本文介绍字符嵌入,从字符的角度考虑embedding问题。
字符嵌入
机器学习需要输入数值数据,类似于文本数据需要转化为数值型,因此,词嵌入是常用的将文本数据转化为数值数据的方法,比如像word2vec算法,你可以获取一个单词的数值表示,并且可以使用这些数值向量得到句子/段落/文本等数值表示。

但是,训练一个数据集的词向量模型可能非常昂贵。解决这一问题的学术方法是使用预先训练的词向量模型进行单词嵌入,例如斯坦福大学的研究人员收集的Glove向量。然而,GLove向量非常大,;最大的一种(300维,约8400亿tokens)在磁盘上是5.65 GB,在不太强大的计算机上加载时可能会遇到内存不足问题。
为什么不使用字符嵌入呢?你可以计算相对较少的向量,而且可以将这些向量加载到内存中,并使用这些向量来衍生出单词向量,进而可以用来衍生出句子/段落/文档/等向量。但是,训练字符嵌入在计算上更加昂贵,因为字符的数量比tokens多5-6倍左右.
为什么不使用现有的预先训练的单词嵌入来推断单词中相应的字符嵌入?借鉴“bag-of-words“,思考“bag-of-characters”。例如,“the”一词的嵌入,我们可以从父字中推断出“t”、“h”和“e”的嵌入,并且在数据集语料库中从所有单词/标记中求平均得到t/h/e向量。(对于这篇文章,我只用840B/300D数据集,因为这是唯一一个包含大写字母的数据集,这是相当重要的。如果您想要使用较小维度的数据集,可以应用PCA等降维技术。
