语言模型正变的越来越大,PaLM有540B的参数量,OPT、GPT-3和BLOOM则大约有176B的参数量,而且我们正朝着更大的模型发展。下图是近些年语言模型的尺寸。

这些模型很难在常用设备上运行。例如,仅仅推理BLOOM-176B就需要8张A00 GPUs(每张80G显存,价格约15k美元)。而为了微调BLOOM-176B则需要72张GPU。PaLM则需要更多的资源。
这些巨型模型需要太多GPUs才能运行,因此需要寻找方法来减少资源需求并保证模型的性能。已经有各种技术用来减小模型尺寸,例如量化、蒸馏等。
在完成BLOOM-176B训练后,HuggingFace和BigScience逐步探索在少量GPU上运行大模型的方法。最终,设计出了Int8量化方法,该方法在不降低大模型性能的情况下,将显存占用降低了1至2倍,并且集成到了Transformers模块中。具体关于LLM.int8内容可参考余下论文:
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
常用类型
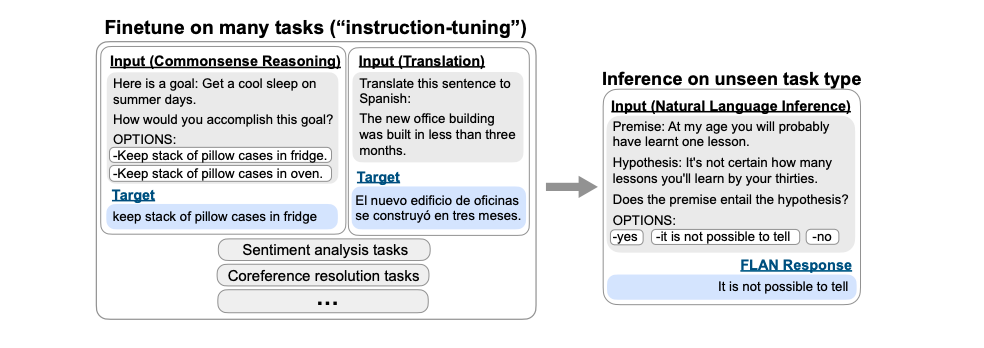
浮点数在机器学习中也被称为"精度"。模型大小是有参数量及参数精度决定的,通常是float32、float16和bfloat16。
我们开始于不同浮点数的基本理解,在机器学习的背景下也被称为"精度"。模型的大小由其参数数量和精度决定,通常是float32、float16和bfloat16。下图:
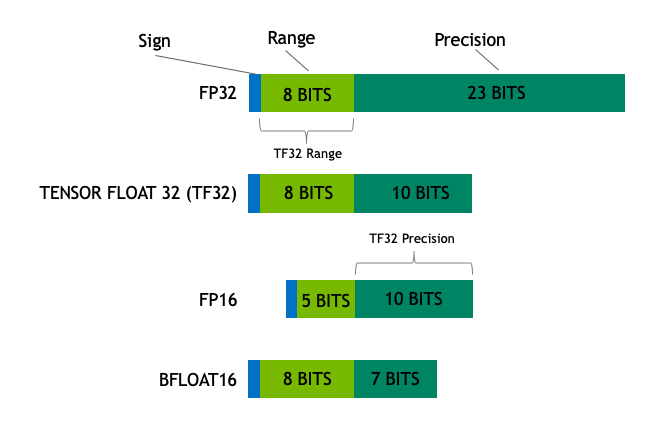
Float32(FP32)是标准的IEEE 32-bit浮点数表示,使用这种类型可以表示范围广泛的浮点数。在FP32中,8bits被用于"指数",23bits被用于"尾数", 1 bit则用于符号位。大多数的硬件都支持FP32操作和指令。
