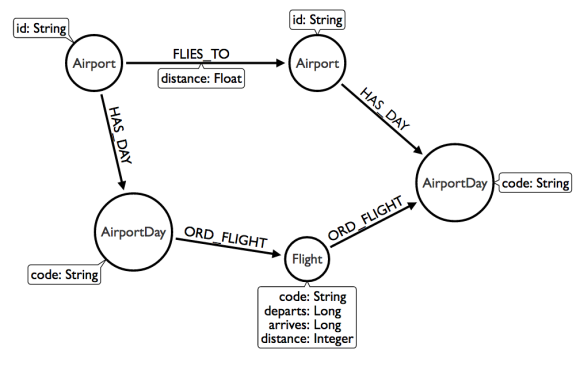
就在前几天,我和一位投资风险经理谈了他的团队正在研究的一个数据问题,他想知道Neo4j是否能提供帮助。假设你有大约20,000个共同基金和ETFs,你想要追踪他们是如何衡量基准的,例如标准普尔500指数的回报率。比如说,2000个不同的基准,你想要跟踪它五年内的每一天的情况。这就有 共500亿数据点。如果我们使用关系数据库的话,这是一个很大的连接表。我们如何使用neo4j建立一个有效模型?
为了简单起见,假设我们只想追踪一个度量,这个度量是。当我们比较共同基金和基准的价值变化时,变化轨迹有多近?总是在0和1之间。0值意味着基准与共同基金无关,而1值意味着有关。那么我们怎么来建立模型呢?
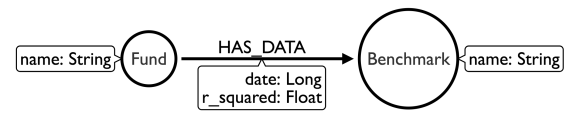
我们的第一个选项是将该基金作为一个节点建模,基准作为一个节点,并通过他们对应的日期进行关系连接,其中日期和作为关系的属性,如上所示。我们将有20,000个基金节点,2000个基准节点,以及500亿条关系。这是一个非常稠密的图。
首先我们尝试一个查询,看看我们的模型是怎么做的。我想知道在2017年10月31日(万圣节)X基金和基准Y的情况。
1 | MATCH (f:Fund {name: $fund_name})-[r:HAS_DATA]->(b:Benchmark {name: $benchmark_name}) |
首先对:Fund(name)建立索引,这样可以直接快速的定位到我们所需要查询的Found,但是这个模型在性能上很糟糕,主要是我必须遍历个关系,以找到我想要的。
让我们试试另一种方法,使用日期关系类型:

为了找到基金和基准之间的,可以这样写查询语句:
1 | MATCH (f:Fund {name: $fund_name})-[r:ON_2017_10_31]->(b:Benchmark {name: $benchmark_name}) |
现在,我只需要遍历2000个关系,而不是遍历250万个关系,这要快得多。另一个好处是,如果我想在指定的一个日期内得到所有基金的基准,这很容易得到:
1 | MATCH (f:Fund {name: $fund_name})-[r:ON_2017_10_31]->(b:Benchmark) |
但是让我们尝试另一个查询。比方说,我们想看看自今年初以来,一个基金与一个基准的是如何变化的。
1 | MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark {name: $benchmark_name}) |
首先,我们可以快速地从索引中一次遍历找到指定的基金节点,然后我们再遍历250万的关系来找到我们想要的。现在,遍历2-4百万的关系并不是极限。Neo4j可以在大约一秒钟内做到这一点。但我们可以做得更好。让我们尝试将基准名称移动到关系中。
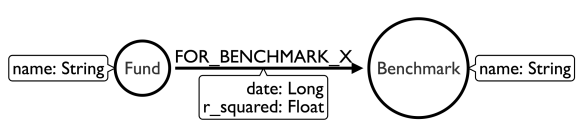
使用这个模型,我们将从我们的基金节点开始,遍历5年* 252天= 1,260个关系,并检查日期属性满足条件得到想要的结果。
1 | MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name}) |
好吧…如果想要得到一个基金与所有基准之间的?
1 | MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark) |
从上面查询语句看我们又要遍历个基准或250万个关系。我们不能同时使用日期和基准名称作为关系类型。Neo4j只能处理大约32k的关系类型,而不是我们需要的250万。那么我们能做什么呢?

这是正确的。我们可以创建一个新类型的节点-FundDay,所以有20,000个基金* 5年* 252天大约是2500万个节点。然后我们将这些节点与我们的基金和基准联系起来。我们的查询是想得到所有的值,:
1 | MATCH (f:Fund {name: $fund_name})-[:ON_2017_10_31]->()-[r]->(b:Benchmark) |
我们从基金节点开始,首先遍历FundDay(我们将忽略它),然后再遍历这个FundDay关联的所有基准。因此,我们的查询将遍历一段关系,再加上2000个基准。遍历2,001个关系要比遍历250万个关系快得多。
还有一个小问题。我们现在的图是有20000年基金节点,2000年基准节点,和250万 FundDay节点组成.但我们仍然有25 m FundDay节点和2000年基准之间的关系,大约500亿条关系。我们可以削减这个数据库的大小吗?我们记住Neo4j可以处理像整数、字符串、浮点数等标量值,以及它们的数组。因此,如果我们将存储在数组中,而不是分别存储每个,如何存储在一个列表中?

我们现在存储了一个5年* 252天值的数组,而不是在属性中存储一个值。2017年万圣节这天的位于列表中的1218位。
1 | MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name}) |
从2017年第一个交易日到万圣节这天,所有的值,首先我们计算开始的index:4年* 252 = 1008,在加上2017年时间段,所以我们现在的查询是:
1 | MATCH (f:Fund {name: $fund_name})-[r:FOR_BENCHMARK_X]->(b:Benchmark {name: $benchmark_name}) |
首先从基金节点开始,遍历一次关系,并将属性数组的一部分作为值。那么对于许多基准测试呢?
1 | MATCH (f:Fund {name: $fund_name})-[r]->(b:Benchmark) |
上面的查询成本只需遍历2000个关系(每个基准测试一个)和2000个属性查找,而且我们降低数据库的大小,只有20000个基金节点,2000个基准节点和4000万(一个为每个组合)个关系。
还有一个小问题:默认情况下,Neo4j将数组属性存储在120字节的块中。8-10字节的开销会留下112字节的存储空间。由于每个值是一个需要8个字节的浮点数,每个块每次只需要使用14个值,这相当于需要从一个block跳转到另外一个block,会降低一点查询速度。
但是,由于我们提前知道了要存储的数量,我们可以将这个参数(array_block_size)更改为10080(5年* 252天(8个字节)的值。Neo4j将使用这个值加上8-10字节的开销。每一页有8192个字节,所以我们可以预留一页半(12878)或两页(16,374),留下10个字节的开销。我们的数据库大小约为700 GB,所以我们需要使用x1.16xlarge或x1e。8xlarge每月预付一笔3年的预付费用,每月约1,365美元。另一种选择是,我们可以花2万美元买一个大的RAM服务器,然后自己托管它。
记住,在图数据库中没有“第三范式”来建模数据。这是一个疯狂的前沿。使用你所拥有的数据和你想要回答的问题作为指南,但一定要让你的想象力和创造力帮助你前进。
来源: https://dzone.com/articles/mutual-fund-benchmarks-with-neo4j