几乎所有的机器学习算法都包括一些超参数。这些参数和常规参数不同,它们不是模型的一部分,不会在模型拟合中被自动调整,需要在额外的步骤中进行调整。常见的超参数有逻辑回归模型中的正则项lambda、支持向量机中的C项、基于树的算法中树的数量(如,随机森林、梯度提升机)。
一般常见的超参数优化方法主要有:
-
网格搜索
-
随机搜索
-
基于梯度的优化
-
贝叶斯优化
在这4中方法之中,我们尝试了网格搜索,随机搜索和贝叶斯优化。我们发现贝叶斯优化是最高效的,可以自动达到最优。
为什么贝叶斯优化比网格搜索和随机搜索更高效呢?
在寻找最优超参数值的时候,需要提前确定一些条件。首先,也是最重要的,任何算法都需要一个目标函数,目标是使得目标函数达到最大值;或者一个损失函数,目标是使得损失函数达到最小值。然后,需要确定搜索范围,一般通过上限和下限来确定。可能还有一些对于算法的参数,比如搜索的步长。
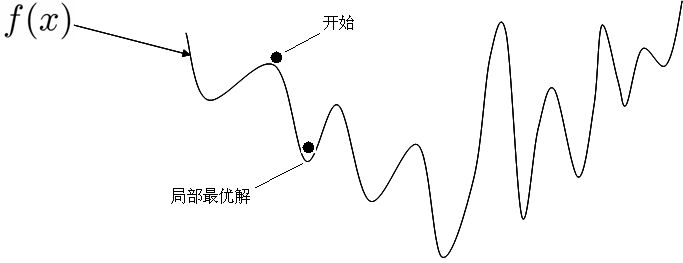
网格搜索可能是应用最广泛的超参数搜索算法了,因为它确实很简单。网格搜索通过查找搜索范围内的所有的点,来确定最优值。它返回目标函数的最大值或损失函数的最小值。给定较大的搜索范围,以及较小的步长,网格搜索是一定可以找到全局最大值或最小值的。但是,网格搜索存在一个比较大的问题是,它十分消耗计算资源,特别是,需要调优的超参数比较多的时候(例如,随机森林里有8个左右)。因此,当人们实际使用网格搜索来找到最佳超参数集的时候,一般会先使用较广的搜索范围,以及较大的步长,来找到全局最大值或者最小值可能的参数值。然后,不断缩小搜索范围和步长,来达到更精确的最值。尽管这样做可以降低所需的时间,但是由于目标参数一般是非凸的,如图1所示,所以人们常常就会错过了全局的最大值或最小值,因为他们在第一次测试的时候找到了一个局部的最值。
随机搜索的思想和网格搜索比较相似,只是不再测试上界和下界之间的所有值,只是在搜索范围中随机取样本点。它的理论依据是,如果随即样本点集足够大,那么也可以找到全局的最大或最小值,或它们的近似值。通过对搜索范围的随机取样,随机搜索一般会比网格搜索要快一些。但是和网格搜索的快速版(非自动版)相似,结果也是没法保证的。
贝叶斯优化寻找使全局达到最值的参数时,使用了和网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新的点时,会忽略前一个点的信息。而贝叶斯优化充分利用了这个信息。贝叶斯优化的工作方式是通过对目标函数形状的学习,找到使结果向全局最大值提升的参数。它学习目标函数形状的方法是,根据先验分布,假设一个搜集函数。在每一次使用新的采样点来测试目标函数时,它使用这个信息来更新目标函数的先验分布。然后,算法测试由后验分布给出的,全局最值最可能出现的位置的点。
对于贝叶斯优化,一个主要需要注意的地方,是一旦它找到了一个局部最大值或最小值,它会在这个区域不断采样,所以它很容易陷入局部最值。为了减轻这个问题,贝叶斯优化算法会在勘探和开采(exploration and exploitation)中找到一个平衡点。
勘探(exploration),就是在还未取样的区域获取采样点。开采(exploitation),就是根据后验分布,在最可能出现全局最值的区域进行采样。
何时贝叶斯优化无法返回最优值?
