本文探讨了一种简单的方法来提高大型语言模型在零样本情况下的性能,名为instruction tuning,它在多个数据集集合上微调语言模型,从而大大提高了未知任务上的零样本性能。本文采用一个137B参数的大型语言模型, 通过自然语言指令模板在60多个NLP数据集上进行instruction tune。本文将这个instruction-tuned模型称为FLAN,并在unseen任务上对模型进行评估。结果表明,FLAN在25个数据集中的20个上超过了零样本学习的175B GPT-3。FLAN甚至在ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze上都远远优于few-shot小样本学习的GPT-3。消融研究表明,微调数据集的数量、模型规模和自然语言指令是 instruction tuning 成功的关键。
FLAN
Instruction Tuning和Prompt的核心一样,就是去发掘语言模型本身具备的知识。而他们的不同点就在于,Prompt是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做language model任务,它的模版是这样的:

而Instruction Tuning则是激发语言模型的理解能力,通过给出更明显的指令/指示,让模型去理解并做出正确的action。比如NLI/分类任务:
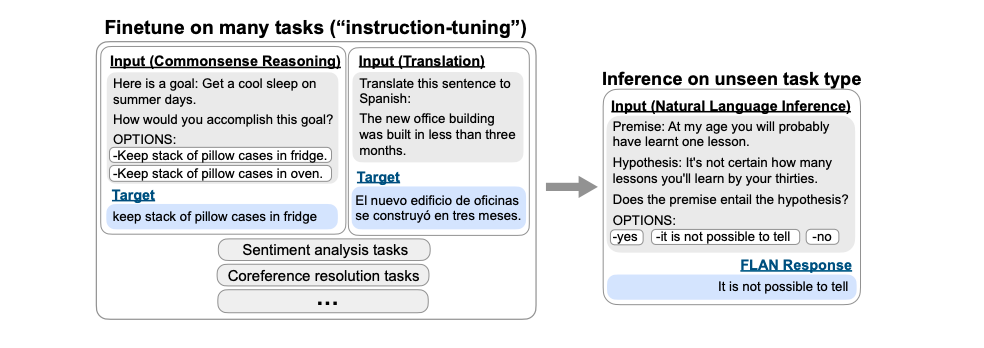
例如,我们的最终目标是推理任务,FLAN首先讲语言模型在其他任务上进行微调,包括给定任务指令的翻译、常识推理、情感分类等。在面对翻译任务时可以给出指令“请把这句话翻译成西班牙语”。在面对常识推理任务时可以给出指令“请预测下面可能发生的情况”,而当模型根据这些“指令”完成了微调阶段的各种任务后(将指令拼接在微调数据的前面),在面对从未见过的最终需要的自然语言推理任务的指令“这段话能从假设中推导出来吗?” 时,就能更好地调动出已有的知识回答问题。
Instruction tuning的动机是为了提高语言模型对NLP instructions的响应能力。其想法是,通过监督来教LM执行Instructions描述的任务,从而使它将学习到如何遵循instructions,当面对unseen的任务时,模型自然而然地就会遵循instruction做出响应。
数据集
文章收集62个文本数据集,包括语言理解和语言生成任务。
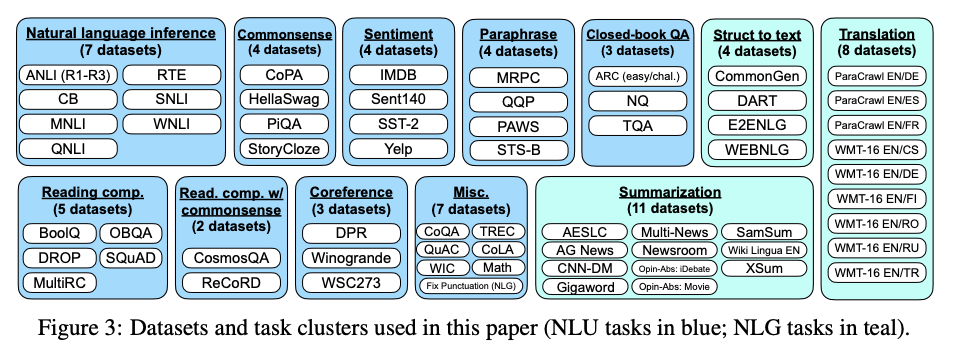
