我想我将利用这个机会来解释为什么我喜欢这篇博文中的graphs。我将试着解释如何从graph的角度看问题,让你找到创造性的解决方案。我们这篇文章的背景是航班搜索,但我们真正的任务是如何快速有效地绘制graph,这样我们就可以将我们的知识应用到其他问题上。
之前,我给你们展示了不同的航空数据模型。当涉及到graph建模时,要认识到是没有一个完全正确的方法,需要根据你的查询目的构建模型。最优模型严重依赖于您想要查询的目的。为了证明这一点,我将向你们展示另一种方法来模拟航空公司的航班数据,并对航班搜索进行优化。如果你还记得,我们最后的模型是:
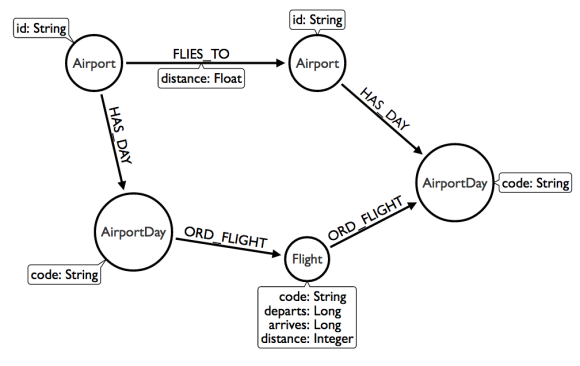
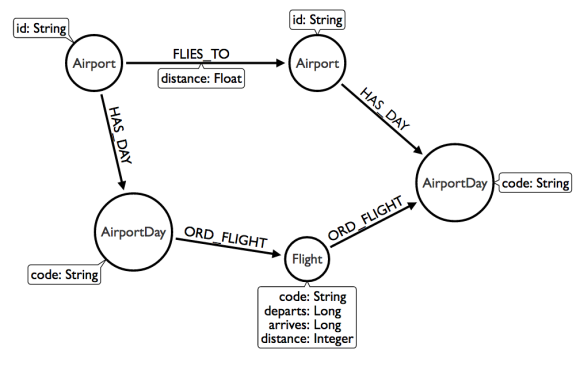
我们所做的最后一个建模优化是创建一个“目的地”节点,在特定的一天从同一个机场到同一个目的地的航班。后来,我了解到,世界上只有大约40k的商业机场,而neo4j支持64k关系类型。这是有用的,因为一旦一个节点拥有超过40个关系,而不是将关系存储在列表中,它们就会按类型和方向 被分解并存储在组中。这些是graph中所谓的“密集”节点。如果我们知道关系的类型和方向,我们就可以在这些关系中指定方向,甚至不用考虑其他关系。记住,我们的遍历速度取决于我们要遍历多少个graph才能得到答案。有了这些知识,我们将重新建模我们的graph,所以它看起来是这样的:
需要注意两点:一是我们又重新指向了机场。二是目的地节点被“类型”关系所取代。在neo4j中我们建立了“日期”关系类型,使得我们搜索更快,但这次的日期是“AirportDay”节点的一部分,所以我们可以使用关系类型中的airport编码来加快速度。
这个模型有两个级别。在较高级别,我们有机场。在较低级别,有机场之间航班信息。重要的是,graph不仅仅只是平面的二维结构,还可以有多个维度,你很快就会看到单个查询可能需要探索graph的多个级别才能得到正确的答案。我们在graph中加载一些机场节点:
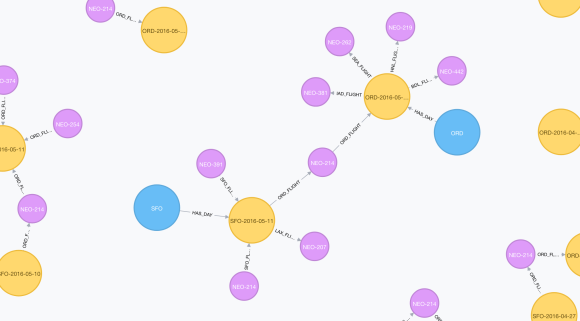
现在,让我们导入机场之间的一些航班节点,我们可以看到SFO是如何与ORD连接的:
SFO和ORD机场的节点是相互分离的,但我们可以从较低的级别获取数据,并使用它通过这个查询连接更高级别的机场:
1 2 3 4 5 6 MATCH (a1:Airport)- [:HAS_DAY]- > (ad1:AirportDay)(l:Leg) WHERE a1 <> a2WITH a1, AVG (l.distance) AS avg_distance, a2, COUNT (* ) AS flightsMERGE (a1)- [r:FLIES_TO]- > (a2)SET r.distance = avg_distance, r.flights = flights
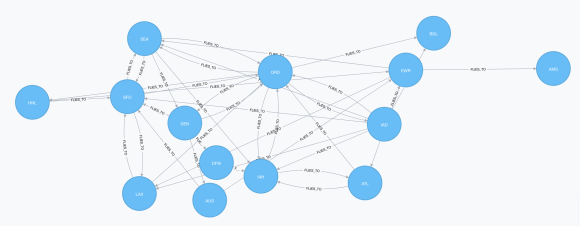
现在,让我们来看看相互连接的机场:
在我们的模型建完之后,回到最原始的问题:考虑到两个机场和一天日期,我们如何找到从一个机场到另一个机场最短路线?我所想到的是,首先通过FLIES_TO的关系来遍历机场graph,找到机场之间最佳的潜在航线。然后一旦我们有了潜在的路线,我们就会沿着graph的较低级别遍历,但是只有沿着在较高级别上找到的路线。这条路径限制了在较低的层次上的遍历,因为它不会浪费任何时间去追逐那些不是最优的路线。
把你的数据想象成一个graph,一次一次地探索它。从这里到那里怎么走?为什么我选择走一条路而不是另一条路?如何限制所遍历grpah的数量以得到正确的答案?graph不只是一个愚蠢的数据存储。它们是奇迹、灵感和可能性的源泉。找到更好的方法来解决问题,你需要做的就是接受它…,好吧,你必须编写代码。但别担心,如果你能实现梦想,我们可以帮助你将梦想变成Java代码。好吧,这听起来很糟糕,但问题仍然存在。让我们看看存储过程。如果您有一个监视器,您可能想要在一个单独的窗口中打开源代码,并同时进行并行操作。我们将声明我们的存储过程并期待一些输入。我们想要一份潜在的出境机场名单,还有可能到达机场的名单,日期和两个限制。其中一个是返回的航班数,第二个是对该查询允许使用时间的严格限制。
1 2 3 4 5 6 7 @Description("com.maxdemarzi.flightSearch() | Find Routes between Airports") @Procedure(name = "com.maxdemarzi.flightSearch", mode = Mode.SCHEMA) public Stream<MapResult> flightSearch (@Name("from") List<String> from, @Name("to") List<String> to, @Name("day") String day, @Name("recordLimit") Number recordLimit, @Name("timeLimit") Number timeLimit) {
我们将使用这些输入来获得机场和到达机场:
1 2 3 4 5 6 7 8 try (Transaction tx = db.beginTx()) { for (String fromKey : getAirportDayKeys(from, day)) { Node departureAirport = db.findNode(Labels.Airport, "code" , fromKey.substring(0 ,3 )); Node departureAirportDay = db.findNode(Labels.AirportDay, "key" , fromKey); if (!(departureAirportDay == null )) { for (String toKey : getAirportDayKeys(to, day)) { Node arrivalAirport = db.findNode(Labels.Airport, "code" , toKey.substring(0 ,3 )); Double maxDistance = getMaxDistance(departureAirport, arrivalAirport);
我们的maxDistance是500英里加上两倍于机场之间的距离。这是一个很好的启发,因为我们的乘客愿意忍受多少痛苦的长途航班。一说到长途飞行,我们想避开它们。我们在这个航班搜索查询中执行我们的第一个遍历。我们在第一个遍历中想要做的是,在graph中使用高级别的机场来寻找潜在的路线,并收集机场代码加上“_FLIGHT”,作为我们允许的关系类型在第二次遍历中遍历。这将阻止我们从洛杉矶到芝加哥的航班,去夏威夷或欧洲国家。它将保持对直接和间接飞行的遍历,这是有意义的。
