Arxiv今日论文 | 2026-02-03
本篇博文主要内容为 2026-02-03 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-02-03)
今日共更新1500篇论文,其中:
自然语言处理共234篇(Computation and Language (cs.CL))
人工智能共537篇(Artificial Intelligence (cs.AI))
计算机视觉共323篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共564篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Reward-free Alignment for Conflicting Obje ...
Arxiv今日论文 | 2026-02-02
本篇博文主要内容为 2026-02-02 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-02-02)
今日共更新673篇论文,其中:
自然语言处理共93篇(Computation and Language (cs.CL))
人工智能共220篇(Artificial Intelligence (cs.AI))
计算机视觉共110篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共262篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] FOCUS: DLLM s Know How to Tame Their Compute ...

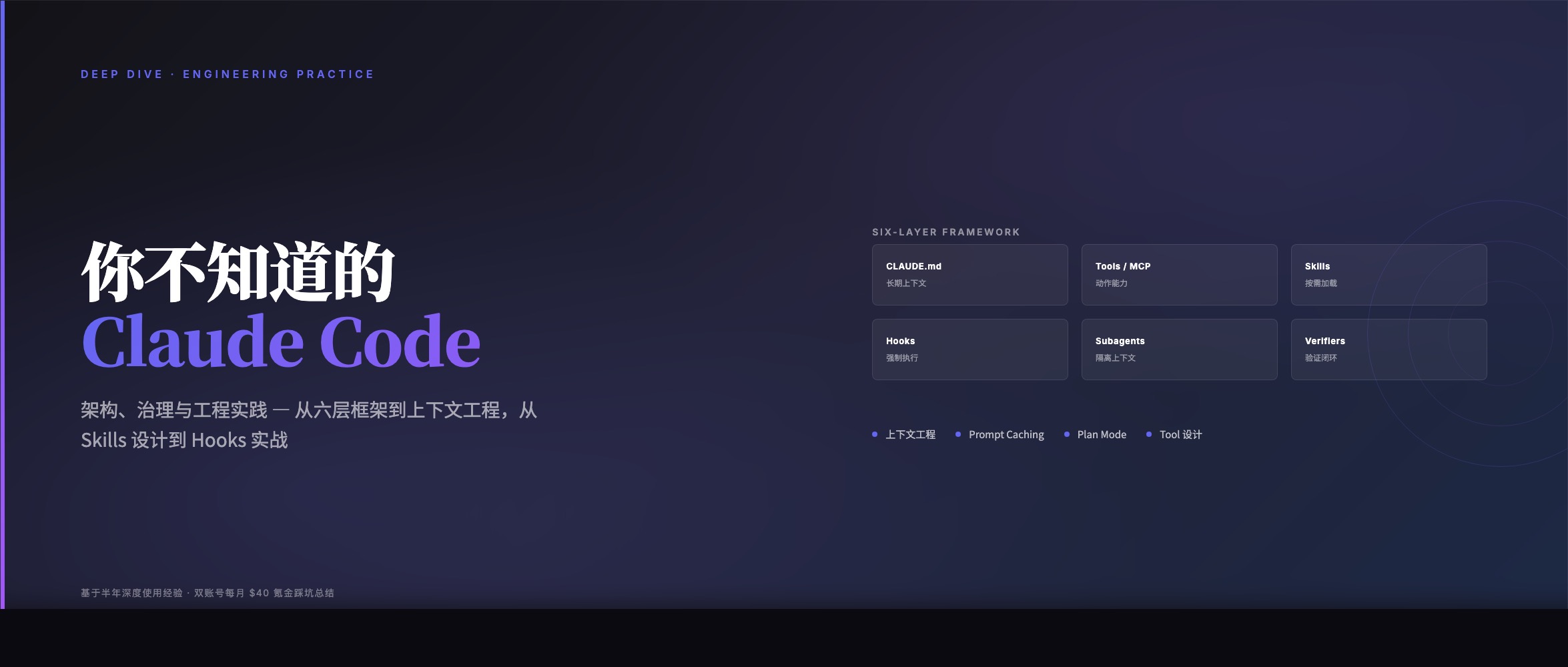
Kimi CLI 的 Skills 开发
摘要
随着大型语言模型(LLM)在软件开发领域的广泛应用,如何有效地扩展 AI Agent 的专业能力成为一个重要课题。Kimi Code CLI 通过引入 Agent Skills 机制,为用户提供了一种模块化、可复用的能力扩展方案。本文系统性地介绍了 Kimi CLI Skills 的架构设计、开发流程,并重点阐述了 Flow Skill 这一特殊类型的工作流自动化机制。通过实际案例分析,本文展示了如何构建从简单的知识型 Skill 到复杂的多步骤自动化工作流,为开发者提供完整的 Skills 开发实践指南。
1. 引言
1.1 背景与动机
在现代软件开发中,AI 编程助手已成为提升效率的重要工具。然而,通用的 AI 模型往往缺乏特定领域的专业知识,例如团队编码规范、项目特定的业务逻辑、或复杂的多步骤工作流程。传统的解决方案是通过详细的提示词(Prompt Engineering)来引导 AI,但这种方法存在明显的局限性:提示词难以复用、知识难以沉淀、工作流程难以自动化。
Agent Skills 作为一种开放格式,旨在解决上述问题。它将专业知识和工作流程封装为独立的模块,使 AI ...
Arxiv今日论文 | 2026-01-30
本篇博文主要内容为 2026-01-30 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-30)
今日共更新788篇论文,其中:
自然语言处理共120篇(Computation and Language (cs.CL))
人工智能共276篇(Artificial Intelligence (cs.AI))
计算机视觉共115篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共302篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] RedSage: A Cybersecurity Generalist LLM IC ...
Arxiv今日论文 | 2026-01-29
本篇博文主要内容为 2026-01-29 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-29)
今日共更新531篇论文,其中:
自然语言处理共97篇(Computation and Language (cs.CL))
人工智能共150篇(Artificial Intelligence (cs.AI))
计算机视觉共78篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共170篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Evolutionary Strategies lead to Catastrophic ...
Arxiv今日论文 | 2026-01-28
本篇博文主要内容为 2026-01-28 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-28)
今日共更新562篇论文,其中:
自然语言处理共64篇(Computation and Language (cs.CL))
人工智能共159篇(Artificial Intelligence (cs.AI))
计算机视觉共91篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共175篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Evaluation of Oncotimia: An LLM based system ...
Arxiv今日论文 | 2026-01-27
本篇博文主要内容为 2026-01-27 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-27)
今日共更新800篇论文,其中:
自然语言处理共145篇(Computation and Language (cs.CL))
人工智能共217篇(Artificial Intelligence (cs.AI))
计算机视觉共144篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共219篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] ctELM: Decoding and Manipulating Embeddings ...
Arxiv今日论文 | 2026-01-26
本篇博文主要内容为 2026-01-26 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-26)
今日共更新368篇论文,其中:
自然语言处理共66篇(Computation and Language (cs.CL))
人工智能共106篇(Artificial Intelligence (cs.AI))
计算机视觉共66篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共86篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Strategies for Span Labeling with Large Langua ...
Arxiv今日论文 | 2026-01-23
本篇博文主要内容为 2026-01-23 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-23)
今日共更新445篇论文,其中:
自然语言处理共77篇(Computation and Language (cs.CL))
人工智能共156篇(Artificial Intelligence (cs.AI))
计算机视觉共84篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共105篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] LLM -in-Sandbox Elicits General Agent ic Inte ...
Arxiv今日论文 | 2026-01-22
本篇博文主要内容为 2026-01-22 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-22)
今日共更新517篇论文,其中:
自然语言处理共81篇(Computation and Language (cs.CL))
人工智能共155篇(Artificial Intelligence (cs.AI))
计算机视觉共97篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共129篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Robust Fake News Detection using Large Langua ...