债务违约预测是Kaggle中的一个比赛,本文将介绍取得第一名成绩的方法,本次比赛的目标包括两个方面。其一是建立一个模型,债务人可以通过它来更好地进行财务方面的决策。其二是债权人可以预测这个债务人何时会陷入到财务方面的困境。最终目的是,通过预测未来两年内债务违约的概率,来改进现有的信用评分制度。这是一个极度复杂和困难的Kaggle挑战,因为银行和各种借贷机构一直都在不断地寻找和优化信用评分的算法。这个模型是银行用来判定是否准许某一笔贷款的。根据这个模型提供的信息,银行可以更好地作出决策,借贷者也可以更好地进行财务方面的规划,以免将来陷入债务危机。
本次挑战允许团队使用集成模型和算法,如XGBoost, Gradient Boosting, 随机森林(Random Forest), 限制玻尔兹曼机(Restricted Boltzman Machine Neural Networks), Adaboost。以及使用先进的堆叠技术(stacking)和投票分类器来准确地预测违约概率。
我们的测量和排名严格使用ROC曲线的AUC值。我们遵照了Agile过程,来确保我们分块、并行地完成关键的任务。我们很快地失败,又很快地在此基础上迭代,以此来确保最高效的工作和产出。我们使用复杂贝叶斯优化算法,获取最好的超参数集,大幅减少了测试和交叉验证的时间。这为我们提升排名、获得AUC最高分提供了很大的帮助。
通过我们对工具的利用、团队的协作、以及一个使我们产出最大化的流程,我们不仅跻身排名榜的前列,还打破了第一名的成绩,获得了这次挑战的冠军。
SWOT分析法
SWOT分析法让我们可以让我们思路更清晰,专注于利用我们最大的优势(Strengths),了解我们的弱点(Weaknesses),利用现有的机会(Opportunities),警惕潜在的威胁(Threats)。
SWOT方法使我们可以在正确的方向前进,避开很多令人头疼的事儿。
优势(Strengths):利用我们已有的优势
- 利用堆叠技术和Agile过程的经验
- 协作团队的经验和技能可以相互补充
- 吸取之前的Kaggle挑战的经验和教训
- 使用Agile过程处理并行工作的经验
弱势(weaknesses):我们需要提升的领域
- 时间有限,限制了探索的深度和广度
- 对新工具和模型的不熟悉,大大降低了我们的战斗力
- 边做边学,拖慢了整个进程
- 对于所使用的新技术,相关的资源十分稀少
机会(opportunities):可以利用的机会,及实践得到的经验
- 了解如何制定策略,调整模型、算法和参数,来达到对违约几率的最佳预测
- 在使用贝叶斯优化算法时,获得实时的经验
- 尝试使用深度学习(Theano/Keras)来进行违约预测
威胁(threats):我们需要减轻和控制的危机
- 数据集比较小,这对模型的泛化有较大的挑战。这影响了模型的构造,最终影响了预测的精度。
- 对AUC的公差严格到了小数点后10,000位
- 前5%的目标分数太高了-简直不可行
Agile过程
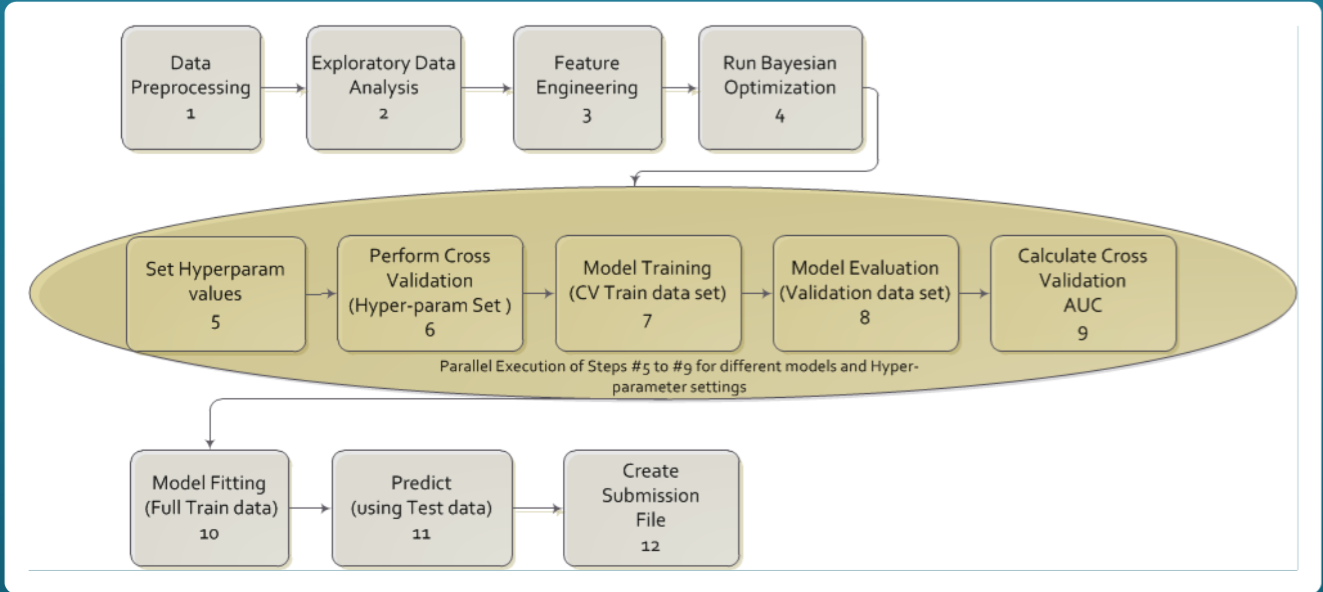
我们使用‘Agile过程’作为本项目的流程,这是由Bernard发明的。它特别为了机器学习优化过,因为他需要整合很大一块内容,包括数据是如何被处理的,建模、测试的,以及很多更传统的开发生命周期。
Agile过程利用了‘分块’的概念,以一种快速的方式来完成工作任务。它整合了很多并行的任务,很快地失败,又很快地迭代。它发挥了强大的作用,使产出最大化。这是我们在短短两星期内获得第一名的主要因素之一。
Agile过程是什么?
