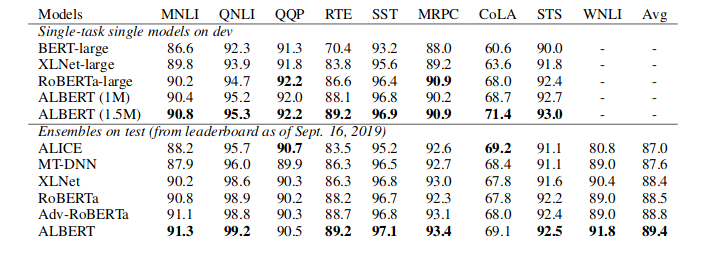
近年来,Transformer网络结构广泛应用于自然语言处理的各项任务,并且获得了非常好的效果。然而 Transformer 结构的优化非常困难,其具体表现有 warm-up 阶段超参数敏感、优化过程收敛速度慢等问题。本文作者从理论上详细分析了 Transformer 结构优化困难的原因,通过将 Layer Normalization 放到残差连接中的两个子层之前,并且在整个网络最后输出之前也增加一个 Layer Normalization 层来对梯度进行归一化,即 Pre-LN Transformer,可以让 Transformer 彻底摆脱 warm-up 阶段,并且大幅加快训练的收敛速度。
方法
在优化 Transformer 结构时,除了设置初始学习率与它的衰减策略,往往还需要在训练的初始阶段设置一个非常小(接近0)的学习率,让它经过一定的迭代轮数后逐渐增长到初始的学习率,这个过程也被称作 warm-up 阶段。warm-up可以看做是学习率随迭代次数t的函数,即:
warm-up 在训练初始阶段使用较小的学习率来优化,当达到设置的之后,以某种常见的学习率 decay方式进行变化。warm-up 是原始 Transformer 结构优化时的一个必备学习率调整策略。Transformer 结构对于 warm-up 的超参数(持续轮数、增长方式、初始学习率等)非常敏感,若调整不慎,往往会使得模型无法正常收敛。
为了研究warm-up以及的大小对训练Transformer结构的影响,本文作者在 IWSLT14 De-En 翻译数据集上进行验证,采用 Adam 和 SGD 两种随机优化器,分别测试了不同大小的学习率,对于Adam采用和,对于SGD采用和,并分别在没有 warm-up(0轮), warm-up 迭代轮数不足(500轮)和迭代轮数充足(4000轮)情况下模型的验证集 Loss 与 BLEU 分数,下图是相关的结果
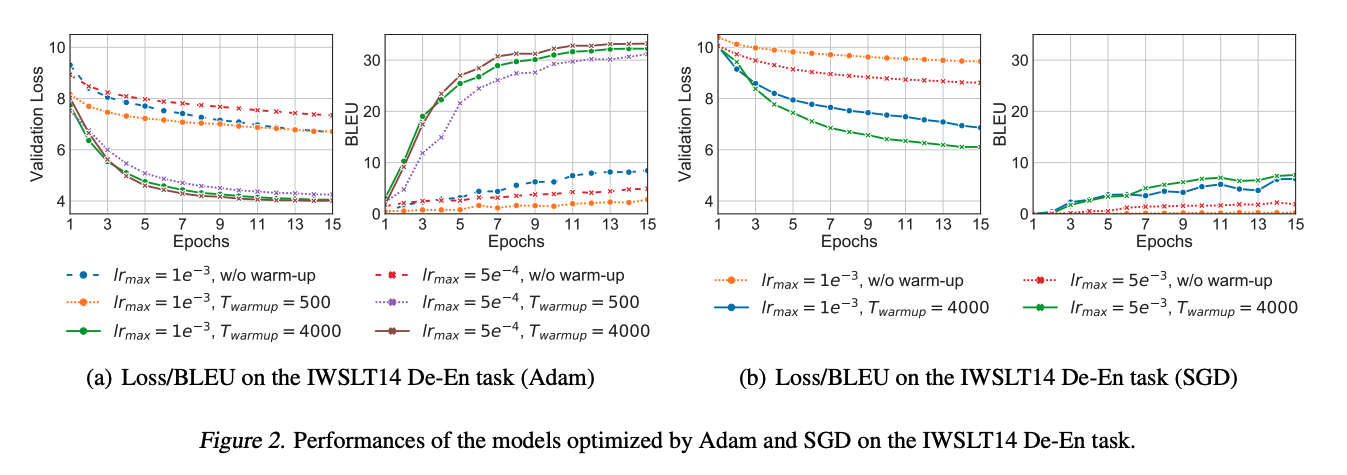
从实验中可以看出:
- 无论是Adam还是SGD,warn-up都相当必要,如果没有warm-up,模型结果都相当差。
- 模型性能对warm-up 所需迭代轮数还是学习率的大小都非常敏感。