贝叶斯优化,尽管比网格搜索和随机搜索要好一些,但是它也不是魔法,所以有些东西还是要好好考虑一下。根据我们的经验,迭代次数(也就是选取采样点的数量),和搜索范围的大小的比值,十分重要。让我们假想一个极端的例子,来说明这一点。想象你要调整两个超参数,每个参数的范围是从1到1000.然后你把迭代指数设置成了2,算法几乎肯定会返回一个错误结果,因为他还没充分学习到目标函数的形状。
实现
下面主要基于python的bayes_opt模块对xgboost模型进行调参。
首先,加载所需要的模块
1
2
3
4
5
6
7
8
9
10
11
| from __future__ import print_function
import numpy as np
import pandas as pd
import gc
import warnings
from bayes_opt import BayesianOptimization
from sklearn.cross_validation import cross_val_score, StratifiedKFold, StratifiedShuffleSplit
from sklearn.metrics import log_loss, matthews_corrcoef, roc_auc_score
from sklearn.preprocessing import MinMaxScaler
import xgboost as xgb
import contextlib
|
定义一个capture stderr和stdout函数
1
2
3
4
5
6
7
8
9
10
11
12
13
| @contextlib.contextmanager
def capture():
import sys
from cStringIO import StringIO
olderr, oldout = sys.stderr, sys.stdout
try:
out = [StringIO(), StringIO()]
sys.stderr, sys.stdout = out
yield out
finally:
sys.stderr, sys.stdout = olderr, oldout
out[0] = out[0].getvalue().splitlines()
out[1] = out[1].getvalue().splitlines()
|
虽然scaleing对于xgboost而言没必要,但是可能其他模型需要使用到,比如线性模型,因此,这里定义一个scale函数
1
2
3
4
5
6
7
|
def scale_data(X, scaler=None):
if not scaler:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler.fit(X)
X = scaler.transform(X)
return X, scaler
|
使用kaggle比赛的数据案例进行测试,首先加载数据集。
1
2
3
4
5
6
7
8
9
10
11
12
13
| DATA_TRAIN_PATH = 'train.csv'
DATA_TEST_PATH = 'test.csv'
def load_data(path_train=DATA_TRAIN_PATH, path_test=DATA_TEST_PATH):
train_loader = pd.read_csv(path_train, dtype={'target': np.int8, 'id': np.int32})
train = train_loader.drop(['target', 'id'], axis=1)
train_labels = train_loader['target'].values
train_ids = train_loader['id'].values
print('\n Shape of raw train data:', train.shape)
test_loader = pd.read_csv(path_test, dtype={'id': np.int32})
test = test_loader.drop(['id'], axis=1)
test_ids = test_loader['id'].values
print(' Shape of raw test data:', test.shape)
return train, train_labels, test, train_ids, test_ids
|
接下来,定义一个用于参数搜索的交叉验证变量,需要注意的是cv函数里面的参数跟参数空间是一一对应的,下面,我们将学习率(‘eta’)参数设置为0.1,当然这个参数不是最优的,但是大的学习率会让搜索速度更快。而且你也可以在0.01~0.05之间进行测试,但是需要注意的是,这会增加训练时间因为我们需要更多的迭代次数来训练。对于交叉验证次数,10折交叉验证多多少少会比5折交叉验证提高微小的性能,但是很明显更加耗时。
xgboost的输出数据包含着很多有用的信息,后面我们将从这些数据中提取相关信息,并将每个cv的记录打印到日志文件中
虽然比赛中选择gini分数作为评估指标,但是下面我们选择AUC作为评估指标,因为AUC指标跟gini分数是直接相关的,当然也可以自定义评估指标令feval=gini。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| def XGB_CV(
max_depth,
gamma,
min_child_weight,
max_delta_step,
subsample,
colsample_bytree
):
global AUCbest
global ITERbest
paramt = {
'booster' : 'gbtree',
'max_depth' : int(max_depth),
'gamma' : gamma,
'eta' : 0.1,
'objective' : 'binary:logistic',
'nthread' : 8,
'silent' : True,
'eval_metric': 'auc',
'subsample' : max(min(subsample, 1), 0),
'colsample_bytree' : max(min(colsample_bytree, 1), 0),
'min_child_weight' : min_child_weight,
'max_delta_step' : int(max_delta_step),
'seed' : 1001
}
folds = 5
cv_score = 0
print("\n Search parameters (%d-fold validation):\n %s" % (folds, paramt), file=log_file )
log_file.flush()
xgbc = xgb.cv(
paramt,
dtrain,
num_boost_round = 20000,
stratified = True,
nfold = folds,
early_stopping_rounds = 100,
metrics = 'auc',
show_stdv = True
)
print('', file=log_file)
for line in result[1]:
print(line, file=log_file)
if str(line).find('cv-mean') != -1:
log_file.flush()
val_score = xgbc['test-auc-mean'].iloc[-1]
train_score = xgbc['train-auc-mean'].iloc[-1]
print(' Stopped after %d iterations with train-auc = %f val-auc = %f ( diff = %f ) train-gini = %f val-gini = %f' % ( len(xgbc), train_score, val_score, (train_score - val_score), (train_score*2-1),
(val_score*2-1)) )
if ( val_score > AUCbest ):
AUCbest = val_score
ITERbest = len(xgbc)
return (val_score*2) - 1
|
接下来,定义日志文件跟数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
log_file = open('Porto-AUC-5fold-XGB-run-01-v1-full.log', 'a')
AUCbest = -1.