1 2 3 4 5 6 7 8 9 10 11 12 13 private static final LoadingCache<String, ArrayList<HashMap<RelationshipType, Set<RelationshipType>>>> allowedCache = Caffeine.newBuilder() .maximumSize(10_000 ) .expireAfterWrite(1 , TimeUnit.HOURS) .refreshAfterWrite(1 , TimeUnit.HOURS) .build(Flights::allowedRels); private static ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> allowedRels (String key) { Node departureAirport = graph.findNode(Labels.Airport, "code" , key.substring(0 ,3 )); Node arrivalAirport = graph.findNode(Labels.Airport, "code" , key.substring(4 ,7 )); Double maxDistance = getMaxDistance(departureAirport, arrivalAirport); return getValidPaths(departureAirport, arrivalAirport, maxDistance); }
allowedCache是一种加载缓存,它能找出两个机场之间最佳的潜在路线,并缓存它们的结果。我们想要缓存结果,因为您可能有上千个查询的特定路径,因为它不会发生很大的变化,在数据库中不断地进行访问是没有意义的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private static ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> getValidPaths (Node departureAirport, Node arrivalAirport, Double maxDistance) { ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> validRels = new ArrayList <>(); TraversalDescription td = graph.traversalDescription() .breadthFirst() .expand(bidirectionalFliesToExpander, ibs) .uniqueness(Uniqueness.NODE_PATH) .evaluator(Evaluators.toDepth(2 )); BidirectionalTraversalDescription bidirtd = graph.bidirectionalTraversalDescription() .mirroredSides(td) .collisionEvaluator(new CollisionEvaluator ()); for (org.neo4j.graphdb.Path route : bidirtd.traverse(departureAirport, arrivalAirport)) { Double distance = 0D ; for (Relationship relationship : route.relationships()) { distance += (Double) relationship.getProperty("distance" , 25000D ); }
那么,getvalidpath是做什么的呢?它返回一个有效关系类型的列表,在遍历的每个步骤中遍历每个机场。这种天真的做法可能会让所有的关系类型都回归到潜在的路线中,但是只要给定机场,就会让我们去追逐无效的路线。一个更聪明的方法将会返回在路径中任何地方允许的关系类型,但是又一次允许无效的路由,因为顺序没有被保留。此版本只允许在遍历中特定的步骤中从机场的关系类型,限制我们只对有效路径进行限制,并避免我们追逐错误的路径。
我们使用双向遍历器来实现这一点,因为我们有开始和结束节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 if (distance < maxDistance){ String code; RelationshipType relationshipType = null ; int count = 0 ; for (Node node : route.nodes()) { if (relationshipType == null ) { code = (String)node.getProperty("code" ); relationshipType = RelationshipType.withName(code + "_FLIGHT" ); } else { HashMap<RelationshipType, Set<RelationshipType>> validAt; if (validRels.size() <= count) { validAt = new HashMap <>(); } else { validAt = validRels.get(count); } Set<RelationshipType> valid = validAt.getOrDefault(relationshipType, new HashSet <>()); String newcode = (String)node.getProperty("code" ); RelationshipType newRelationshipType = RelationshipType.withName(newcode + "_FLIGHT" ); valid.add(newRelationshipType); validAt.put(relationshipType, valid); if (validRels.size() <= count) { validRels.add(count, validAt); } else { validRels.set(count, validAt); } relationshipType = newRelationshipType; count++; } } } } return validRels;
