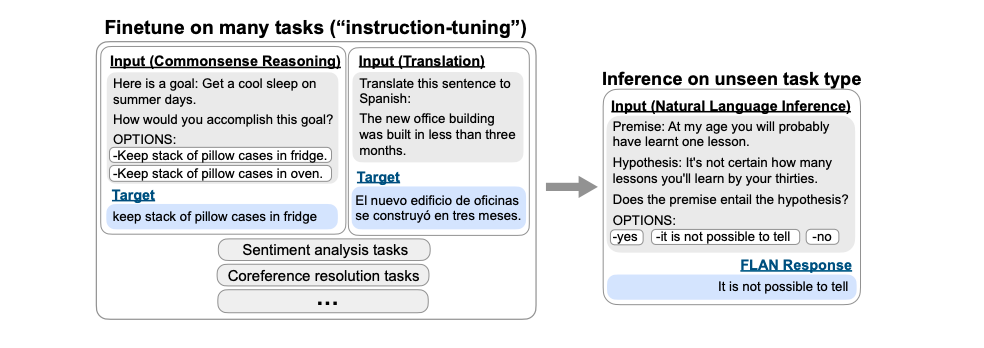
零样本信息抽取(Information Extraction,IE)旨在从无标注文本中建立IE系统,因为很少涉及人为干预,该问题非常具有挑战性。但零样本IE不再需要标注数据时耗费的时间和人力,因此十分重要。近来的大规模语言模型(例如GPT-3,Chat GPT)在零样本情况下取得了很好的表现,这启发我们探索基于Prompt的方法来解决零样本IE任务。我们提出一个问题:不经过训练来实现零样本信息抽取是否可行?我们将零样本IE任务转变为一个两阶段框架的多轮问答问题(Chat IE),并在三个IE任务中广泛评估了该框架:实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的6个数据集上的实验结果表明,Chat IE取得了非常好的效果,甚至在几个数据集上(例如NYT11-HRL)上超过了全监督模型的表现。我们的工作能够为有限资源下IE系统的建立奠定基础。
介绍
信息抽取目标是从无结构文本中抽取结构化信息,包括实体-关系三元组抽取(entity-relation extract, RE)、命名实体识别(named entity recognition, NER)和事件抽取(event extraction, EE),是自然语言处理中基础而重要的一环。许多研究已经开始依赖IE技术来自动化进行零样本/少样本工作,例如clinical IE。
近来大规模预训练语言模型(Large-scale pre-trained Language Model, LLMs)在许多下游任务上都表现极佳。甚至仅仅通过几个例子作为引导而不需要微调就能实现。我们提出一个问题:在一个统一框架下通过提示LLMs来实现零样本IE任务是否可行?