- 在训练的开始阶段,loss很大,如果使用很大的学习率,则模型很容易崩溃。
总的来说,模型性能对warm-up相关参数非常敏感,如果需要获得一个很好的性能,则需要对相应的参数进行精细地调参,这对于训练大型的NLP网络结构而言,是非常耗时的。
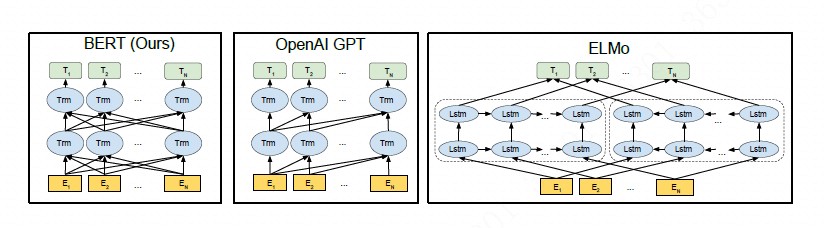
由于 Transformer 优化困难的阶段是在训练的初始阶段,warm-up 也只是在迭代的前若干轮起作用,因此我们从模型的初始化阶段开始探究原因。如下图所示,原始 Transformer 结构的每一层中分别经过了带残差连接的 Multi-Head Attention 和 FFN 两个子层(sub-layer),在两子层之后分别放置了层归一化(Layer Normalization)层,即 Post-LN Transformer。
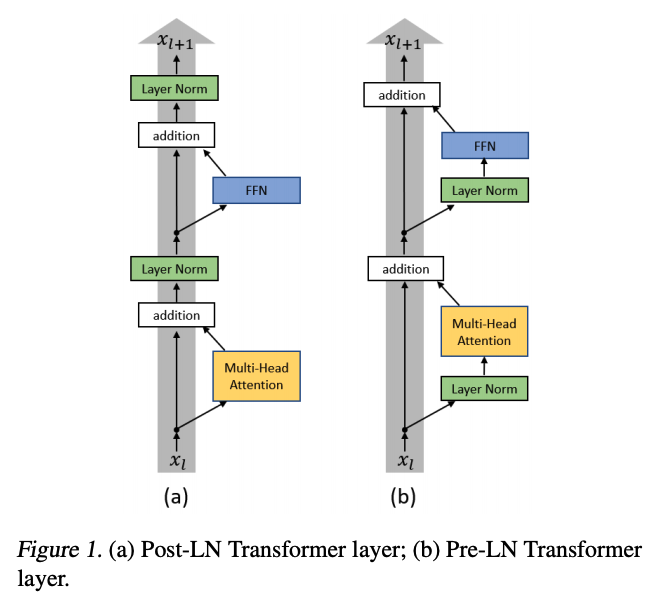
当采用 Xavier 方法对 Post-LN Transformer 进行初始化后,通过对各隐层梯度值进行分析可以证明,在初始化点附近的 Post-LN Transformer 结构最后一层的梯度值非常大,同时随着反向传播的前传会导致梯度值迅速衰减。这种在各层之间不稳定的梯度分布必然会影响优化器的收敛效果,导致训练过程初始阶段的不稳定。造成 Post-LN Transformer 梯度分布出现问题的核心原因在于各子层之后的 Layer Normalization 层会使得各层的输入尺度与层数 L 无关,因此当 Layer Normalization 对梯度进行归一化时,也与层数 L 无关。
将 Layer Normalization 放到残差连接中的两个子层之前,并且在整个网络最后输出之前也增加一个 Layer Normalization 层来对梯度进行归一化,我们称这样的结构为 Pre-LN Transformer[,如上图所示。
使用相同的方法对 Pre-LN Transformer 结构进行分析后,发现最后一层 Layer Normalization 层的输入尺寸的量级只有 Post-LN 的倍,并且每个 LN 层都会对梯度以 的比例归一化。所以对于 Pre-LN 结构来说,其每层梯度范数都近似不变。