在Float16(FP16)数据类型中,5 bits被用作"指数",10 bits用于"尾数"。这使得FP16数的表示范围明显小于FP32,导致有上溢和下溢的风险。例如,若你做 ,最终得到100k。这在FP16中是不可能的,因为其最大表示为64K。因此你会得到NaN的结果,若像神经网络那样顺序执行,所有先前的工作都会被破坏。通常,loss缩放能够一定程度上克服这个问题,但并不总是有用。
因此,创建了一种新格式bfloat15(BF16)来避免这种问题。在BF16中,8bits被用于表示"指数", 7bits被用于表示"尾数"。这意味着BF16能够保留和FP32相同的动态范围,但是损失了3bits的精度。BF16可以表示巨大的数,但是精度上比FP16差。
在Ampere架构中,NVIDIA也引入了TensorFloat-32(TF32)精度格式,其仅使用19 bits就合并了BF16的动态范围和FP16的精度。其目前仅在内部某些操作中使用。
在机器学习的术语中FP32被称为全精度(4 bytes),BF16和FP16则称为半精度(2 bytes)。int8(INT8)数据类型则是由8 bits表示的数,其能够存储个不同的值([0,255]或者[-128, 127])
理想情况下,训练和推理应该在FP32上进行,但是其比FP16/BF16慢两倍。因此,采用一种混合精度的方法,模型权重仍然是FP32,前向和后向传播则使用FP16/BF16,从而加快训练速度。P16/BF16被用来更新FP32权重。
在训练过程中,模型权重以FP32存储,但在推理过程中,半精度权重能够保证与FP32权重对应的类似结果–因为只有模型在进行多个梯度更新时才需要对模型的精确参考。这意味着我们可以使用半精度权重降低一半的GPU大小来完成同样的结果。
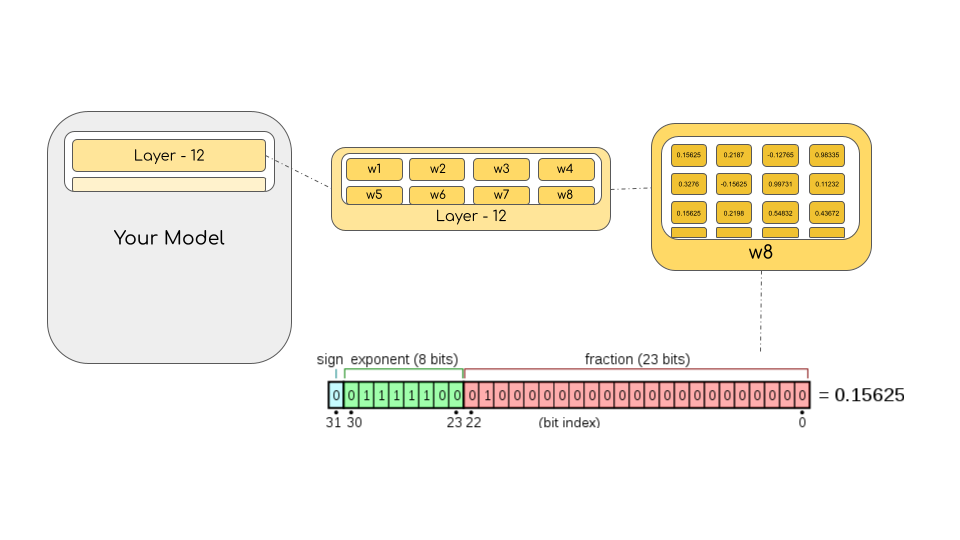
可以通过参数量乘以浮点数精度的大小来计算模型所占用的bytes量。例如,若模型使用bfloat16版本的BLOOM-176B模型,那么模型大小为!这个量级对于适配少量GPU来说相当有挑战。
但是我们是否可以使用不同的数据类型以更少的存储空间来保存这些权重?一种称为量化的方法被广泛的应用于Deep Learning。
模型量化