我编写了一个简单的Python脚本,该脚本接受指定的预先训练的单词嵌入,并以相同的格式输出字符嵌入。(为了简单起见,只包含ASCII字符;由于兼容性的原因,扩展的ASCII字符被故意省略了。另外,通过构造,空间和换行符在派生数据集中没有表示)。
1 | import numpy as np |

接下来,设定一个参考点。Colin Morris发现,在谷歌的10亿个词基准中将一个使用16D的字符嵌入的模型通过t-SNE可视化,可以看到:数字是紧密的,小写字母和大写字母经常成对出现,而标点符号是松散配对的。

对于高维向量来说,t-SNE是很困难的,因为参数的组合会导致不同的输出,所以让我们来做一些预测。使用PCA白化方法将向量维度从300维降到16维,并设置perplexity参数为7的情况。
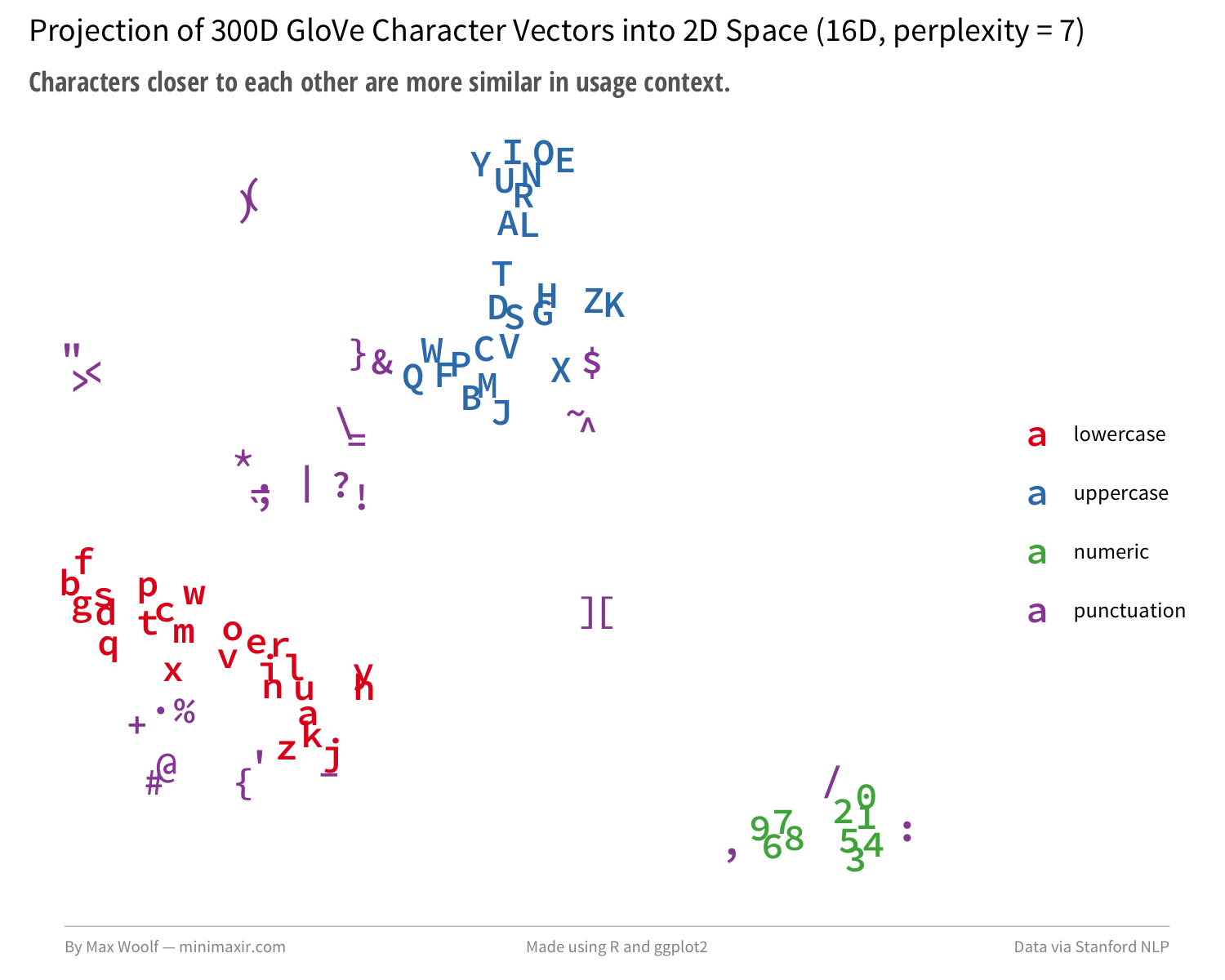
该算法成功地分离和分组小写、大写和数字。将预处理步骤的维数增加到64维,并将perplexity参数设置为2,生成更接近谷歌模型:
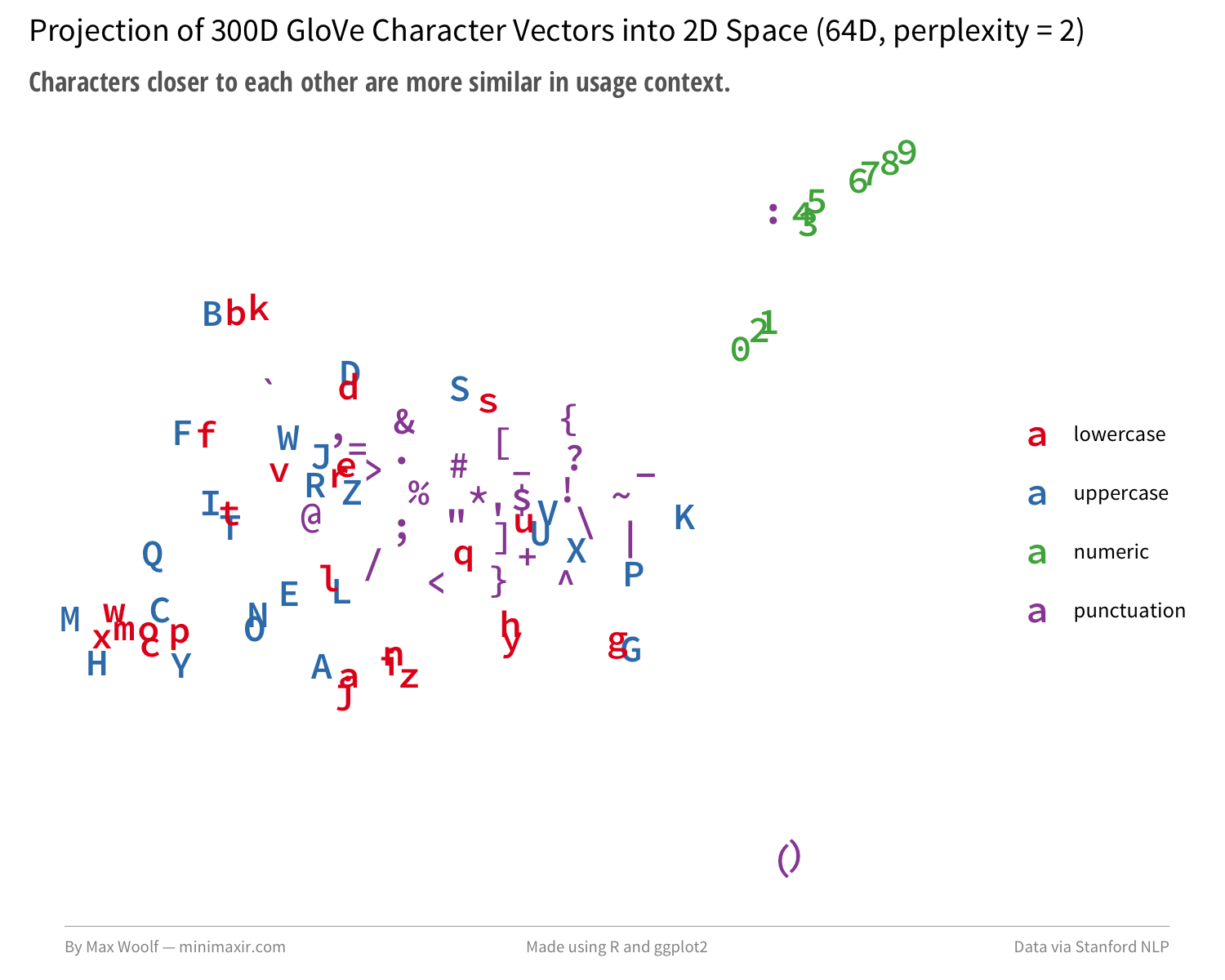
训练的字符嵌入技巧不是学术性的,但它成功地识别了实际的关系。这里可能有值得的东西。
文本生成
Keras官方提供一个例子是把Nietzsche的作品作为一个数据来源。个人认为这个不太好区分是模型自动生成的还是真实的Nietzsche作品。本文使用的是 Magic: The Gathering cards。