实验
为了验证两种结构的差异性,本文作者在 IWSLT 14 De-En 数据集对两种结构在初始化附近以及经过了 warm-up 阶段的梯度范数进行了验证,结果如下:

可以看出:
- 在进行一定轮数的 warm-up 后,Post-LN 的梯度范数也基本保持不变,并且其量级非常小(图4中绿色),说明,warm-up的确有助于训练的稳定性。
- 相比于 Post-LN 结构梯度分布的不稳定,Pre-LN 在各层之间梯度范数几乎保持不变,这种结构明显更利于优化器进行优化。
在 IWSLT、WMT 和 BERT 三个任务上验证了是否可以在 Pre-LN 结构中去掉 warm-up,结果如下:
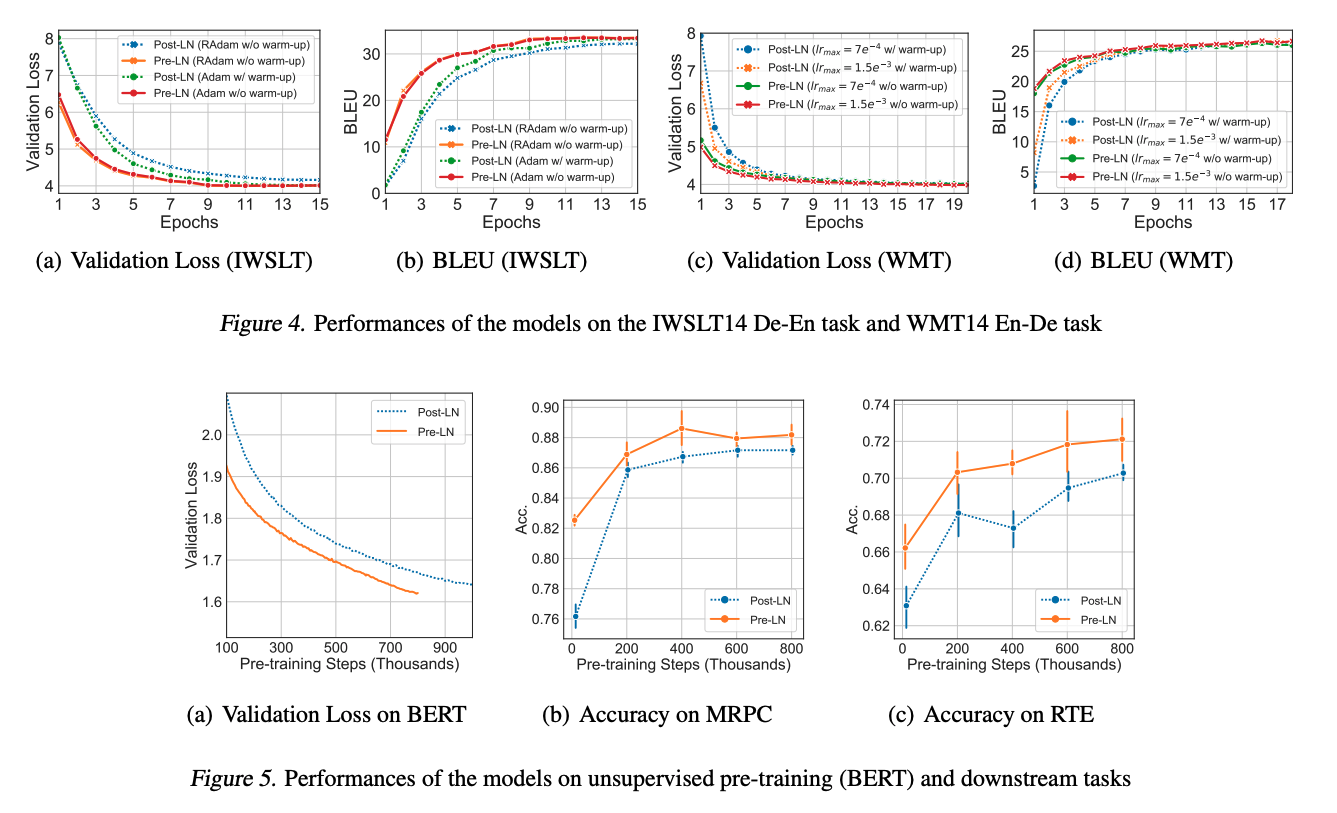
可以看出:
- 当使用 Pre-LN 结构时,warm-up 阶段已经不再是必需,并且 Pre-LN 结构可以大幅提升 Transformer 的收敛速度。
- 对于机器翻译任务(IWSLT/WMT),不需要 warm-up 的 Pre-LN 结构收敛更快。
- 对于无监督预训练的结果,Pre-LN 收敛更快,效果更好。
Pre-LN在底层的梯度往往大于顶层,导致其性能不及Post-LN。该篇文章中比较的是在完全相同的训练设置下 Pre Norm 的效果要优于 Post Norm,这只能显示出 Pre Norm 更容易训练,因为 Post Norm 要达到自己的最优效果,不能用跟 Pre Norm 一样的训练配置(比如 Pre Norm 可以不加 Warmup 但 Post Norm 通常要加),具体可参考《Understanding the Difficulty of Training Transformers》和《RealFormer: Transformer Likes Residual Attention》
小结
本文别出心裁,用实验和理论验证了Pre-LN Transformer结构不需要使用warm-up的可能性,其根源是LN层的位置导致层次梯度范数的增长,进而导致了Post-LN Transformer训练的不稳定性。本文很好进一步follow,比如Residual和LN的其他位置关系,如何进一步设计初始化方法,使得可以完全抛弃warm-up等。