通过实验发现,在推理中使用2 bytes的BF16/FP16精度能够几乎达到4 bytes的FP32精度相同的效果,而且模型尺寸可以减少一半。若能够进一步削减那就太棒了,但是在更低的精度上推理质量开始急剧下降。为了解决这个问题,我们引入了8 bits量化。该方法使用四分之一的精度,这样仅需要1/4的模型尺寸!但是,其不是通过丢掉另外一半bits来实现的。
量化基本上是从一种数据类型"舍入"为另一种数据类型来完成的。例如,若一个数量类型范围0…9,另一个范围则是0…4。那么第一个数据类型中的"4"将会被舍入为第二种数据类型中的"2"。然而,若第一种数据类型中的"3",其会位于第二种数据类型的1和2之间,然后通常会被舍入为"2"。也就是说第一种数据类型中的"4"和"3"都会对应第二种数据类型中的"2"。这表明量化是可能带来信息丢失的噪音过程,一种有损压缩。
有两种常见的8-bit量化技术:zero-point量化和absolute maximum(absmax)量化。zero-point量化和absmax量化会将浮点数值映射至更加紧凑的int8(1 byte)值。这些方法首先会将输入按照量化常数进行缩放,从而实现规范化。
举例来说,在zero-point量化中,若范围是 -1.0…1.0, 并希望量化至范围 -127…127 。那么应该按照因子127进行缩放,然后四舍五入至8-bit精度。为了还原原始值,需要将int8的值除以量化因子127。例如,0.3被缩放为
,然后四舍五入为38。若要恢复,则38/127=0.2992。在这个例子中量化误差为0.008。随着这些微小的误差在模型各个层中传播,会逐步积累和增长并导致性能下降。

再来看看absmax量化的细节。为了在absmax量化中完成fp16和int8的映射,需要先除以张量中的绝对最大值(令整个张量介于-1至1之间),然后在乘以目标数据类型的总范围。
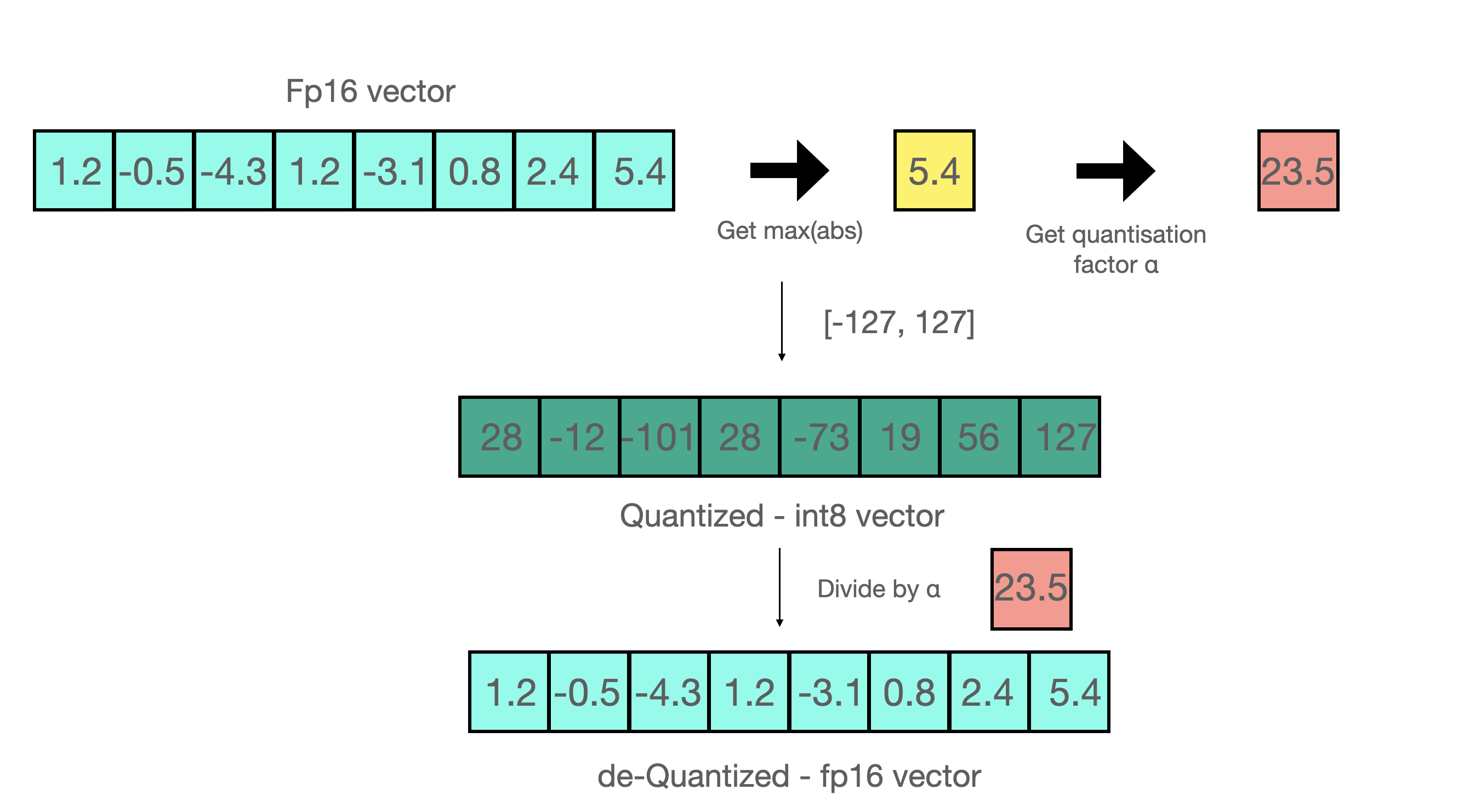
例如,在一个向量上应用absmax量化,该向量为,从向量中选择最大值,即5.4。而int8的范围为[-127,127],所以量化过程为:
即整个向量乘以缩放因子23.5。最终得到的量化后向量为。
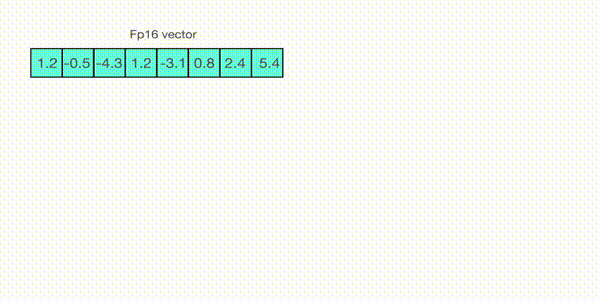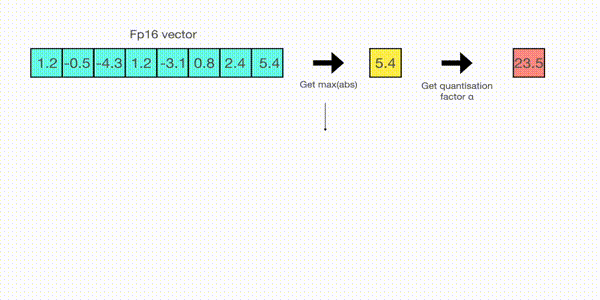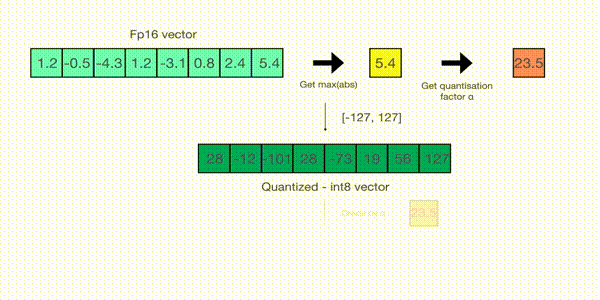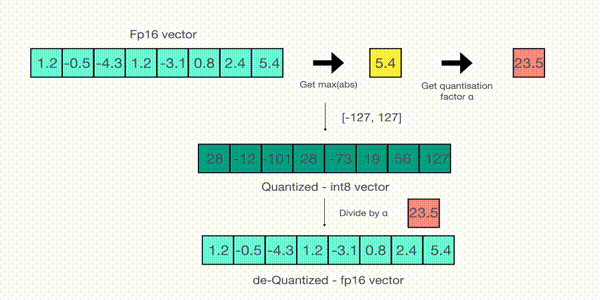
为了还原原始值,可以使用全精度的int8数除以量化因子23.5。但是由于四舍五入的原因,会丢失一些精度。
对于一个无符号的int8,我们将减去最小值,然后按绝对最大值进行缩放。这接近于零点量化的做法。它类似于最小-最大缩放,但后者保持了数值缩放的方式,使数值 "0 "总是由一个整数表示,没有任何量化误差。
这些技巧能够以多种方式组合。例如,当涉及矩阵乘法时,ow-wise或者vector-wise量化可以使得结果更加准确。以矩阵乘法 为例,相对于使用每个张量的绝对最大值来规范张量,vector-vise量化则会寻找矩阵A每行的绝对最大值和矩阵B每列的绝对最大值。然后通过除以这些绝对最大值向量来规范化矩阵A和B。然后执行 来得到C。为了最终返回FP16精度的值,通过计算A和B绝对最大值向量的外积来反规范化。
这些技术虽然能够量化模型,但是在较大模型上会带来性能下降。Hugging Face Transformers和Accelerate库集成了一种称为LLM.int8()的8-bit量化算法,能够在176B参数量模型上使用且不降低模型效果。
int8
理解Transformer中与规模相关的涌现特性对于理解为什么传统量化方式在大模型中失败至关重要。性能的下降是由异常特征值导致的,会在后面解释这一情况。
LLM.int8()算法本质上可以由三个步骤来完成矩阵乘法:
- 对输入的hidden states逐列的提取异常值(即大于某个阈值的值);
- 分别对FP16中的异常值和INT8中的非异常值执行矩阵乘法;
- 对非异常的结果进行反量化,并将两者结果合并来获得最终的FP16结果;