由Reed Milewicz的@RoboRosewater推特账户和相应的研究和文章所启发,我的目的是想看看是否有可能为我自己重新创造出结构化的设计创意。
即使你不熟悉魔术和它的规则,你仍然可以找到这张卡片的文字:

有时,使用较弱的模型,RoboRosewater会产生有趣的神经网络火车残骸:

更重要的是,所有的魔法卡片都有一个明确的结构;他们有一个名字,在右上角的法力值,卡片类型,卡片文本,通常是在右下角的力量和韧性。
我编写了另一个Python脚本,将MTG JSON中的所有神奇的卡片数据解析为与此体系结构相匹配的编码,其中每个部分的转换都有自己的符号分隔符,以及其他的简化编码。例如,在我的编码中,这是一个卡片龙。
1 | import json |
1 | [Dragon Whelp@{2}{R}{R}#Creature — Dragon$Flying|{R}: ~ gets +1/+0 until end of turn. If this ability has been activated four or more times this turn, sacrifice ~ at the beginning of the next end step.%2^3] |
这些卡片编码都被合并到一个.txt文件中,它将被输入到模型中。
构建模型
Keras文本生成示例通过将一个给定的.txt文件分解成40个字符序列,模型试图通过输出每个可能字符的概率来预测第41个字符(该数据集中的108)。例如,如果基于上面例子的输入是[‘D’, ‘r’, ‘a’, ‘g’,…“D”、“r”、“a”、“g”]等。根据分类的交叉熵损失函数,模型得到的结果是:用1.0概率值表示正确的预测,0.0概率值表示错误的预测,对半猜测和错误的猜测进行惩罚。
每个可能的40个字符序列被收集,但是只保留其他的第三个序列;这使得模型不能逐字学习卡片文本,而且还能使训练更快。(对于这个模型,最终的训练大约有100万个序列)。这个例子只使用了一个128个节点的长短时记忆(LSTM)递归神经网络(RNN)层,这一层很受人喜欢,因为它将“记忆”合并到一个神经网络模型中,但是在开始的时候,它需要一段时间来训练,然后生成的文本是连贯的。
我们可以做一些优化。不是直接向RNN提供字符,而是首先使用嵌入层对它们进行编码,这样模型就可以训练字符上下文。我们可以通过添加一个2层的多层感知器来在RNN上叠加更多的层:是的,它有帮助,因为网络必须学习数据的潜在表示。还是可以使用新的技术,比如batch normalization(BN)和 rectified linear activations(Relu),它们都可以在没有增加计算开销的情况下进行训练,而且由于Keras,它们都可以被添加到一个带有一行代码的层中。最后,通过Keras API的功能,我们可以添加一个辅助输出,网络使得预测仅仅基于RNN的输出除了主输出,这迫使它更聪明地工作,最终loss大幅降低。
最终的架构是这样的:
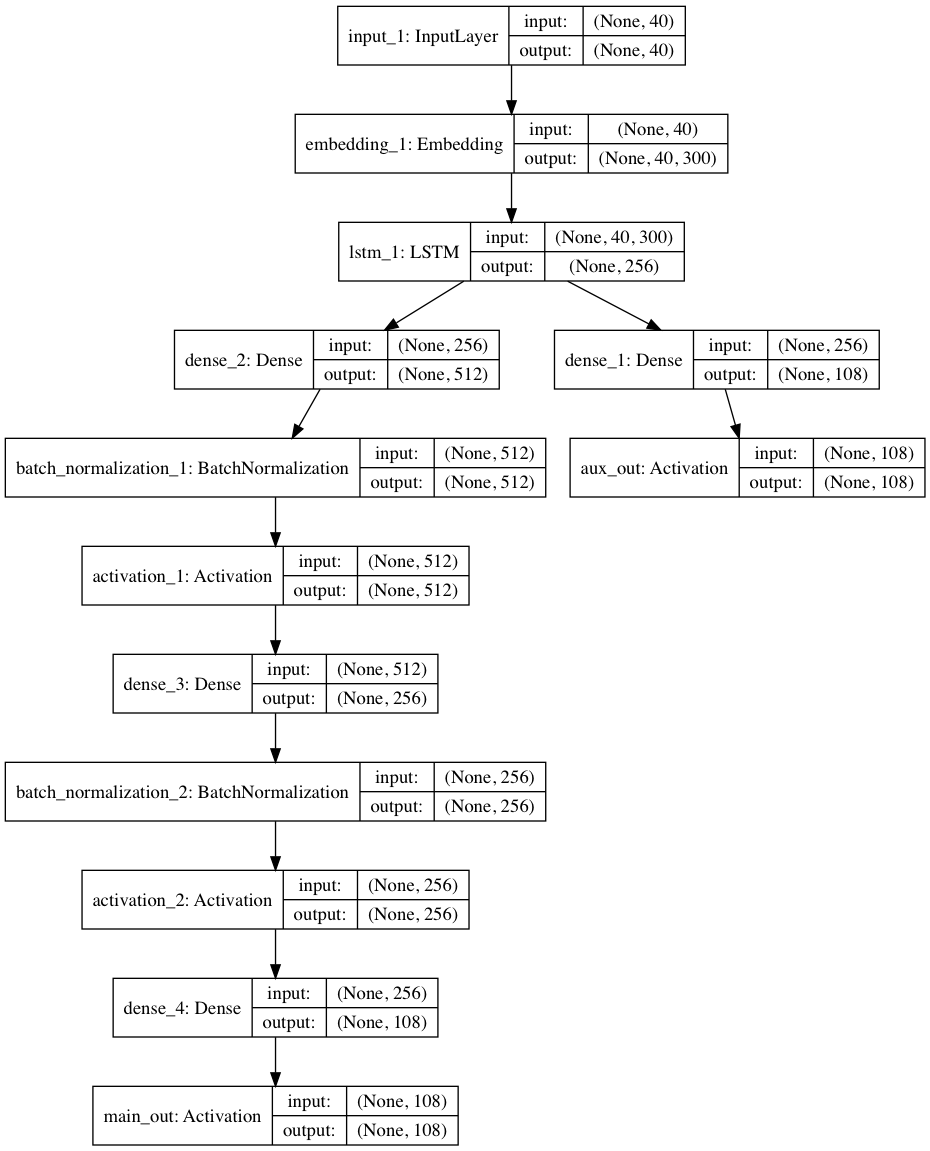
模型代码;