这个问题很复杂,因为包含多个依赖关系的结构化文本很难在一次性预测中提取,尤其是像RE这样的复杂任务。前人工作将这些复杂任务解构成不同的部分并且对每一部分都训练成不同的模块,比如RE任务中的流水线方法PURE,首先识别出两个实体,然后预测它们之间的关系。但该方法需要标注数据,于是也有方法将RE视为一个问答过程,首先抽取头实体,再根据关系列表抽取尾实体。
方法
我们的研究对象是Chat GPT,且假设它能够用统一的方式在零样本情况下交互完成IE模型。
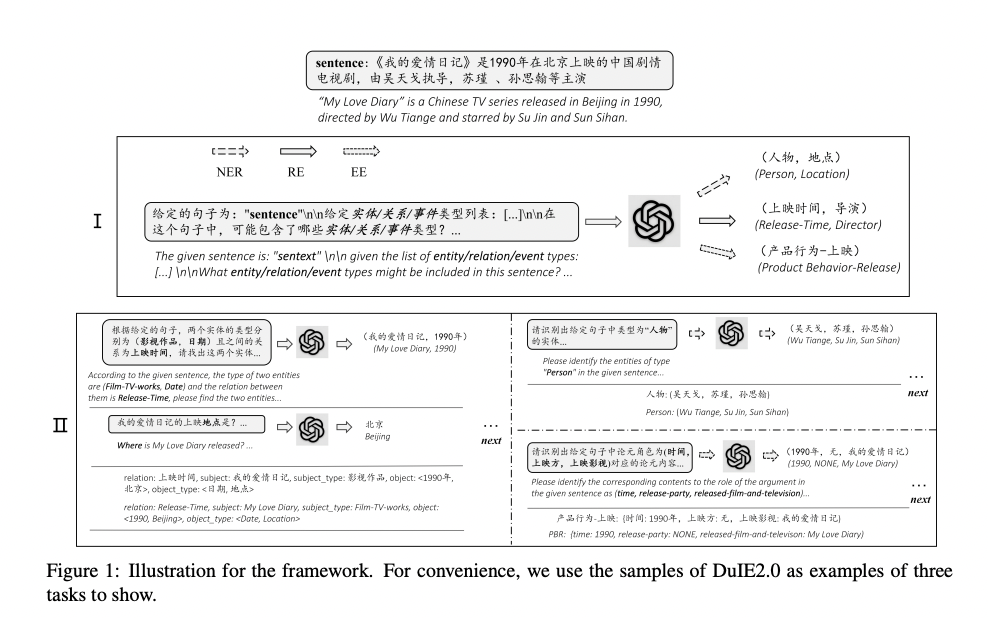
零样本IE的多轮问答框架
我们将IE问题分解成了两个阶段,每阶段都包含多次问答。在第一阶段,我们想要找到文本中存在的实体、关系或者事件类型以减小搜索空间和计算复杂度。在第二阶段里,我们根据前面抽取的类型和给定的对应列表,进一步抽取出相关信息。该方法的大致框架如上图所示。
-
第一阶段:对于每个样例,该阶段一般只有一次问答。为了找到句子中的类型,首先使用任务特定的问题模板和类型列表来构建问题,然后将问题和句子结合后一起送入Chat GPT。我们要求Chat GPT以列表形式返回答案,若句子中不存在任何类型的目标元素,则要求系统生成返回“NONE。
-
第二阶段:这一阶段一般包含多次问答。首先我们根据任务类型设计了一系列链式抽取模板。链式抽取模板定义了一个问题模板链,一般来说这个链的长度都是一,但对复杂的模型(比如RE中的复杂目标值抽取)来说链的长度大于一。在这里,一个元素的提取有可能依赖于另一个元素,因此称其为链式模板。我们根据之前抽取出的类型顺序(同时也是链式抽取模板的顺序)进行多次问答。为了生成问题,我们需要检索具有元素类型的模板,并在必要时填充相应的槽。我们将其送入Chat GPT并得到回答,根据每一轮提取的元素组合成结构化信息。同样要求以列表形式返回、在搜索不到时生成返回“NONE”。