三个步骤如下图所示:

异常值特征
在整个分布之外的值,称为异常值。异常值检测被广泛使用,而拥有特征分布的先验知识有助于异常值检测任务。
具体来说,我们观察到经典的量化算法在超过6B参数量的transformer模型上失效了。虽然在较小的模型上也能观测到较大的异常值特征。但是,我们观察到一个参数量的阈值,transformer中的异常值会系统性的出现在每个层中。
由于8-bit精度的局限性,因此仅使用几个特别大的值来量化向量将导致非常差的结果。此外,transformer架构的内在特征就是将所有的元素连接在一起,这将导致错误跨越多层传播并被加剧。因此,开发出了混合精度分解来实现这种极端异常值的量化。
MatMul内部
一旦得到hidden state,使用自定义阈值来抽取异常值并分解矩阵为上述两部分。我们发现使用6作为阈值进行抽取可以完整的恢复推理性能。异常值部分以fp16实现,所以是经典的矩阵乘法;而8-bit则是通过vector-wise量化将模型权重和hidden state量化至8-bit的精度。即hidden-state使用row-wise量化,模型权重使用column-wise量化。经过这个步骤后,再将结果反量化并以半精度返回。
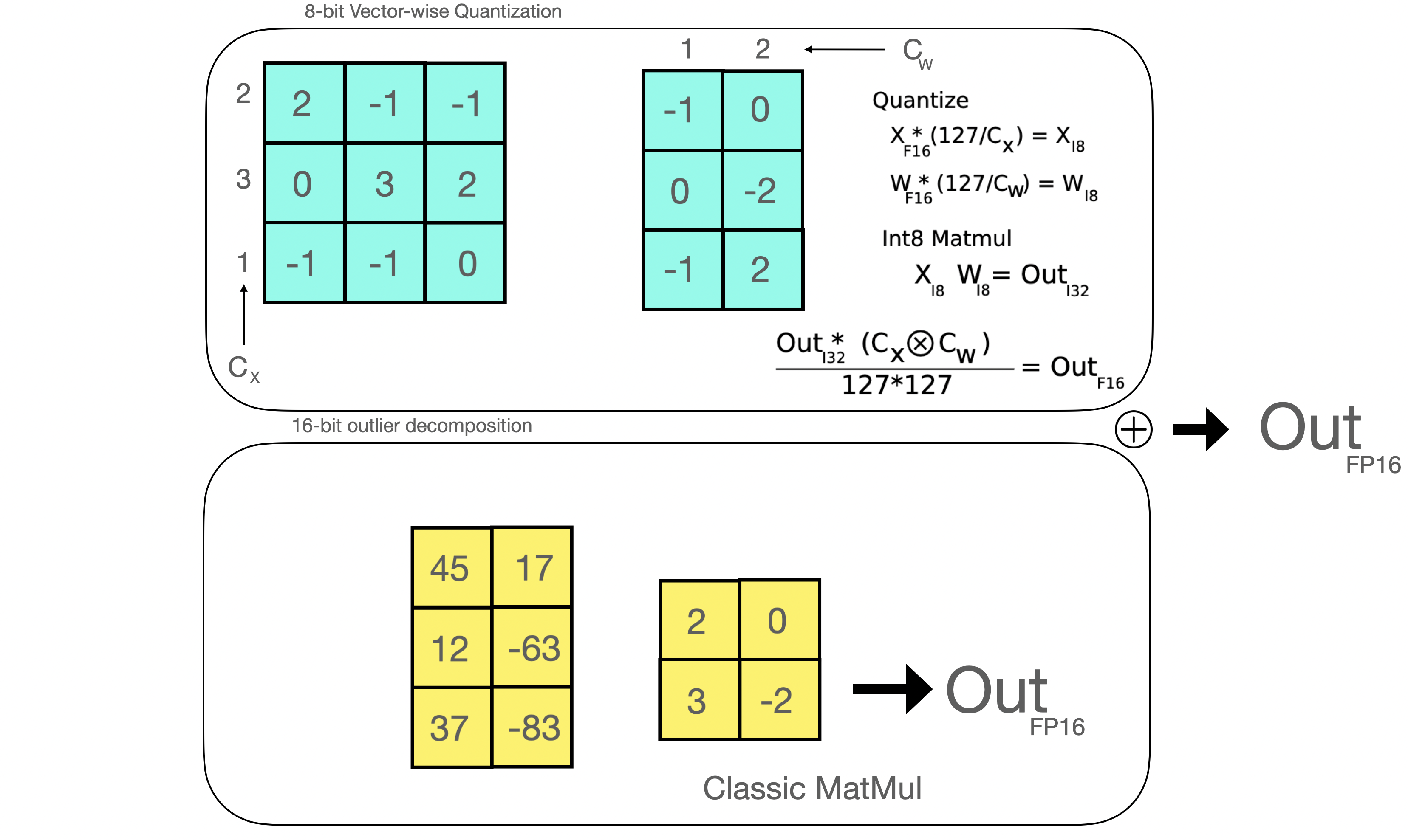
零退化意味着什么
如何评估性能下降?8-bit模型到底损失了多少性能?这里在8-bit模型和native模型上运行了常见的基准,分别针对OPT-175B和BLOOM-176B。
对于OPT-175B
| benchmarks | - | - | - | - | difference - value |
|---|---|---|---|---|---|
| name | metric | value - int8 | value - fp16 | std err - fp16 | - |
| hellaswag | acc_norm | 0.7849 | 0.7849 | 0.0041 | 0 |