如上图所示,每个数据集被分到12个任务群中的一个,其中给定群中的数据集具有相同的任务类型。对于每个数据集,本文手工构建了10个独特的模板,这些模板使用自然语言instructions 来描述该数据集的任务。这10个模板中的大多数描述了原始任务,但为了增加多样性,对于每个数据集,还包括最多三个“turned the task around”的模板(例如,对于情感分类,要求生成电影评论的模板)。然后,将所有数据集混合后,对预训练语言模型做instruction tuning。其中每个数据集的template都是随机选取的。下图显示了一个自然语言推理数据集的多个instruction templates。

划分
本文感兴趣的是FLAN在面对instruction tuning中没见过的任务时的表现。因此定义什么是unseen的任务是至关重要的。 虽然之前的一些工作通过【不允许同一数据集在训练中出现】来定义unseen的任务,但本文使用了一个更保守的定义,它利用了所谓的任务集群。举例:如果数据集D作为unseen task进行评估,而D属于NLI任务,那么所有NLI中的数据集都不能再instruction tune中出现。
分类
给定任务的输出空间有两种,分别是分类式输出和自由文本(生成)。由于FLAN是只有transformer的decoder的语言模型的instruction-tuned版本,它自然会自由文本生成,因此生成任务不需要进一步的修改。对于分类任务,之前的工作使用了一种排名分类方法,例如,只考虑两个输出(“是”和“不是”),并以较高概率的一个作为模型的预测。尽管该程序在逻辑上是合理的,但其不完美之处在于,答案的概率质量可能在表示每个答案的方式中具有不期望的分布(例如,大量表示“是”的替代方式可能会降低分配给“是”的概率质量)。因此,本文设置了一个options suffix 选项后缀,在该后缀中,将token OPTIONS与该任务的输出类列表一起附加到分类任务的末尾。这使模型知道在分类任务时需要哪些选择。
训练
模型结构与预训练。在实验中,本文使用了一个密集的从左到右、仅限解码器的137B参数 transformer 语言模型LaMDA-PT。该模型在web文档(包括带有计算机代码的文档)、对话数据和Wikipedia的集合上进行预训练,并使用SentencePiece库将其标记为2.81TBPE tokens和32k词汇表。大约10%的训练数据是非英语的。该数据集不像GPT-3训练集那样干净,而且还混合了对话和代码,因此可以预计这种预训练LM在NLP任务上的零样本和小样本性能会稍低。