1 | print('Build model...') |
因为我们添加了一个嵌入层,可以加载我之前做过的预训练的300D字符嵌入,这使得模型在理解字符关系方面有了一个良好的开端。
模型训练的目的是使模型的损失最小化。(但是为了评估模型的性能,我们只考虑主要输出的损失)。该模型在epochs中进行了训练,在该模型中,模型至少可以看到所有的输入数据。在每一个epoch,将batch大小为128加载到模型中并进行评估,计算每一个batch的loss;来自批处理的梯度被反向传播到之前的层中以改进它们。在与Keras的训练中, console 显示一个epoch的loss,这是目前为止所有batch loss的平均值,允许用户实时看到模型如何改进,并且它会使人沉迷。
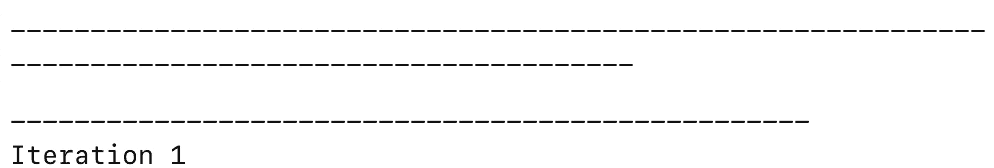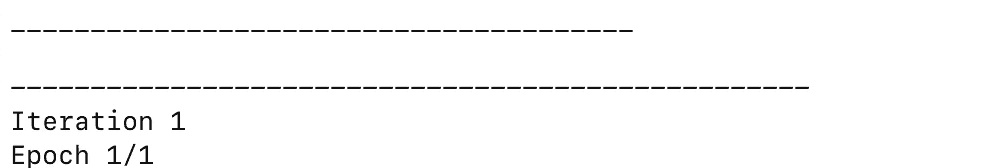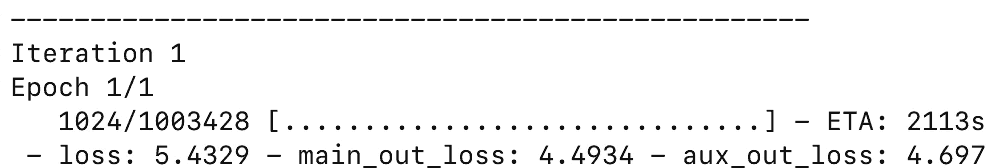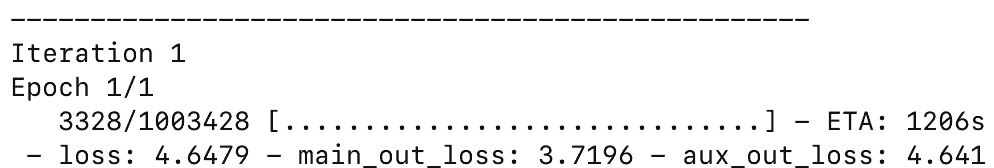
Keras/TensorFlow在CPU上运行良好,但是对于带有RNN的模型,您需要考虑使用GPU来实现性能。Amazon的云GPU实例为$0.90/hr(不是prorated),但是最近,谷歌发布了GPU实例,它的级别为$0.75/hr(按分钟计算),这是我用来训练这个模型的,尽管谷歌计算引擎需要先配置GPU驱动程序。在20个时代,花了4个小时20分钟的时间来训练这个模型,花了3.26美元,这在深度学习上还算不错。