| hellaswag | acc | 0.5921 | 0.5931 | 0.0049 | 0.001 |
| piqa | acc | 0.7965 | 0.7959 | 0.0094 | 0.0006 |
| piqa | acc_norm | 0.8101 | 0.8107 | 0.0091 | 0.0006 |
| lambada | ppl | 3.0142 | 3.0152 | 0.0552 | 0.001 |
| lambada | acc | 0.7464 | 0.7466 | 0.0061 | 0.0002 |
| winogrande | acc | 0.7174 | 0.7245 | 0.0125 | 0.0071 |
对于BLOOM-176B
| benchmarks | - | - | - | - | difference - value |
|---|---|---|---|---|---|
| name | metric | value - int8 | value - bf16 | std err - bf16 | - |
| hellaswag | acc_norm | 0.7274 | 0.7303 | 0.0044 | 0.0029 |
| hellaswag | acc | 0.5563 | 0.5584 | 0.005 | 0.0021 |
| piqa | acc | 0.7835 | 0.7884 | 0.0095 | 0.0049 |
| piqa | acc_norm | 0.7922 | 0.7911 | 0.0095 | 0.0011 |
| lambada | ppl | 3.9191 | 3.931 | 0.0846 | 0.0119 |
| lambada | acc | 0.6808 | 0.6718 | 0.0065 | 0.009 |
| winogrande | acc | 0.7048 | 0.7048 | 0.0128 | 0 |
可以看到这些模型的性能下降为0,因为这些指标的绝对差值小于标准误差。
比native模型更快?