现在我们需要收集这些路线,让它们快速进入,并确保我们维持秩序和潜在目的地。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private void secondTraversal (ArrayList<MapResult> results, Integer recordLimit, Node departureAirportDay, Node arrivalAirport, Double maxDistance, PathFinder<WeightedPath> dijkstra) { for (org.neo4j.graphdb.Path position : dijkstra.findAllPaths(departureAirportDay, arrivalAirport)) { if (results.size() < recordLimit) { HashMap<String, Object> result = new HashMap <>(); ArrayList<Map> flights = new ArrayList <>(); Double distance = 0D ; ArrayList<Node> nodes = new ArrayList <>(); for (Node node : position.nodes()) { nodes.add(node); } for (int i = 1 ; i < nodes.size() - 1 ; i+=2 ) { Map<String, Object> flightInfo = nodes.get(i).getAllProperties(); flightInfo.put("origin" , ((String)nodes.get(i-1 ).getProperty("key" )).substring(0 ,3 )); flightInfo.put("destination" , ((String)nodes.get(i+1 ).getProperty("key" )).substring(0 ,3 )); flightInfo.remove("departs" ); flightInfo.remove("arrives" ); flights.add(flightInfo); distance += ((Number) nodes.get(i).getProperty("distance" , 0 )).doubleValue(); } result.put("flights" , flights); result.put("score" , position.length() - 2 ); result.put("distance" , distance.intValue()); results.add(new MapResult (result)); } } }
现在我们可以准备第二个遍历了。
1 2 3 4 5 6 public PathRestrictedExpander (String endCode, long stopTime, ArrayList<HashMap<RelationshipType, Set<RelationshipType>>> validRels) { this .endCode = endCode; this .stopTime = System.currentTimeMillis() + stopTime; this .validRels = validRels; }
在这里,我们创建了一个PathRestrictedExpander,它包含了构造函数中允许的关系类型的列表,我们希望这个遍历停止搜索和我们最终目的地的机场代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Override public Iterable<Relationship> expand (Path path, BranchState<Double> branchState) { if (System.currentTimeMillis() < stopTime) { if (path.length() < 8 ) { if (((path.length() % 2 ) == 0 ) && ((String)path.endNode().getProperty("key" )).substring(0 ,3 ).equals(endCode)) { return path.endNode().getRelationships(Direction.INCOMING, RelationshipTypes.HAS_DAY); } if (path.length() > 2 && ((path.length() % 2 ) == 1 ) ) { Iterator<Node> nodes = path.reverseNodes().iterator(); Long departs = (Long)nodes.next().getProperty("departs" ); nodes.next(); Node lastFlight = nodes.next(); if (((Long)lastFlight.getProperty("arrives" ) + minimumConnectTime) > departs) { return Collections.emptyList(); } } if (path.length() < 2 ) { RelationshipType firstRelationshipType = RelationshipType.withName(((String)path.startNode() .getProperty("key" )).substring(0 ,3 ) + "_FLIGHT" ); RelationshipType[] valid = validRels.get(0 ).get(firstRelationshipType) .toArray(new RelationshipType [validRels.get(0 ).get(firstRelationshipType).size()]); return path.endNode().getRelationships(Direction.OUTGOING, valid); } else { int location = path.length() / 2 ; if (((path.length() % 2 ) == 0 ) ) { return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location) .get(path.lastRelationship().getType()) .toArray(new RelationshipType [validRels.get(location) .get(path.lastRelationship().getType()).size()])); } else { Iterator<Relationship> iter = path.reverseRelationships().iterator(); iter.next(); RelationshipType lastRelationshipType = iter.next().getType(); return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location).get(lastRelationshipType) .toArray(new RelationshipType [validRels.get(location).get(lastRelationshipType).size()])); } } } } return Collections.emptyList(); }
当这个expand执行时,它将检查当前时间与我们的停止时间,然后看看我们是否到达目的地机场。如果没有,它将确保离开日期大于我们的到达时间和最小连接时间(这个例子在30分钟内硬编码,但是可以是动态的)。这使得人们不能错过他们的航班,因为他们在下午5点到达,并且在机场的另一边下午5点05分起飞。最后,它允许遍历在给定的关系类型上,但只在路径的有效位置上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Override public Iterable<Relationship> expand (Path path, BranchState<Double> branchState) { if (System.currentTimeMillis() < stopTime) { if (path.length() < 8 ) { if (((path.length() % 2 ) == 0 ) && ((String)path.endNode().getProperty("key" )).substring(0 ,3 ).equals(endCode)) { return path.endNode().getRelationships(Direction.INCOMING, RelationshipTypes.HAS_DAY); } if (path.length() > 2 && ((path.length() % 2 ) == 1 ) ) { Iterator<Node> nodes = path.reverseNodes().iterator(); Long departs = (Long)nodes.next().getProperty("departs" ); nodes.next(); Node lastFlight = nodes.next(); if (((Long)lastFlight.getProperty("arrives" ) + minimumConnectTime) > departs) { return Collections.emptyList(); } } if (path.length() < 2 ) { RelationshipType firstRelationshipType = RelationshipType.withName(((String)path.startNode() .getProperty("key" )).substring(0 ,3 ) + "_FLIGHT" ); RelationshipType[] valid = validRels.get(0 ).get(firstRelationshipType) .toArray(new RelationshipType [validRels.get(0 ).get(firstRelationshipType).size()]); return path.endNode().getRelationships(Direction.OUTGOING, valid); } else { int location = path.length() / 2 ; if (((path.length() % 2 ) == 0 ) ) { return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location) .get(path.lastRelationship().getType()) .toArray(new RelationshipType [validRels.get(location) .get(path.lastRelationship().getType()).size()])); } else { Iterator<Relationship> iter = path.reverseRelationships().iterator(); iter.next(); RelationshipType lastRelationshipType = iter.next().getType(); return path.endNode().getRelationships(Direction.OUTGOING, validRels.get(location).get(lastRelationshipType) .toArray(new RelationshipType [validRels.get(location).get(lastRelationshipType).size()])); } } } } return Collections.emptyList(); }
我们要做的最后一件事是获取遍历的结果,再次验证没有发现的路径违反了我们的maxDistance号,并将它们的属性添加到结果中。在这一点上,我们的遍历已经完成,我们只需要顺序和流的结果。
1 2 3 results.sort(FLIGHT_COMPARATOR); return results.stream();
一如既往的源代码在GitHub …但是,嘿,我忘了说这是多么快。嗯,在性能测试中,有一年的飞行数据,在两个停止查询的测试中,我的5年笔记本电脑每秒可以处理18次请求,平均为72ms,最大值为280ms。在大多数航空公司的网站上,与通常的10秒钟相比。
来源:https://dzone.com/articles/flight-search-with-neo4j