在Instruction-tuning阶段,混合了所有数据集和每个数据集的随机样本示例。有些数据集有超过1000万个训练示例(例如,机器翻译),因此本文将每个数据集的训练示例数量限制为30000个。同时,存在一些数据集,它们的训练示例数量比较少(例如,CommitmentBank只有250个),为了防止这些数据集被边缘化,本文采用示例-比例混合方案,混合率最大为3000。fine-tunine模型30000个step,每个step的batch size为8192,优化器为Adafactor,学习率3e-5,输入输出长度分别为1024和256。
结果
本文从自然语言推理、阅读理解、闭卷问答、翻译、常识推理、共指消解和文本结构等方面对FLAN进行评估。按照上文描述的定义,本文把数据集按照所涉及的领域分为cluster,并分别将每个cluster设置为unseen task进行评估。对于每个数据集,本文对十个template都做了测试,并求出结果的平均值和标准差。这代表了所谓“典型”的natural language instruction的预期性能。同时也保留了其中的最优结果。
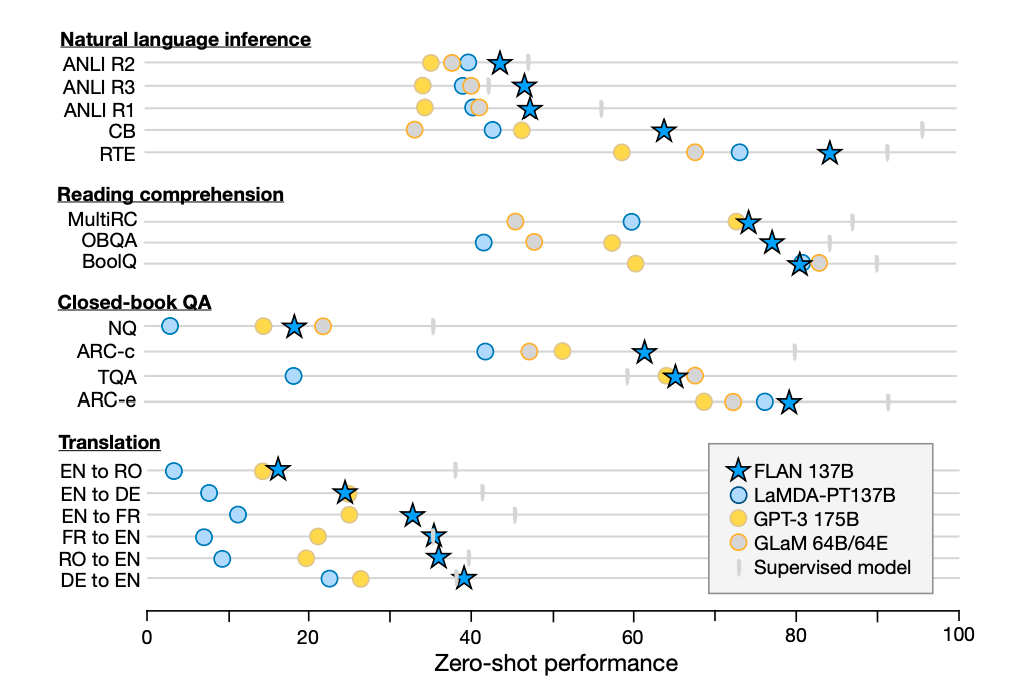
作为比较,本文给出了LaMDA-PT的zero-shot和few-shot结果,LaMDA-PT使用GPT-3的prompt。这个实验最直接的体现出了instruction tuning到底效果如何。实验结果表明,instruction tuning确实在大多数的数据集上都提升了模型性能。
同时,本文也展示了GPT-3 175B版本和GLaM 64B/64E版本的zero-shot结果,如果用刚才提到的保留的最好template结果来比较,zero-shot FLAN在25个数据集中的20个都取得了比GPT-3更好的效果。甚至在10个数据集上比few-shot GPT-3的结果都要好。在GLaM上也有着类似的效果。
总的来说,可以观察到,instruction tuning对于自然表述为指令的任务(例如NLI、QA、翻译、结构到文本)非常有效,而对于直接表述为语言建模的任务(其中instructions在很大程度上是冗余的)则不太有效(例如,常识推理和共指消解任务,格式为完成一个不完整的句子或段落)。NLI、阅读理解、闭卷QA、和翻译的结果如下图所示
消融实验
本文的核心问题就是研究instruction tuning到底是怎么提升模型对于unseen task的性能。为此,本文的第一个消融实验主要是研究cluster和task数量对instruction tuning性能的影响。本文将NLI、闭卷QA、和常识推理作为评估对象,并选择其他七个cluster用作instruction tuning。文章展示了依次增加instruction tuning的cluster数目带来的结果变化,如下图所示:
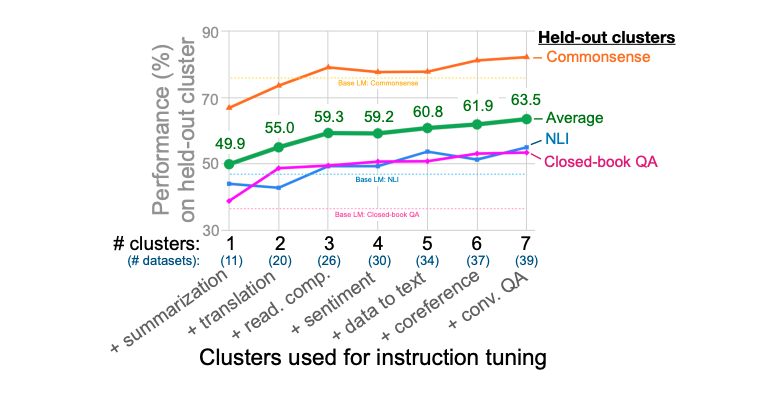