LLM.int8()方法的主要目标在不降低性能的情况下,使得大模型更容易被使用。但是,如果该方法非常的慢则就不实用了。所以,我们对多个模型的生成速度进行了基准测试。实验发现使用LLM.int8()的BLOOM-176B要比fp16版本慢15%至23%,这是一个可以接受的范围。但是较小的模型下降会更多。开发人员正在逐步优化这个问题。
| Precision | Number of parameters | Hardware | Time per token in milliseconds for Batch Size 1 | Time per token in milliseconds for Batch Size 8 | Time per token in milliseconds for Batch Size 32 |
|---|---|---|---|---|---|
| bf16 | 176B | 8xA100 80GB | 239 | 32 | 9.9 |
| int8 | 176B | 4xA100 80GB | 282 | 37.5 | 10.2 |
| bf16 | 176B | 14xA100 40GB | 285 | 36.5 | 10.4 |
| int8 | 176B | 5xA100 40GB | 367 | 46.4 | oom |
| fp16 | 11B | 2xT4 15GB | 11.7 | 1.7 | 0.5 |
| int8 | 11B | 1xT4 15GB | 43.5 | 5.3 | 1.3 |
| fp32 | 3B | 2xT4 15GB | 45 | 7.2 | 3.1 |
| int8 | 3B | 1xT4 15GB | 312 | 39.1 | 10.2 |
Transformers集成
本文重点描述的模块是Linear8bitLt,你可以直接从bitsandbytes库中引入。其来自于经典的torch.nn模块,并使用下面的代码来轻易的使用和部署。
下面是一个使用bitsandbytes将一个小模型转换为int8类型。
正确的引入
1 | import torch |
定义一个fp16的模型。注意,你可以将任何精度的checkpoint或模型转换为8位(FP16、BF16或FP32),但目前,模型的输入必须是FP16,我们的Int8模块才能工作。所以我们在这里把我们的模型当作FP16模型。
1 | #先定义一个fp16的模型 |
假设该模型已经完成训练,保存模型
1 | [... train the model ...] |
现在再定义一个int8模型
1 | int8_model = nn.Sequential( |
添加参数has_fp16_weights很重要。默认值为True,其被用于Int8/FP16混合精度训练。然而,这里关注的是推理,所以将其设置为False。
现在将fp16的模型加载至int8模型中
1 | int8_model.load_state_dict(torch.load("model.pt")) |
首先我们查看量化之前的模型参数,通过print(int8_model[0].weight)如下:
1 | int8_model[0].weight |
接着运行上述第二行代码之后,通过输出print(int8_model[0].weight)可以看到模型被量化为Int8类型:
1 | int8_model[0].weight |
正如我们在前几节解释量化时看到的那样,权重值是 “截断的”。另外,这些值似乎分布在[-127, 127]之间。你可能也想知道如何检索FP16的权重,以便在FP16中执行离群的MatMul?你可以简单地做:
那么怎么还原为FP16权重呢?
1 | (int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127 |
可以得到:
1 | tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462], |
使用int8模型进行推理
1 | input_ = torch.randn((1,64), dtype=torch.float16) |
accelerate
当使用大模型时,acceleate库包含了有用的程序。init_empty_weights方法特别有用,因为任何模型(无论大小)都可以作为上下文管理器使用此方法进行初始化,而无需为模型权重分配任何内存。
1 | import torch.nn as nn |
这个初始化的模型会被放置至Pytorch的元设备上,其是一种不用分配存储空间来表示shape和dtype的潜在机制。
起初,该函数在.from_pretrained函数中被调用,并将所有参数重写为torch.nn.Parameter。但是,这不符合我们的需求,因为希望在Linear8bitLt模块中保留Int8Params类。因此我们将
1 | module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta"))) |
修改为
1 | param_cls = type(module._parameters[name]) |
通过这个修改,我们可以通过自定义函数在没有任何内存消耗的情况下,利用这个上下文管理器将所有的nn.Linear替换为bnb.nn.Linear8bitLt。
1 | def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"): |
该函数会递归的将元设备上的所有nn.Linear替换为Linear8bitLt模块。属性has_fp16_weights必须被设置为False,以便加载int8权重和量化信息。
如何在transformers中使用
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |