Conv2D [INFO] 10 MaxPooling2D [INFO] 11 Conv2D [INFO] 12 Conv2D [INFO] 13 Conv2D [INFO] 14 MaxPooling2D [INFO] 15 Conv2D [INFO] 16 Conv2D [INFO] 17 Conv2D [INFO] 18 MaxPooling2D
可以看到,网络最后一层为Pool层。我们后面将使用上面的模型结构。
实验
在替换预训练好的模型"头"部分之前,我们先定义一个新的‘头’。创建一个名为fcheadnet.py文件,放入pyimagesearch项目中的nn.conv子模块中,结构如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 --- pyimagesearch | |--- __init__.py | |--- callbacks | |--- io | |--- nn | |--- __init__.py | |--- conv | |--- __init__.py | |--- lenet.py | |--- minivggnet.py | |--- fcheadnet.py | |--- shallownet.py | |--- preprocessing | --- utils
并写入以下代码:
1 2 3 4 5 from keras.layers.core import Dropoutfrom keras.layers.core import Flattenfrom keras.layers.core import Dense
下面,定义FCHeadNet 类:
1 2 3 4 5 6 7 8 9 10 11 class FCHeadNet : @staticmethod def build (baseModel,classes,D ): headModel = baseModel.output headModel = Flatten(name='flatten' )(headModel) headModel = Dense(D,activation='relu' )(headModel) headModel = Dropout(0.5 )(headModel) headModel = Dense(classes,activation='softmax' )(headModel) return headModel
其中:
baseModel:网络的主体,比如上面的VGG16(只到18层)
classes:数据集中的类别个数,比如Flowers-17的类别个数为17
D:全连接层的节点数
新构建的网络结构如下:
1 INPUT => FC => RELU => DO => FC => SOFTMAX
新的全连接层比原始的VGG16的全连接层相对要简单点,原始的VGG16包含两组4096个节点的FC层。大多数我们进行微调操作时,并不是要复制原始网络的"头"结构,而是要简化它,以便更容易进行微调——头中的参数越少,我们就越有可能正确地将网络调优到适合新的分类任务。
训练
新建一个名为finetune_flowers17.py的文件,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from sklearn.preprocessing import LabelBinarizerfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportfrom pyimagesearch.preprocessing import ImageToArrayPreprocessor as ITAPfrom pyimagesearch.preprocessing import AspectAwarePreprocessor as AAPfrom pyimagesearch.datasets import SimpleDatasetLoader as SDLfrom pyimagesearch.nn.conv import fcheadnet as FCN from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import RMSpropfrom keras.layers import Inputfrom keras.models import Modelfrom keras .applications import VGG16from keras.optimizers import SGDfrom keras.models import Modelfrom imutils import pathsimport numpy as npimport argparseimport os
定义命令行参数:
1 2 3 4 5 ap = argparse.ArgumentParser() ap.add_argument("-d" ,"--dataset" ,required=True ,help ='path to input dataset' ) ap.add_argument('-m' ,'--model' ,required=True ,help ='path to output model' ) args = vars (ap.parse_args())
其中;
–dataset:输入数据的目录路径
–model:模型的保存路径
同样,我们对train数据进行数据增强操作:
1 2 aug = ImageDataGenerator(rotation_range=30 ,width_shift_range=0.1 ,height_shift_range=0.1 ,shear_range=0.2 ,zoom_range=0.2 ,horizontal_flip=True ,fill_mode='nearest' )
正如在第2节 中提到的,大多数情况我们都应该应用数据增强,因为数据增强既可以提高模型的准确度又可以避免过拟合,而且当我们没有足够的数据从头开始训练一个CNN模型时,我们更应该使用数据增强。
下面,我们从磁盘中加载数据集,并对数据进行处理:
1 2 3 4 5 print ("[INFO] loading images..." )imagePaths = list (paths.list_images(args['dataset' ])) classNames = [pt.split(os.path.sep)[-2 ] for pt in imagePaths] classNames = [str (x) for x in np.unique(classNames)]
需要注意的下,数据结构目录服从下面格式:
1 dataset_name/{class_name}/example.jpg
这样的好处就是可以方便地提取数据的类别信息。
1 2 3 4 5 6 7 aap = AAP.AspectAwarePreprocesser(224 ,224 ) iap= ITAP.ImageToArrayPreprocess() sdl = SDL.SimpleDatasetLoader(preprocessors=[aap,iap]) (data,labels) = sdl.load(imagePaths,verbose=500 ) data = data.astype("float" ) / 255.0
数据划分以及标签编码处理:
1 2 3 4 5 (trainX,testX,trainY,testY) = train_test_split(data,labels,test_size=0.25 ,random_state=42 ) trainY = LabelBinarizer().fit_transform(trainY) testY = LabelBinarizer().fit_transform(testY)
接下来,我们开始构建“新”的模型。
1 2 3 4 5 6 baseModel = VGG16(weights='imagenet' ,include_top=False ,input_tensor=Input(shape = (224 ,224 ,3 ))) headModel = FCN.FCHeadNet.build(baseModel,len (classNames),256 ) model = Model(inputs=baseModel.input ,outputs = headModel)
首先,我们加载了预训练好的VGG16模型,不返回全连接层[即删除‘头’部分],然后,加载自定义的全连接层,最后,将两部分进行拼接,组成一个“新”的模型。
前面提到过,在训练之前,我们需要“冻结”已有模型的权重,这样它们在反向传播阶段就不会被更新。keras中很容易实现‘冻结’操作,我们通过对baseModel中每个层设置.trainable参数为False来实现:
1 2 3 for layer in baseModel.layers: layer.trainable = False
接着,我们开始初始化全连接层的权重以及进行训练:
1 2 3 4 5 6 7 8 print ("[INFO] compiling model..." )opt = RMSprop(lr=0.001 ) model.compile (loss="categorical_crossentropy" , optimizer=opt,metrics=["accuracy" ]) print ("[INFO] training head..." )model.fit_generator(aug.flow(trainX,trainY,batch_size = 32 ), validation_data = (testX,testY),epochs=25 , steps_per_epoch = len (trainX) //32 ,verbose = 1 )
这里使用的是RMSprop优化器,我们将在第7节 中详细讨论这个算法。前面提到,一般微调过程使用一个很小的学习率,因此,设置lr=0.001。上面部分,我们主要的目的是训练“头”部分权重,而不改变网络主体的权重,因此,epochs设置为25,当然可以根据你的具体数据集进行调整,一般设置在10-30epochs左右。
查看模型的性能结果:
1 2 3 4 5 print ("[INFO] evaluating after initialization..." )predictions = model.predict(testX,batch_size=32 ) print (classification_report(testY.argmax(axis =1 ), predictions.argmax(axis =1 ),target_names=classNames))
完成了全连接层的训练之后,接下来,我们微调原有模型的部分权重,同样,通过对baseModel中每个层设置.trainable参数为True来实现
1 2 3 for layer in baseModel.layers[15 :]: layer.trainable = True
对于很深的网络比如VGG,包含许多参数,建议只微调部分层的权重,当然如果模型的准确度有提高且没有发生过拟合问题,那么可以微调更多层的权重。
1 2 3 4 5 6 7 8 9 10 11 print ("[INFO] re-compiling model ..." )opt = SGD(lr=0.001 ) model.compile (loss = 'categoricla_crossentropy' ,optimizer = opt, metrics=['accuracy' ]) print ("[INFO] fine-tuning model..." )model.fit_generator(aug.flow(trainX,trainY,batch_size=32 ), validation_data = (testX,testY),epochs = 100 , steps_per_epoch = len (trainX) // 32 ,verbose = 1 )
保存模型权重:
1 2 3 4 5 6 7 8 print ("[INFO] evaluating after fine-tuning..." )predictions = model.predict(testX,batch_size=32 ) print (classification_report(testY.argmax(axis =1 ), predictions.argmax(axis =1 ),target_names=classNames)) print ("[INFO] serializing model..." )model.save(args['model' ])
接下来,在Flower-17数据集进行实验,
1 $ python finetune_flowers17.py --dataset yourPath/datasets/flowers17/images --model flowers17.model
将得到以下结果;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 [INFO] loading images... [INFO] processed 500/1360 [INFO] processed 1000/1360 [INFO] compiling model... [INFO] training head... Epoch 1/25 10s - loss: 4.8957 - acc: 0.1510 - val_loss: 2.1650 - val_acc: 0.3618 ... Epoch 10/25 10s - loss: 1.1318 - acc: 0.6245 - val_loss: 0.5132 - val_acc: 0.8441 ... Epoch 23/25 10s - loss: 0.7203 - acc: 0.7598 - val_loss: 0.4679 - val_acc: 0.8529 Epoch 24/25 10s - loss: 0.7355 - acc: 0.7520 - val_loss: 0.4268 - val_acc: 0.8853 Epoch 25/25 10s - loss: 0.7504 - acc: 0.7598 - val_loss: 0.3981 - val_acc: 0.8971 [INFO] evaluating after initialization... precision recall f1-score support bluebell 0.75 1.00 0.86 18 buttercup 0.94 0.85 0.89 20 coltsfoot 0.94 0.85 0.89 20 cowslip 0.70 0.78 0.74 18 crocus 1.00 0.80 0.89 20 daffodil 0.87 0.96 0.91 27 daisy 0.90 0.95 0.93 20 dandelion 0.96 0.96 0.96 23 fritillary 1.00 0.86 0.93 22 iris 1.00 0.95 0.98 21 lilyvalley 0.93 0.93 0.93 15 pansy 0.83 1.00 0.90 19 snowdrop 0.88 0.96 0.92 23 sunflower 1.00 0.96 0.98 23 tigerlily 0.90 1.00 0.95 19 tulip 0.86 0.38 0.52 16 windflower 0.83 0.94 0.88 16 avg /total 0.90 0.90 0.89 340
在第一个epoch,验证集的准确度很低(约36%),主要一开始新的全连接层的权重是随机初始化的。随着优化不断进行,准确率迅速上升——到第10个epoch时,我们的分类准确率超过了80%,到第25个epoch结束时,准确率几乎达到了90%。
仅仅微调全连层,我们的新模型达到了约90%的准确度。接下来,我们查看微调部分原始模型的权重的结果,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ... [INFO] re-compiling model... [INFO] fine-tuning model... Epoch 1/100 12s - loss: 0.5127 - acc: 0.8147 - val_loss:0.3640 - val_acc: 0.8912 ... Epoch 99/100 12s - loss: 0.1746 - acc: 0.9373 - val_loss:0.2286 - val_acc: 0.9265 Epoch 100/100 12s - loss: 0.1845 - acc: 0.9402 - val_loss:0.2019 - val_acc: 0.9412 [INFO] evaluating after fine-tuning... precision recall f1-score support 0 0.94 0.79 0.86 19 1 0.93 0.87 0.90 15 10 1.00 1.00 1.00 20 11 0.95 0.83 0.88 23 12 0.95 0.95 0.95 19 13 0.82 0.86 0.84 21 14 0.95 0.95 0.95 20 15 1.00 0.93 0.96 27 16 0.89 1.00 0.94 16 2 0.90 0.95 0.93 20 3 0.90 0.90 0.90 20 4 1.00 0.95 0.98 22 5 1.00 1.00 1.00 16 6 0.90 1.00 0.95 18 7 0.77 0.94 0.85 18 8 0.92 0.96 0.94 23 9 1.00 0.96 0.98 23 avg / total 0.93 0.93 0.93 340
从结果中可以看到,准确度提高到了93%,比我们之前提取特征的方法更高。
从实验的结果来看,微调方法可以比特征提取方法获得更高的准确度。它能够将原始的网络权重对新的数据集进行学习——这是特征提取所不允许的。因此,当给定足够的训练数据时,尽量使用微调,因为你可能会比仅使用简单的特征提取获得更高的分类准确度。
总结
在本章中,我们讨论了迁移学习的另一种类型——微调。加载训练好的模型(一般实在大型数据集上训练得到的),截取全连接层以下的层作为“新”模型的主体,并在主体上连接新的全连接层。训练过程中,我们冻结主体层的权重,只训练新的全连接层参数。当然我们也可以微调主体的部分层权重。利用微调技术,因为我们不必从头训练整个网络。相反,我们可以利用已经存在的网络架构,例如在ImageNet数据集上训练的最优秀的模型。
本章完整代码地址:github