可以看到随着tuning的cluster不断增加,模型的效果越来越好。这证明cluster数量越多,tuning的效果越好,同时并没有看到增长的上限,这意味着当不断地增加cluster数量时,模型可能会达到更好的效果。
由于之前的工作证明,无论是语言模型的zero-shot能力还是few-shot能力,都会随着模型体量的增大而增强。第二个消融实验,探索的是模型体量对instruction tuning的影响。保持上一个消融实验的设定,本文评估了422M,2B,8B,68B以及137B参数量的模型的效果,结果如下图所示:
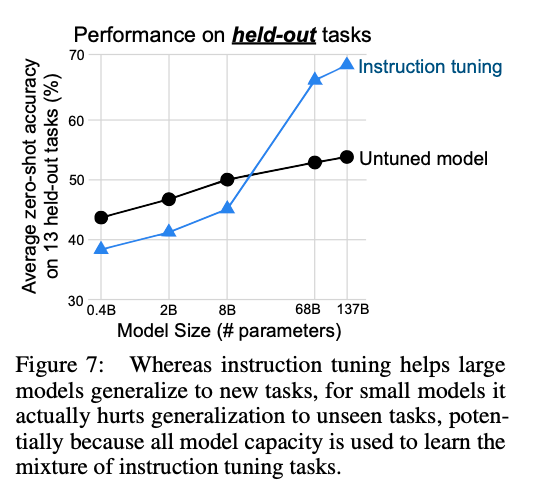
可以看到,和不做tuning的模型比,当参数量高时,instruction tuning可以达到更好的效果,这也和本文主实验的结果相印证,但是,对于较小的模型,instruction tuning反而降低了模型的性能。一种可能的解释是,学习instruction tuning中的内容已经占据了模型的整个容量,使其在面对新任务时表现不佳。而大容量的模型在做tuning的同时,还有余量学习如何听从instruction,这让他们在面对新任务时取得更好的效果。
最后一个消融实验,主要研究的是instruction本身的设定对tuning起着怎样的作用。因为有一种可能是,由于cluster的堆积,fine-tuning过程不需要instruction的设计也能达到很好的效果。由此,本文设计了两种fine-tuning模式,他们都不带有instruction。一种叫做no template设定,只提供给模型输入和输出。另一种叫做dataset name设定,它在输入前面拼接上task和数据集名称。对比结果如下图所示:

两种消融设置的性能都比 FLAN 差得多,这表明使用instruction进行训练对于在未见过的任务上的零样本性能至关重要。
总结
这篇文章主要就是探索一个简单的问题:在一组task上微调模型是否会提高模型在unseen task上的性能。本文通过instruction tuning来回答这个问题,instruction的本质特性是pretrain-finetuning和prompt的结合。事实证明,本文提出的FLAN方法确实取得了非常显著的提升。一系列的消融实验证明,做instruction tuning的task数量越多,模型的效果越好。并且,instruction tuning性能的保障需要足够体量的模型做支持。instruction tuning对跨任务泛化的积极影响表明,特定于任务的训练是对通用语言模型的补充,并激发了对通用模型的进一步研究。