敏捷过程是一个标准的全行业的传统软件开发和工程的生命周期。它基于迭代开发,需要通过发展自组织、跨职能的团队之间的协作来进行。本工程使用的Agile是一个改进的形式,它是专门为机器学习设计的。它和传统流程的组成部分比较相似,大多数任务是并行地而不是顺序的。流程的组成部分包括数据预处理(包括缺失值插补),探索性数据分析(如单变量分布,二维分布,相关分析),特征工程(如增加特征,删除特征,PCA),算法选择(如有监督),超参数优化,模型拟合,模型评估,模型再造,交叉验证,预测,以及最后的提交。不同于传统机器学习的顺序流程,一次只能进行一个模型的选择和调整,并且在缺失值插补的方法没有确定之前无法进行模型的拟合。Agile过程充分利用缺失值插补,特征工程和模型拟合的并行执行,使多个人在这个项目上协作工作。
为何使用Agile过程?
在我们的团队领导伯纳德的指导下,我们脑子里从一开始就有整个的Agile过程。由于大部分流程并行完成,并且我们每个人都分配了非常具体的任务,没有人等着别人的结果来完成自己的工作。我们可以快速评估模型和战术方法,并能够快速失败和迭代,快速搞清楚什么可行,什么不可行。转化为成果方面,就是到了第一周的周中,我们已经在排行榜上排名前100。在第一周结束时,我们到达了第2名,这给我们留下了整整一个星期去挑战第一名。
试探性数据分析
从下面的缺失值图像可以看出,变量‘负债率’和‘家属数’分别有20%和3%左右的数据缺失。

我们尝试了不同的缺失值估算方法,包括KNN,平均值,随机数和中位数。然而,我们发现,不去补充缺失值,模型反而会有更好的表现。
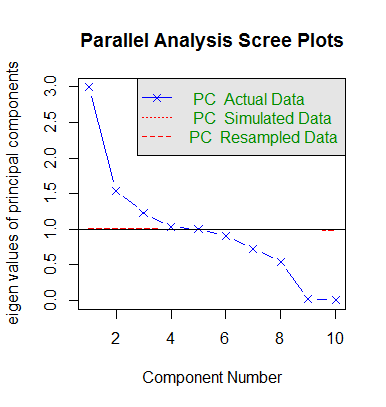
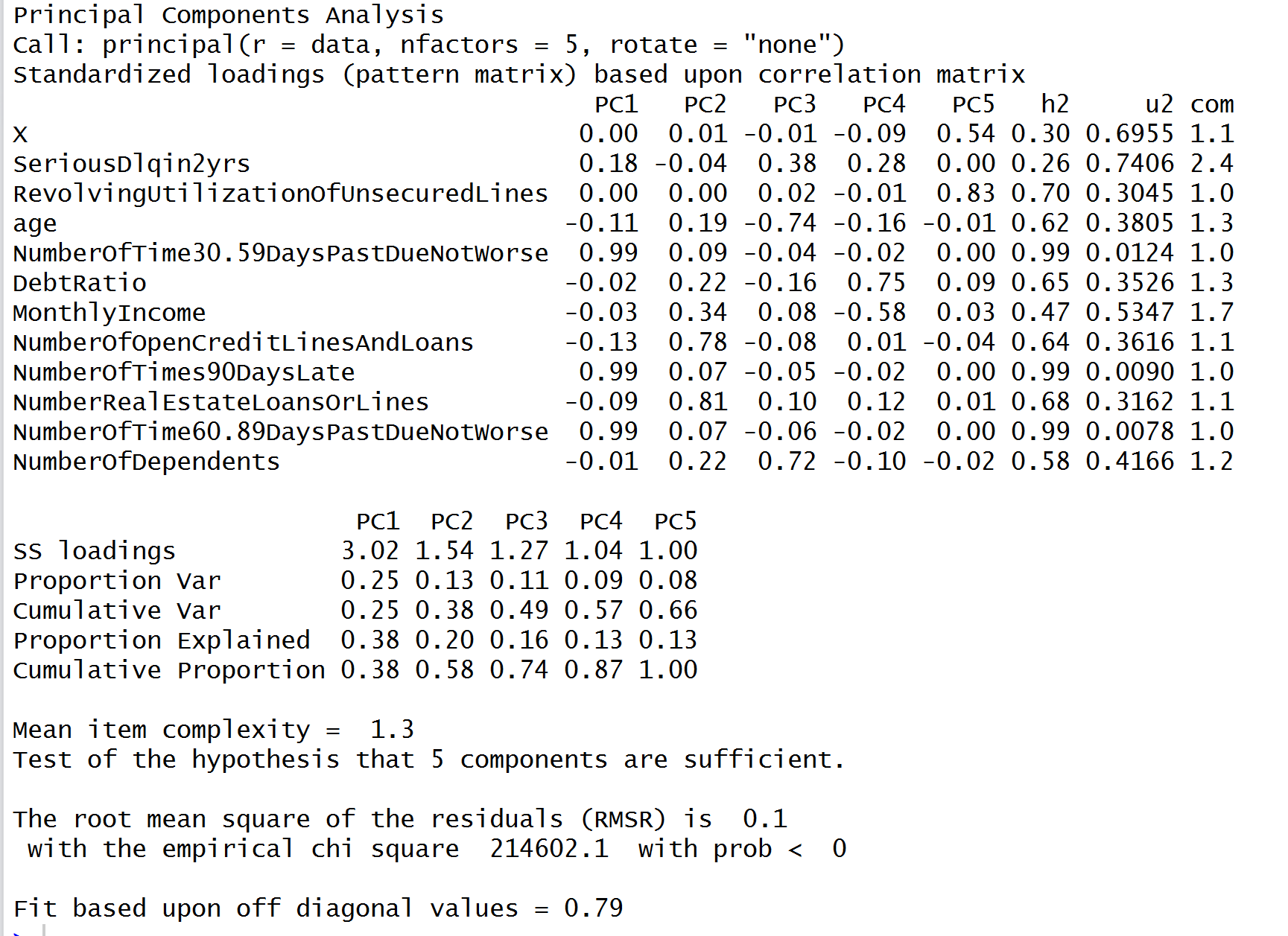
我们也做了PCA。结果表明,选择5个主成分只能解释总方差的66%。由于只有10个特征,PCA可能不适合这个项目。
数据集的一个有趣的特性是,除了“年龄”,几乎每列有一些异常值。例如,列‘逾期30-59天’,‘逾期60-89天’和‘逾期90天’都有大约0.2%的异常值,异常值为98或96。这些数字实际上是在调查中输入的,表示用户不愿意透露这些信息。这些会对单变量分布有很大的影响。还有变量‘循环贷款无抵押额度(RevolvingUtilizationOfUnsecuredLines)’,是信用卡额度和除分期付款,如购车贷款的个人限制之和除以总贷款余额。因此,这个变量的正常范围是0与1之间,而它有大于5000的异常值。因此,我们必须处理这个问题。
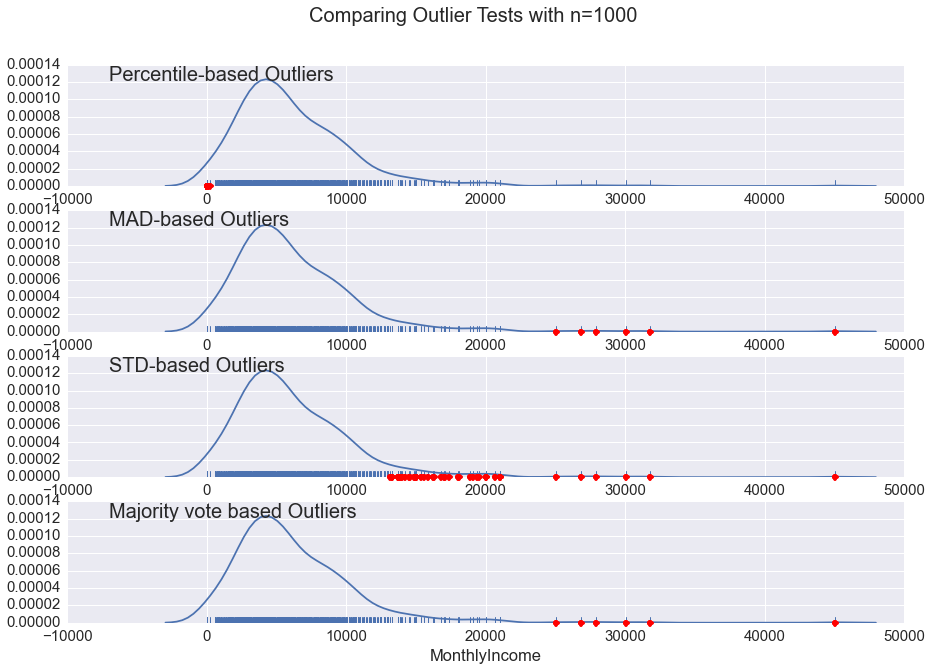
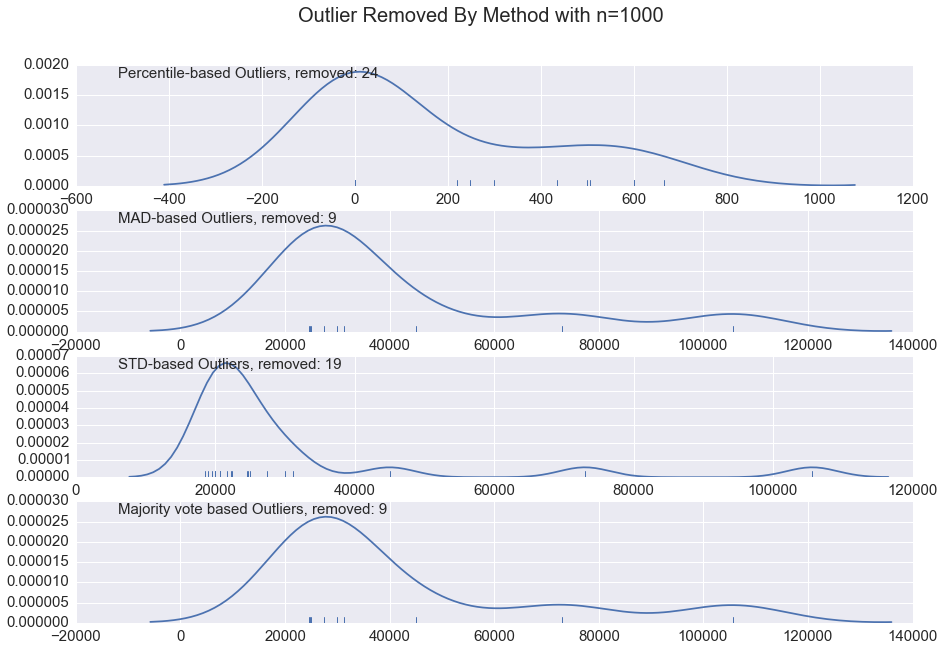
对于每一列,我们检测基于第95百分位数的异常值,基于中位数的异常值和基于标准偏差的异常值,并用投票来决定最终结果。如果三种方法中,如果有两种方法都认为某一个点是一个异常值,那么我们就确定这个点是一个异常值。然后,我们将异常值替换为该列的中值或最不异常的异常值。至于使用哪种替换,取决于具体的列。
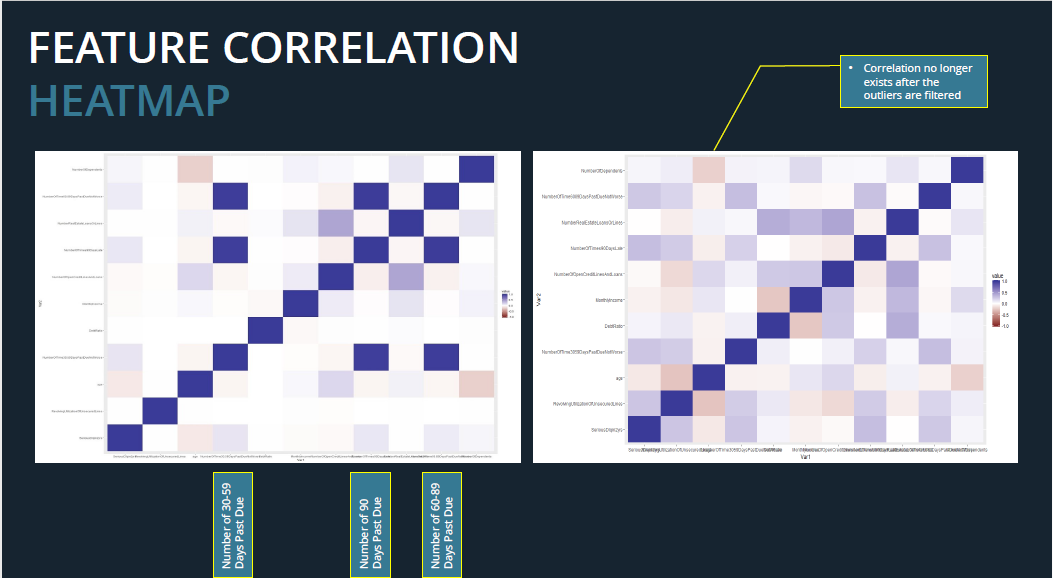
过滤掉异常值改变了原有的数据结构。在此之前,这三个异常变量是高度相关的。在滤值之后,相关性消失了。如下面的图片所示。
特征工程
下图是特征重要性图示,从图中可以看出,‘循环贷款无抵押额度(RevolvingUtilizationOfUnsecuredLines)’,‘负债率’和‘月收入’是最重要的三个变量。
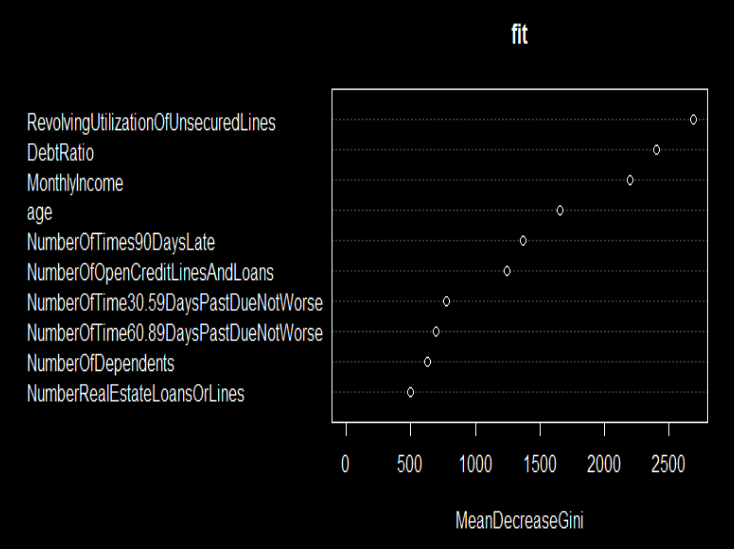
这个信息对于特征工程来说是十分重要的。下面是特征工程的工作流程。
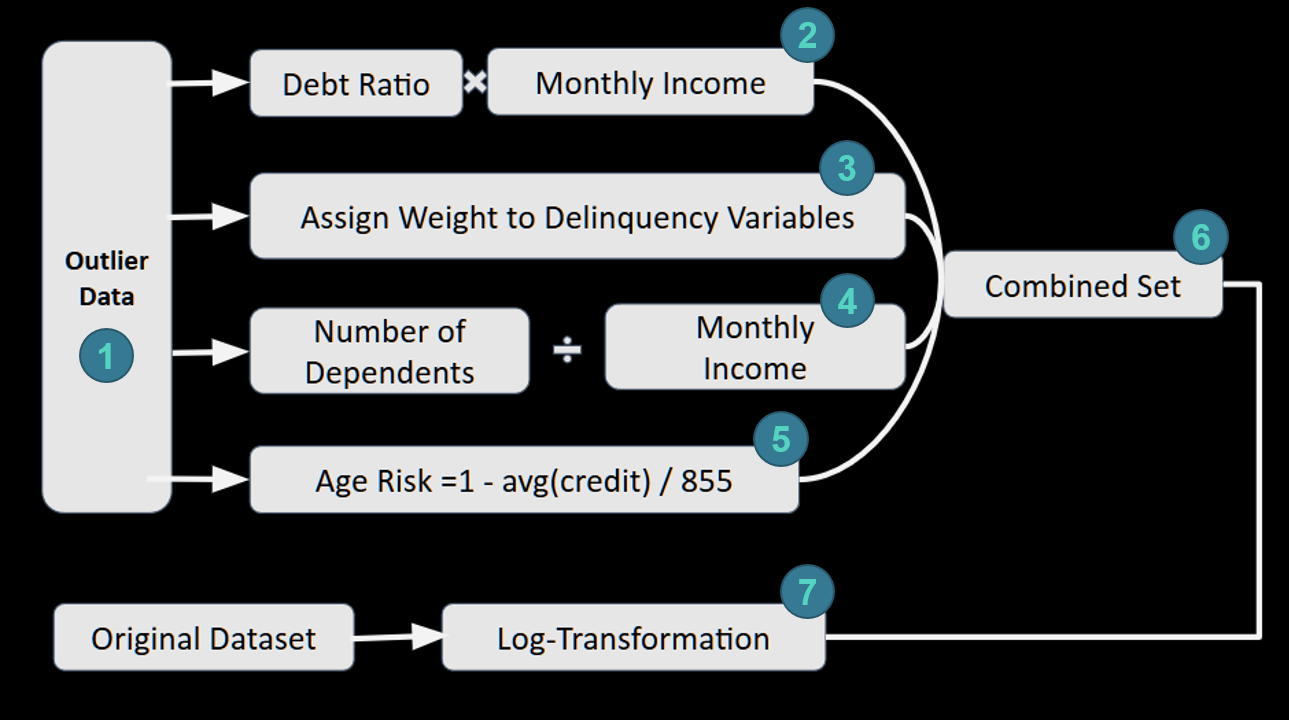
我们尝试了几种不同的方法。我们把一些列组合在了一起,生成了一个新的列,并且删除了原有的列。例如,负债率乘以月收入得到月负债。我们对违约变量分配了权重。对于每一个违约变量,我们做了一个逻辑回归,然后使用得到的R^2除以三个R^2的和,作为它的权重。最后,我们构造了7个训练集和7个测试集。这些数据集使朴素贝叶斯和逻辑回归的AUC值从0.7左右提升到了0.85左右。然而,对基于树的模型,这些数据集并没什么帮助。
模型实施战略
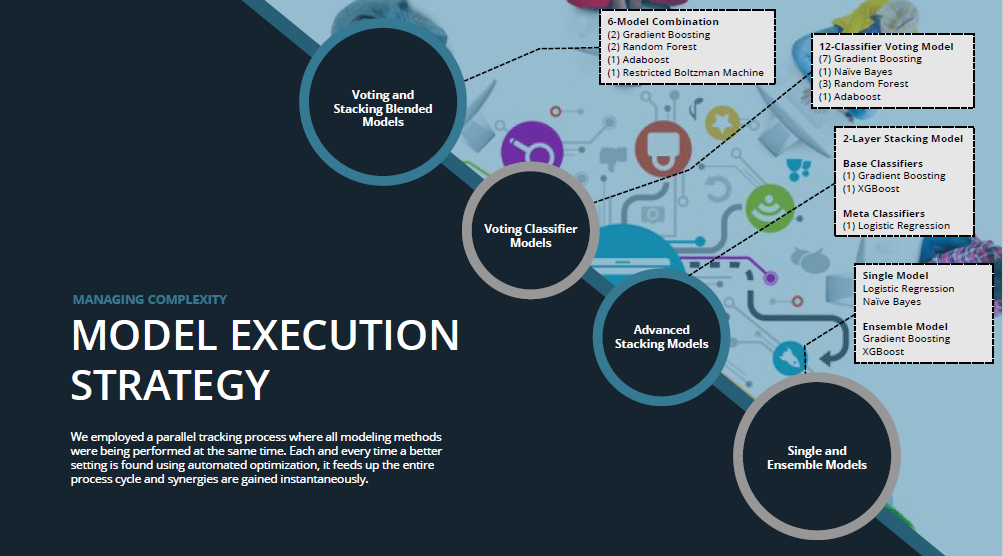
我们为了本次挑战,构造了4个模型,并评估了他们的准确率。团队实施了一个并行流程,所有的模型同步构造。在自动优化过程中,每发现一个更优的参数集,这些参数会用于整个流程循环,即时地进行协同工作。
-
** 简单和集成模型:**
作为构造模型的第一步,我们训练了逻辑回归和朴素贝叶斯模型,并且这两个模型的精度(曲线下面积,AUC值)都是0.7左右。上面提到的这两个模型提供了很好的基线,可以用于比较更加复杂的模型,比如堆叠、投票以及混合模型的表现。梯度提升和随机森林模型作为集成模型的一部分它们的AUC评分在文档中。 -
优化的堆叠模型:
堆叠模型将贝叶斯分类器以非线性的方式组合在一起。这个通过在元级别(meta-level)上的训练集上学习,来进行组合的过程,称作元学习(meta learner),它把独立运算的基础分类器集成为一个高级的分类器,这称作元分类器(meta classifier)。这个2层的堆叠模型,使用梯度提升和XGBoost作为基础分类器。它们的分类结果被输入一个逻辑回归模型,这个逻辑回归模型就是元分类器。堆叠模型使得分达到了0.8685左右,进入了Kaggle排行榜前30名。 -
投票分类模型:
投票模型根据获得最多票数的类别对没有标签的对象进行分类。我们使用加权平均算法,对每个分类器输出的可能性值进行计算,得出最终预测的结果。尽管团队开始时只有两个分类器,最终的结果有12个分类器,包括7个梯度提升的,1个朴素贝叶斯的,3个随机森林的和一个AdaBoost分类器。如果测试结果表明会对交叉验证得分的提高有贡献的话,就会增加分类器的数量。投票模型把AUC的得分提高到了0.869左右,使我们到达了排行榜的第8名。 -
投票和堆叠的混合模型:
最终使我们超越现有第一名的模型,就是投票和堆叠的混合模型。这个模型包括2个梯度提升的,2个随机森林的,1个AdaBoost分类器,1个严格玻尔兹曼机(estricted Boltzman Machine,RBM)。并且引入了神经网络算法。这个模型将得分提到了0.869574,使我们Eigenauts队成为了排行榜上第一名。
贝叶斯优化
贝叶斯优化被用来做什么?
几乎所有的机器学习算法都包括一些超参数,也叫做调整参数。这些参数和常规参数不同,它们不是模型的一部分,不会在模型拟合中被自动调整。它们是在另外的步骤中被调整的。一些超参数的例子,包括在岭回归和lasso回归中的正则项lambda、支持向量机中的C项、基于树的算法中树的数量(如,随机森林、梯度提升机)。
共有4中超参数优化方法:1、网格搜索 2、随机搜索 3、基于梯度的优化 4、贝叶斯优化。在这4中方法之中,我们尝试了网格搜索,随机搜索和贝叶斯优化。我们发现贝叶斯优化是最高效的,可以自动达到最优。
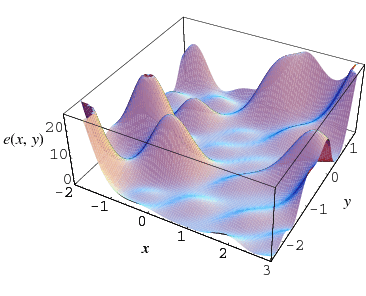
为什么贝叶斯优化比网格搜索和随机搜索更高效呢?
在寻找最优超参数值的时候,需要提前确定一些数据。首先,也是最重要的,任何算法都需要一个目标函数,来找它的最大值。或者一个损失函数,来找它的最小值。然后,需要确定搜索范围,一般通过上限和下限来确定。可能还有一些对于算法的参数,比如搜索的步长。
网格搜索可能是应用最广泛的超参数搜索算法了,因为它确实很简单。网格搜索通过查找搜索范围内的所有的点,来确定最优值。它返回目标函数的最大值或损失函数的最小值。给出较大的搜索范围,以及较小的步长,网格搜索是一定可以找到全局最大值或最小值的。但是,网格搜索一个比较大的问题是,它十分消耗计算资源,特别是,需要调优的超参数比较多的时候(例如,随机森林里有8个左右)。因此,当人们实际使用网格搜索来找到最佳超参数集的时候,一般会先使用较广的搜索范围,以及较大的步长,来找到全局最大值或者最小值可能的位置。然后,人们会缩小搜索范围和步长,来达到更精确的最值。尽管这样做可以降低所需的时间,但是由于目标参数一般是非凸的,如图1所示,所以人们常常就会错过了全局的最大值或最小值,因为他们在第一次测试的时候找到了一个局部的最值。
随机搜索的思想和网格搜索比较相似,只是不再测试上界和下界之间的所有值,只是在搜索范围中随机取样本点。它的理论依据是,如果随即样本点集足够大,那么也可以找到全局的最大或最小值,或它们的近似值。通过对搜索范围的随机取样,随机搜索一般会比网格搜索要快一些。但是和网格搜索的快速版(非自动版)相似,结果也是没法保证的。
贝叶斯优化寻找使全局达到最值的参数时,使用了和网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新的点时,会忽略前一个点的信息。而贝叶斯优化充分利用了这个信息。贝叶斯优化的工作方式是通过对目标函数形状的学习,找到使结果向全局最大值提升的参数。它学习目标函数形状的方法是,根据先验分布,假设一个搜集函数。在每一次使用新的采样点来测试目标函数时,它使用这个信息来更新目标函数的先验分布。然后,算法测试由后验分布给出的,全局最值最可能出现的位置的点。
对于贝叶斯优化,一个主要需要注意的地方,是一旦它找到了一个局部最大值或最小值,它会在这个区域不断采样,所以它很容易陷入局部最值。为了减轻这个问题,贝叶斯优化算法会在勘探和开采(exploration and exploitation)中找到一个平衡点。
勘探(exploration),就是在还未取样的区域获取采样点。开采(exploitation),就是根据后验分布,在最可能出现全局最值的区域进行采样。
我们用于进行贝叶斯优化的包是一个Python包,叫做“bayes_opt”。下面的视频(http://blog.nycdatascience.com/wp-content/uploads/2016/09/bayes_opt_visualisation.mp4)显示了“bayes_opt”包是如何保证勘探和开采的平衡的。
何时贝叶斯优化无法返回最优值?
贝叶斯优化,尽管比网格搜索和随机搜索要好一些,但是它也不是魔法,所以有些东西还是要好好考虑一下。根据我们的经验,迭代次数(也就是选取采样点的数量),和搜索范围的大小的比值,十分重要。让我们假想一个极端的例子,来说明这一点。想象你要调整两个超参数,每个参数的范围是从1到1000.然后你把迭代指数设置成了2,算法几乎肯定会返回一个错误结果,因为他还没充分学习到目标函数的形状。
登顶之路

ROC/AUC曲线
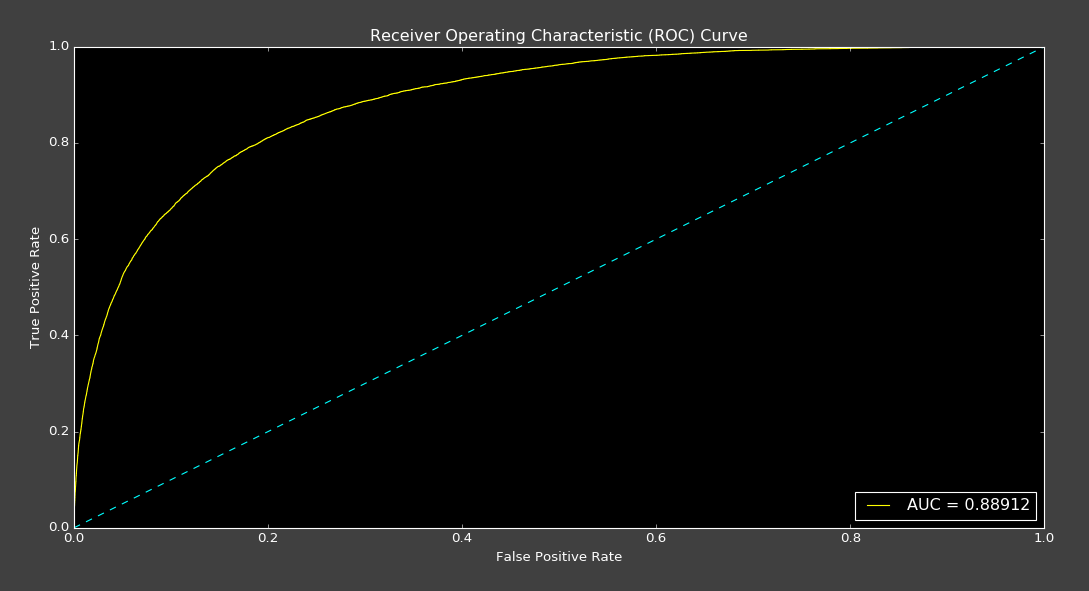
画出接受者操作特性曲线(ROC)可以看出预测违约或不违约的二分类器的表现。这个图像是最后的混合模型,它在Kaggle榜单上得到了第一名。在ROC曲线中,真正率(或灵敏度)是对于参数不同切分点的假正率(100-灵敏度)的函数。
ROC曲线的曲线下面积(AUC)是对于一个参数分割两组数据的效果的度量,在这里是违约或不违约。根据这张图可以看出,我们最好的模型,曲线下面积大约是0.89。这表示,在训练集中随机抽取一个标签为1(可能违约)的数据,他的得分比从训练集中抽取的标签为0(不太可能违约)的数据高的概率为89%。
结果和发现
下面使我们基于特征工程和预测模型在用户债务违约数据的表现,得到的结果和发现。
- 模型在不进行缺失值查补的情况下,表现好像更好一点。
- 相比于简单的集成模型,堆叠和投票,以及两者的结合,一般会有更高的预测能力。
- 对于简单模型(朴素贝叶斯和逻辑回归),特征工程可以把AUC的分数中0.7左右提到0.85左右。但是对于基于树的方法,这并没什么用。
- 当我们向着Kaggle榜的前2%接近的时候,对于AUC,每提升0.0001,会变得越来越难。
得到的经验以及一些见解
这个项目让团队学习到了很多关于机器学习和预测模型的宝贵的经验。它们使我们在这样高度竞争的数据科学竞赛中拿到了第一的好成绩:
- 超参数调整是十分耗时的,最好把它进行团队分工,并行工作。
- 交叉验证十分关键,在测试不同数据集对模型准确度的影响上话时间是很值当的。
- 模型的调整应该在更高精度上进行,因为数据集比较小。(不论是特征的数量还是数据的条目)
- 遵照Agile并行进程,它被证明是一个使成功最大化的因素。
后继的工作
当我们考虑还可以做什么的时候,一些事情来到了我们的脑海。这些任务可以看作是将来提高的一个愿景。
- 使用Theano / Keras来进行深度学习模型的调整,并且比较它和堆叠、投票算法的准确度和表现。
- 尝试增加新的特征多项式,以及转化过的特征,并衡量预测的精度。
结论
第一名的小伙伴在这次机器学习挑战中达到了目标,可以应用多种模型、算法、以及策略,来达到相对较好的结果。他们最终上榜的得分是 0.869574,在本次Kaggle竞赛925个竞争者中排名第一。这使小伙伴们很有成就感,因为我们只有两个星期来进行准备,提交挑战的结果。