模型可视化
深度学习教程中很少提到的一件事是如何收集loss的数据,并可视化随时间变化的loss。由于Keras的实用功能,我编写了一个自定义模型回调,它收集batch loss和epoch loss,并将它们写入到CSV文件中。
1 | f = open('output/log.csv', 'w') |
使用R和ggplot2,在每第50个batch中画出batch loss,以可视化模型是如何随着时间的推移而收敛的。
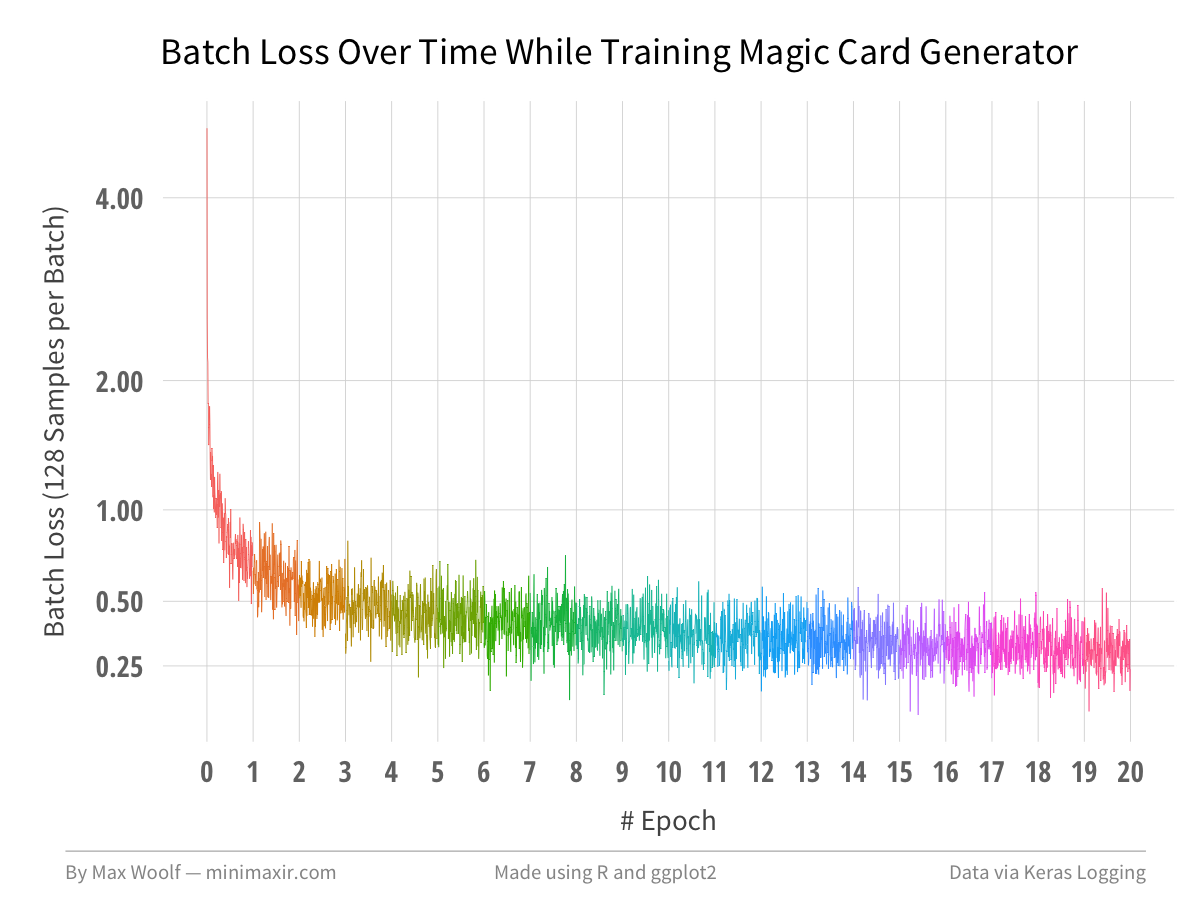
在20个epoch之后,模型损失降到了大约0.30,这足以形成连贯的文本。正如你所看到的,在经历了几个epoch之后,回报就会大大减少,这是训练深度学习模式的难点。
通过可视化,使这一趋势更加清晰。
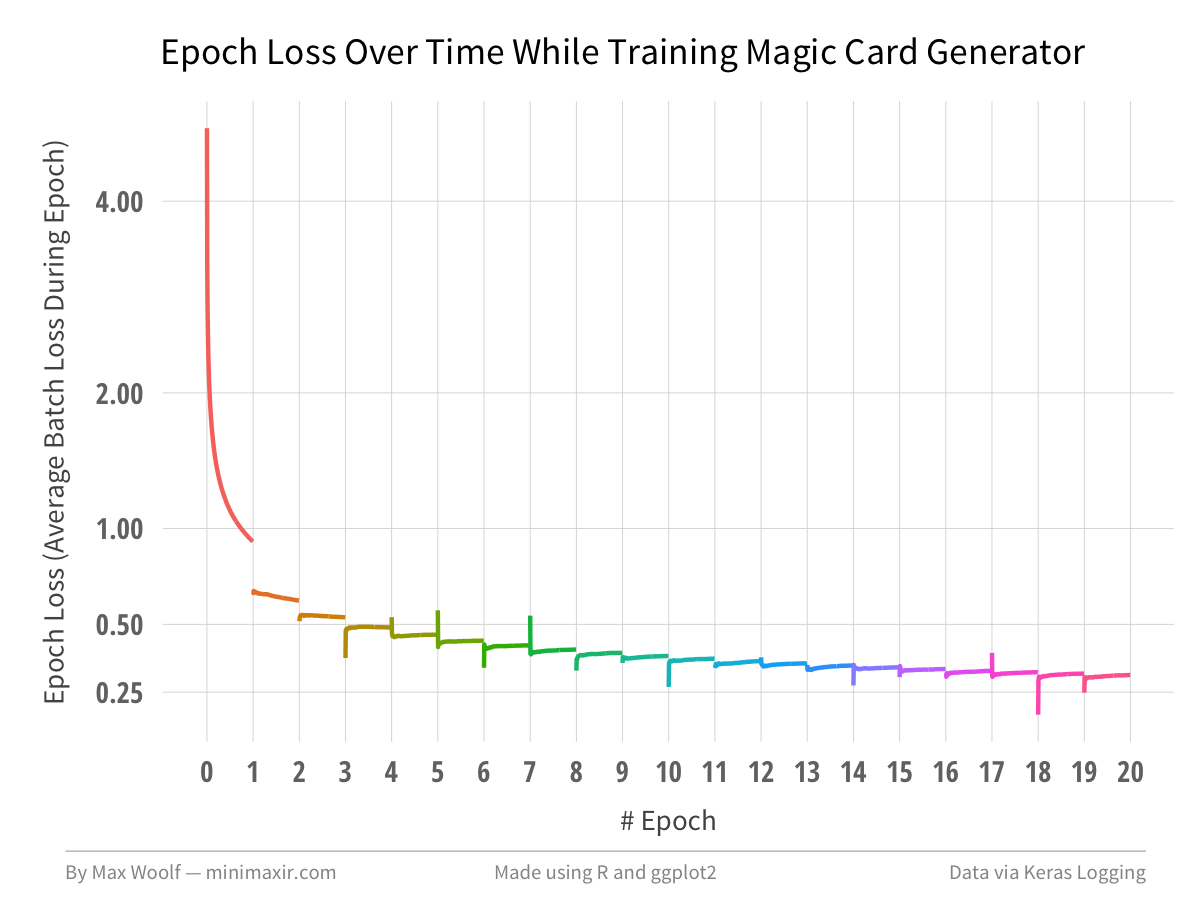
为了防止过早收敛,我们可以使模型变得更复杂(比如堆叠更多层),但是在训练和预测速度方面需要权衡,后者对于在生产应用程序中使用深度学习是很重要的。
最后,与谷歌10亿字的基准测试一样,我们可以从模型中提取出经过训练的字符嵌入(现在用魔卡上下文进行扩充!),然后再将它们绘制出来,看看发生了什么变化。
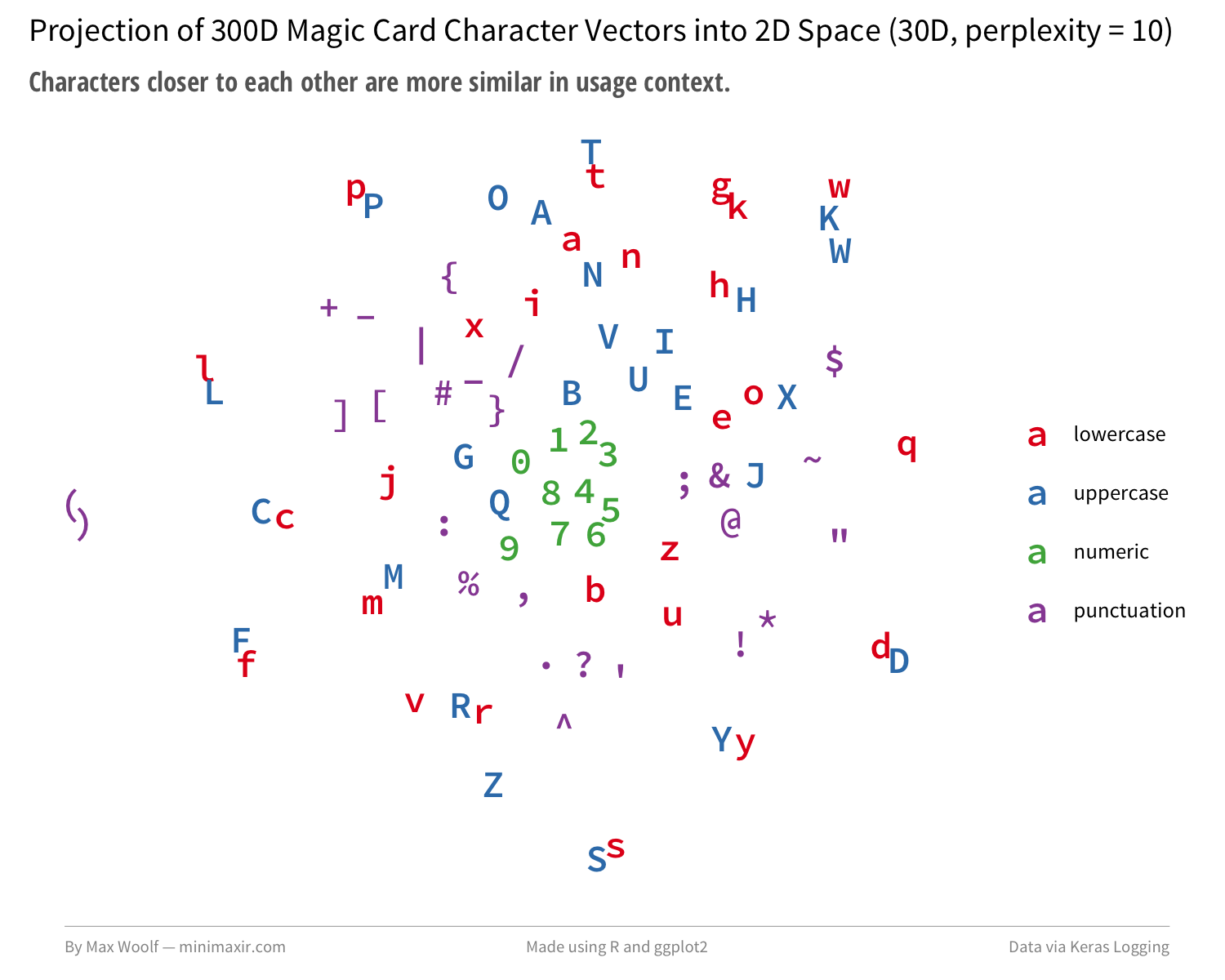
有更多成对的大写/小写字符,但有趣的是,在编码中添加的特殊字符并没有太多分组,或者机械大写字符,如W/U/B/R/G/C/T。
下一步
在建立模型之后,我做了更多的研究,看看其他人是否解决了power/toughness问题。因为这些句子只有40个字符,而且魔法卡的长度超过40个字符,所以很可能是模型的power/toughness超出了它的范围,而且它也无法了解它们的精确值。原来的解决方案是使用一种完全不同的编码方式,比如对Dragon Whelp:
1 | |5creature|4|6dragon|7|8&^^/&^^^|9flying\{RR}: @ gets +&^/+& until end of turn. if this ability has been activated four or more times this turn, sacrifice @ at the beginning of the next end step.|3{^^RRRR}|0N|1dragon whelp| |
在卡片的开始处产生了power/toughness。各部分用管子分隔,数字指定对应的部分。用卡值来代替数字,使用的是carets,它提供了更精确的数值量化。通过这种编码,每个字符在全局卡片上下文中都有一个单独的目的,并且它们的嵌入可能会生成更多的信息可视化。(但结果是,生成的卡片很难一目了然)。
次级编码突出了我的方法中使用预先训练的字符嵌入的潜在缺陷。必须在类似的数据集上使用经过训练的机器学习模型;例如,您不能在一个数据集上精确地执行Twitter情绪分析,因为Twitter上没有遵循美联社风格的指导原则。在我的例子中,常见的爬虫,是预先训练的嵌入的来源,遵循更自然的文本用法,并且不会与神奇的卡片编码中的非典型字符使用类似。
在使用预先训练的字符嵌入和改进魔术卡片生成方面,还有很多工作要做,但我相信有希望。使字符嵌入比我的脚本更好的方法是用硬方法和训练,然后手动,甚至可能在更高的维度,比如500D或1000D。同样,对于魔法模型构建,mtg-rnn指令回购使用大型LSTM堆放在LSTM连同120/200-character句子,这两个组合使训练非常缓慢(值得注意的是,这是第一个提交的建筑Keras文本生成的例子,并改为easily-trainable架构)。在一个变分自动编码器方法中也有希望,比如textvae。
这项工作可能非常昂贵,我正在考虑建立一个Patreon代替多余的风险资本来资助我的机器学习/深入学习任务。
至少,与这个示例一起工作使我能够充分地应用于Keras的实际工作,以及在我的工具箱中用于数据分析和可视化的另一个工具。Keras使深入学习的模型构建方面显得琐碎而不可怕。希望这篇文章能证明在标题中使用“深度学习”的时髦词是合理的。
值得一提的是,我实际上是在6个月前开始使用一种不同的、非深度学习的方法来处理自动文本生成的,但是遇到了障碍,放弃了这个项目。在Keras的工作中,我找到了一个解决这个问题的方法,并且在同一个具有相同输入结构的魔法数据集上,我在大约相同的时间内获得了一个0.03的模型损失,在20%的云计算成本中。稍后将进行更详细的讨论。





