#encoding:utf-8 from keras.preprocessing.image import ImageDataGenerator from keras.preprocessing.image import img_to_array from keras.preprocessing.image import load_img import numpy as np import argparse
其中ImageDataGenerator是keras中数据增强类,包含了各种变换方法。
接下来,我们解析命令行参数:
1 2 3 4 5 6
# 构造参数解析和解析参数 ap = argparse.ArgumentParser() ap.add_argument('-i','--image',required=True,help = 'path to the input image') ap.add_argument('-o','--ouput',required=True,help ='path to ouput directory to store augmentation examples') ap.add_argument('-p','--prefix',type=str,default='image',help='output fielname prefix') args = vars(ap.parse_args())
print("[INFO] generating images...") imageGen = aug.flow(image,batch_size=1,save_to_dir=args['output'],save_prefix=args['prefix'],save_format='jpg') for image in imageGen: total += 1 # 只输出10个案例样本 if total == 10: break
#encoding:utf-8 from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from pyimagesearch.preprocessing import ImageToArrayPreprocessor as IAP from pyimagesearch.preprocessing import AspectAwarePreprocessor as AAP from pyimagesearch.preprocessing import ImageMove as IM #新增模块 from pyimagesearch.datasets import SimpleDatasetLoader as SDL from pyimagesearch.nn.conv import MiniVGGNet as MVN from keras.optimizers import SGD from imutils import paths import matplotlib.pyplot as plt import numpy as np import argparse import os
print("[INFO] loading images...") imagePaths = list(paths.list_images(args["dataset"])) classNames = [pt.split(os.path.sep)[-2] for pt in imagePaths] classNames = [str(x) for x in np.unique(classNames)]
#encoding:utf-8 from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from pyimagesearch.preprocessing import ImageToArrayPreprocessor as IAP from pyimagesearch.preprocessing import AspectAwarePreprocessor as AAP from pyimagesearch.preprocessing import ImageMove as IM from pyimagesearch.datasets import SimpleDatasetLoader as SDL from pyimagesearch.nn.conv import MiniVGGNet as MVN from keras.preprocessing.image import ImageDataGenerator # 数据增强类 from keras.optimizers import SGD from imutils import paths import matplotlib.pyplot as plt import numpy as np import argparse import os
与minivggnet_flowers17.py一样,不同的是第10行新增了数据增强模块。
接下来同样进行数据预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
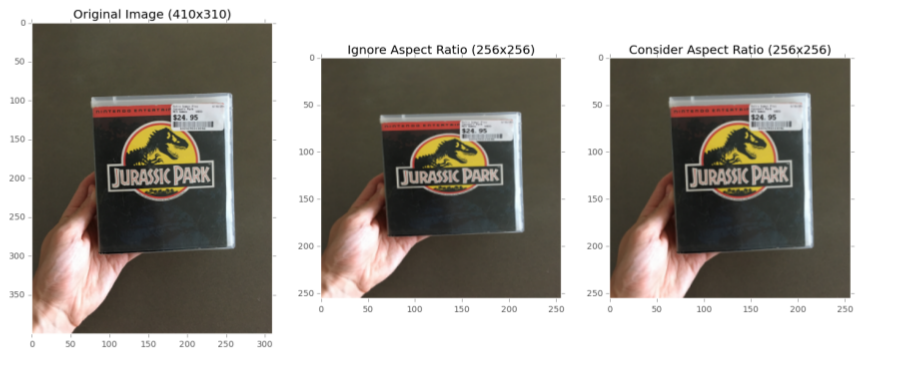
ap = argparse.ArgumentParser() ap.add_argument('-d','--dataset',required=True,help='path to input dataset') args = vars(ap.parse_args()) print('[INFO] moving image to label folder.....') im = IM.MoveImageToLabel(dataPath=args['dataset']) im.makeFolder() im.move() print("[INFO] loading images...") imagePaths = [ x for x inlist(paths.list_images(args['dataset'])) if x.split(os.path.sep)[-2] !='jpg'] classNames = [pt.split(os.path.sep)[-2] for pt in imagePaths ] classNames = [str(x) for x in np.unique(classNames)] aap = AAP.AspectAwarePreprocesser(64,64) iap = IAP.ImageToArrayPreprocess() sdl = SDL.SimpleDatasetLoader(preprocessors = [aap,iap]) (data,labels) = sdl.load(imagePaths,verbose = 500) data = data.astype('float') / 255.0 (trainX,testX,trainY,testY) = train_test_split(data,labels,test_size=0.25,random_state =43) trainY = LabelBinarizer().fit_transform(trainY) testY = LabelBinarizer().fit_transform(testY)
数据预处理完之后,在模型训练之前,我们对train数据进行数据增强处理。
1
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,horizontal_flip=True, fill_mode="nearest")