ITERbest = 0
train, target, test, tr_ids, te_ids = load_data()
n_train = train.shape[0]
train_test = pd.concat((train, test)).reset_index(drop=True)
col_to_drop = train.columns[train.columns.str.endswith('_cat')]
col_to_dummify = train.columns[train.columns.str.endswith('_cat')].astype(str).tolist()
for col in col_to_dummify:
dummy = pd.get_dummies(train_test[col].astype('category'))
columns = dummy.columns.astype(str).tolist()
columns = [col + '_' + w for w in columns]
dummy.columns = columns
train_test = pd.concat((train_test, dummy), axis=1)
train_test.drop(col_to_dummify, axis=1, inplace=True)
train_test_scaled, scaler = scale_data(train_test)
train = train_test_scaled[:n_train, :]
test = train_test_scaled[n_train:, :]
print('\n Shape of processed train data:', train.shape)
print(' Shape of processed test data:', test.shape)
dtrain = xgb.DMatrix(train, label = target)
dtrain = xgb.DMatrix(X_train, label = y_train)
|
接下来,定义xgboost的BO,需要注意的这里的参数搜索应与cv函数中的变量一一对应
1
2
3
4
5
6
7
8
| XGB_BO = BayesianOptimization(XGB_CV, {
'max_depth': (2, 12),
'gamma': (0.001, 10.0),
'min_child_weight': (0, 20),
'max_delta_step': (0, 10),
'subsample': (0.4, 1.0),
'colsample_bytree' :(0.4, 1.0)
})
|
通常,init_points参数设置在10~20之间,而n_iter设置在25~50之间。
1
2
3
4
5
6
7
8
9
10
| print('-'*130)
print('-'*130, file=log_file)
log_file.flush()
with warnings.catch_warnings():
warnings.filterwarnings('ignore')
XGB_BO.maximize(init_points=2, n_iter=5, acq='ei', xi=0.0)
|
接下来,保存结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| print('-'*130)
print('Final Results')
print('Maximum XGBOOST value: %f' % XGB_BO.res['max']['max_val'])
print('Best XGBOOST parameters: ', XGB_BO.res['max']['max_params'])
print('-'*130, file=log_file)
print('Final Result:', file=log_file)
print('Maximum XGBOOST value: %f' % XGB_BO.res['max']['max_val'], file=log_file)
print('Best XGBOOST parameters: ', XGB_BO.res['max']['max_params'], file=log_file)
log_file.flush()
log_file.close()
history_df = pd.DataFrame(XGB_BO.res['all']['params'])
history_df2 = pd.DataFrame(XGB_BO.res['all']['values'])
history_df = pd.concat((history_df, history_df2), axis=1)
history_df.rename(columns = { 0 : 'gini'}, inplace=True)
history_df['AUC'] = ( history_df['gini'] + 1 ) / 2
history_df.to_csv('Porto-AUC-5fold-XGB-run-01-v1-grid.csv')
|