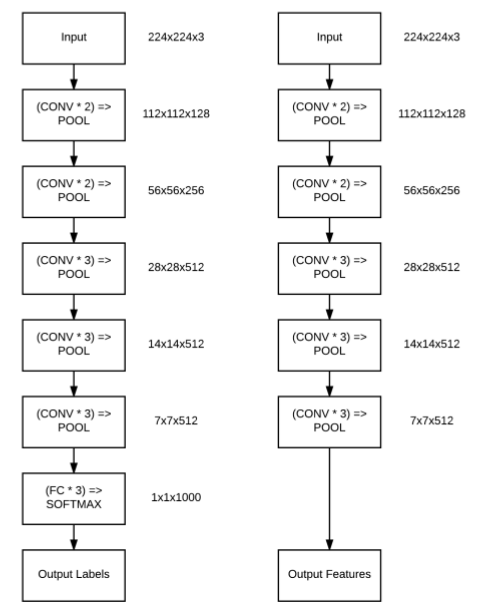
在我们深入讨论高级深度学习主题(如迁移学习)之前,先来了解下rank-1、rank-5和rank-N准确度的概念。当你在阅读深度学习相关文献时,尤其是关于计算机视觉和图像分类,你很可能会看到关于rank-N 准确度。例如,几乎所有在ImageNet数据集上验证的机器学习方法的论文都给出了rank-1和rank-5准确度 (我们将在本章后面解释为什么需要使用rank-1和rank-5准确度).
rank-N准确度指标与传统的评估指标有何不同呢?在本节中,我们将讨论rank-N准确度内容以及如何实现它。最后将其应用于在Flower-17和CALTECH-101数据集上。
rank-N准确度
通过一个例子来解释rank-N准确度概念。假设我们正在评估一个训练在CIFAR-10数据集上的神经网络模型,CIFAR-10数据集包括10个类:飞机,汽车,鸟、猫、鹿、狗、青蛙、马、船和卡车。给定一张输入图像(如图4.1左)

- 步骤1:计算数据集中每个输入图像的类标签概率。
- 步骤2:原始标签与对应概率最大的标签进行比较,若相同为true,反之false
- 步骤3:统计步骤2为true的个数
上面我们计算的是rank-1准确度,即对应预测最高概率的标签与真实标签相同的个数占总个数的百分比——标签相同的个数 / 总数据个数。
现在,我们扩展到rank-5准确度,我们关注的不是top1的预测,而是top5的预测,那么整个计算过程如下:
- 步骤1: 计算数据集中每个输入图像的类标签概率。
- 步骤2: 对预测的类标签概率进行降序排序
- 步骤3: 判断真实的标签是否落在预测的top5标签里面,若存在,则标记为true,反之false
- 步骤4: 统计步骤3中为true的个数
rank-5准确度是rank-1准确度的扩展,我们对一张图片的预测结果是来自模型输出结果中top5对应的5个预测,而不是top1的1个预测。例如,我们对图4.1右图片进行预测,rank-5对应的预测结果为表4.1右结果。
很显然图4.1右是一辆汽车,然而,如果使用的是rank-1预测的话,结果为卡车,显然是不对的。但是如果使用rank-5的话,发现汽车实际上是第2个预测结果,这时候对于rank-5预测而言是正确的。这种方法也可以很容易地推广到计算rank-N准确度。 一般而言,我们只计算rank-1和rank-5准确度——计算rank-1的准确度可以理解,为什么还需要计算rank-5准确度呢?
对于CIFAR-10数据集来说,由于本身类别个数不多,计算rank-5准确度有点不太合适。但对于大型的、具有挑战性的数据集来说,特别是细粒度的分类。从Szegedy[17]等人的论文中的一个例子或许可以很好的解释为什么需要计算rank-1和rank-5准确度。比如图4.2中,我们可以看到左边是西伯利亚哈士奇,右边是爱斯基摩犬。从人的肉眼来看是无法区分开的,但是这个在ImageNet 数据集中是有效的标签。

因此,我们也根据rank-5准确度检验模型,以确保我们的网络在后面的迭代中仍然是“学习”的。在训练快结束时,rank-1准确度可能会停滞不前,但是当我们的网络学习到更多的识别特征(虽然没有足够的识别能力超过top1的预测)时,rank-5准确度会继续提高。
实现rank-1和rank-5准确度
我们可以通过在项目中构建一个工具模块来计算rank-1和rank-5准确度。因此,在pyimagesearch
项目中增加一个子模块utils,并在子模块中增加一个ranked.py脚本,整个目录结构如下:
1 | --- pyimagesearch |
打开ranked.py脚本,写入以下代码:
1 | #encoding:utf-8 |
定义了rank5_accuracy函数,主要需要传入两个参数:
- preds: 一个NxT的矩阵,其中N表示行数,T表示列数,每个值代表对应标签下的概率
- labels: 原始数据中的真实标签
接下来计算rank-1和rank-5:
1 | # 遍历数据集 |
应用
第2节中,我们使用了预先训练好的VGG16模型对三种数据集提取了特征,并对特征向量训练了逻辑回归模型,以及对模型进行了评估,接下来,我们将使用rank-1和rank-5准确度进行型评估。
新建一个脚本文件,名为rank_accuracy.py,并写入以下代码:
1 | #encoding:utf-8 |
接下来,解析命令行参数:
1 | # 解析命令行参数 |
主要有两个参数:
- –db: HDF5数据路径
- –model:之前训练好的logistic regression模型路径
由于我们使用的是前75%的数据进行训练,因此,我们使用后25%数据进行预测和评估:
1 | # 加载模型 |
Flowers-17结果
下面我们使用Flowers-17数据进行实验,运行下面命令:
1 | python rank_accuracy.py --db youPath/data/flowers17/hdf5/features.hdf5 -model youPath/flowers17.cpickle |
将得到如下结果:
1 | [INFO] loading pre-trained model... |
CALTECH-101结果
我们尝试另外一个数据例子—CALTECH-101,运行下面代码:
1 | python rank_accuracy.py --db youPath/data/caltech101/hdf5/features.hdf5 --model youPath/caltech101.cpickle |
得到的结果如下;
1 | [INFO] loading pre-trained model... |
总结
在本节中,我们讨论了rank-1和rank-5准确度概念。在大型的、具有挑战性的数据集(如ImageNet)上,除了要关注rank-1准确度,还需要关注rank-5准确度,在这些数据集中,即使是人眼查看也无法正确地给每一张图像贴上真实的标签。在这种情况下,如果真实标签存在于top5预测中,那么可以认为我们的模型的预测是“正确的”。
说明:rank-1和rank-5准确性并不仅限于深度学习和图像分类,还可以使用在其它领域。
详细代码位置:github