在IE任务上的应用
- 实体-关系三元组抽取
给定句子和问题prompt ,模型应预测三元组,其中属于,表示潜在三元组类型的列表。预测过程正式的表达式为:
其中代表第一阶段中用关系类型列表和对应模板生成的问题,是第二阶段中用相关模板生成的问题。若我们在第二阶段省去了,因为Chat GPT可以记录每次对话的信息。此外,对于复杂目标值(有多个属性的尾实体)我们还需要多几次对话。
命名实体识别
第一阶段过滤出句子中存在的实体类型,并据此构建出第二阶段的输入。第二阶段中,每一次对话的目标是提取出一种类型的实体,因此第二轮对话的次数却决于第一轮过滤出的实体类型数。在实际实验中,并未考虑BIO标注,因为这对Chat GPT来说有些困难。
事件抽取
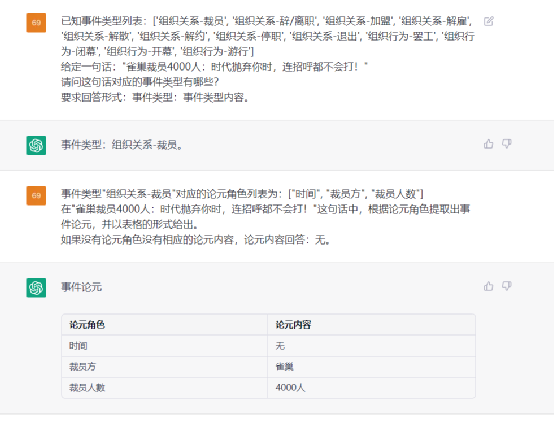
第一阶段是事件分类,从给定文本中获得事件类型的文本分类。第二阶段是论元抽取,提取机器阅读理解(MRC)问题,识别与阶段一预测的事件类型相关的特定角色的论元。
实验结果
数据
RE任务选择的数据集为:NYT11-HRL和DuIE2.0,测评标准分别选用宽松标准和紧致标准,因为前者没有实体类型标注。NER选择的数据集为:conllpp和MSRA,评测标准使用紧致标准。EE选择的数据集为:DuE E1.0和ACE05,分别对词级别匹配评分和实体级别匹配评分。
结果
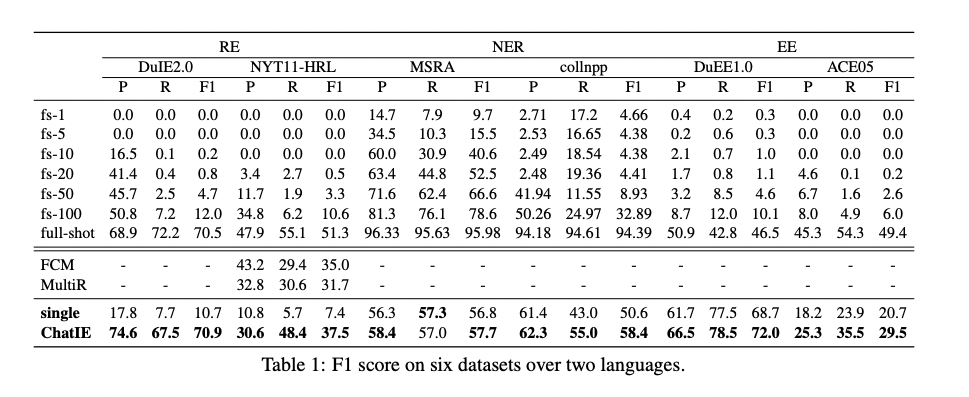
从上表中,我们观察到原始Chat GPT(只用单轮问答)在IE问题上表现不佳,而我们的两阶段法表现更好。在6个IE数据集上,Chat IE的性能平均提高了18.98%。而与少样本方法相比,我们的收益更加显著。对每个少样本的实验,我们随机选择三组训练数据,每组训练三次并统计平均结果。基线模型选择PaddleNLP LIC2021 IE,CaseRel,AdaSeq Bert-CRF,PaddleNLP LIC2021 EE和Text2event。在MSRA上,Chat IE的零样本表现在20个样本下的基线模型表现相当;在NYT11-HRL,collnpp和ACE05上,Chat IE的表现超过了100个样本下的基线模型;在DuIE2.0和DuE E1.0上,Chat IE甚至超过了全样本下的基线模型。
此外,在NYT11-HRL上,与两个全监督模型FCM[9]和MultiR[10]相比,Chat IE分别超过了2.5%和5.8%。监督学习模型是计算密集的,还需要高质量的标记数据,且对每个任务来说都要从头开始训练单个模型。相比之下,Chat IE不需要任何微调或训练来更新参数,极大减少了计算量和时间成本。
样例展示
- RE示例
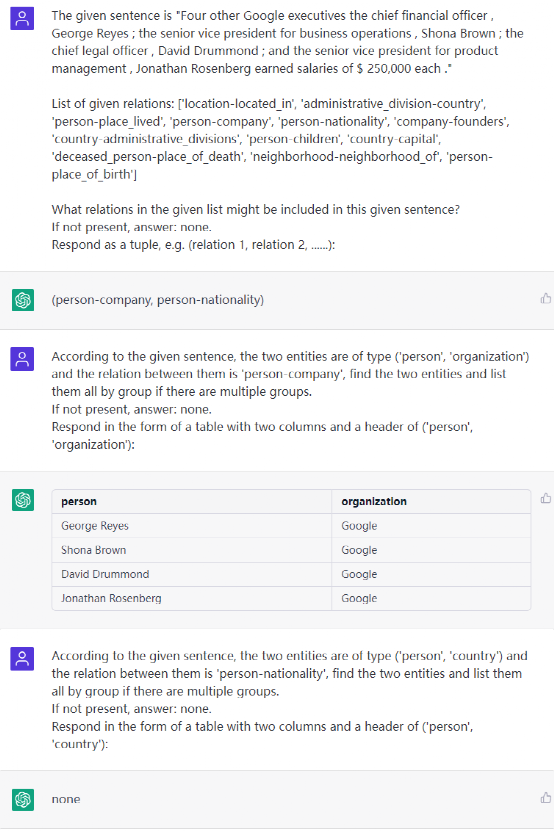
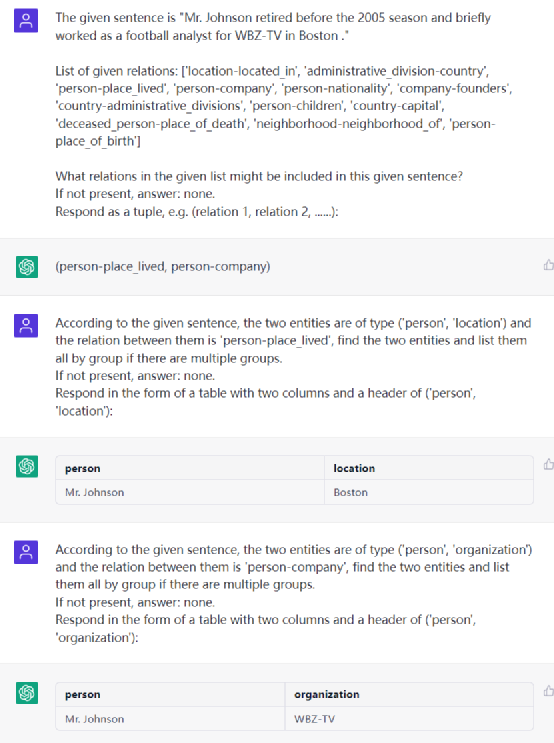
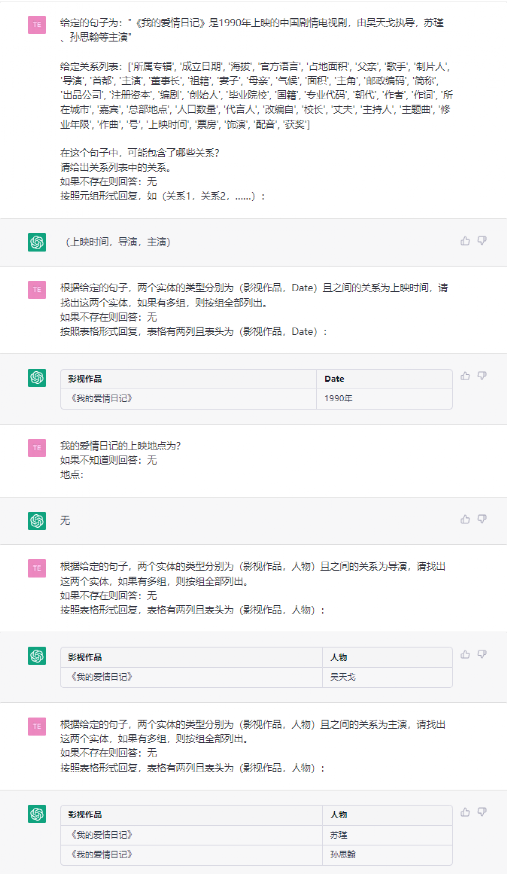
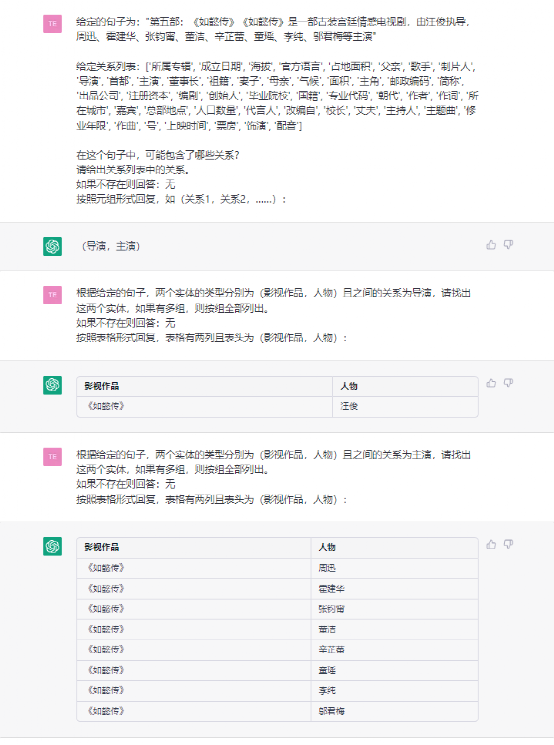

总结
我们提出了Chat IE,一个基于Chat GPT的多轮问答框架用于零样本信息抽取。在这种互动模式下,Chat IE能够将复杂的IE任务分解成几个部分。我们在RE、NER和EE任务上进行了六个数据集上的实验,并证明了框架的有效性。Chat IE获得了很好的表现,甚至有些数据集上超过了全样本的模型。我们的工作为零样本IE任务提供了一个新的范式,在此范式中IE任务被分解为更多简单的子任务,定义了类似对话的提示,并且直接使用他们,不需要训练和微调。