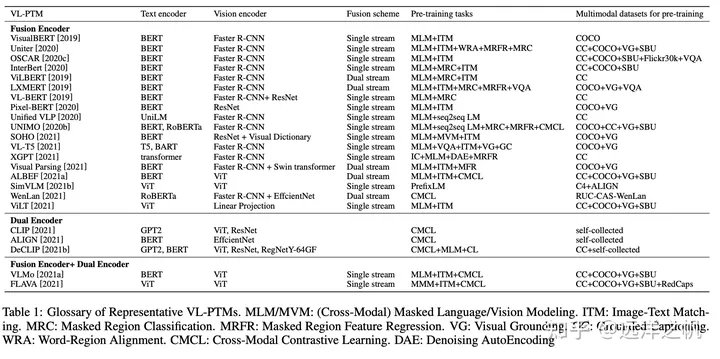
预训练模型在NLP和CV上取得巨大成功,学术届借鉴预训练模型–>下游任务finetune–>prompt训练–>人机指令alignment这套模式,利用多模态数据集训练一个大的多模态预训练模型(跨模态信息表示)来解决多模态域各种下游问题。
多模态预训练大模型主要包括以下4个方面:
1.多模态众原始输入图、文数据表示:将图像和文本编码为潜在表示,以保留其语义
2.多模态数据如何交互融合:设计一个优秀架构来交叉多模态信息之间的相互作用
3.多模态预训练大模型如何学习萃取有效知识:设计有效的训练任务来让模型萃取信息
4.多模态预训练大模型如何适配下游任务:训练好的预训练模型fintune适配下游任务
本篇文章主要参考:《A survey of Vision-Language Pre-trained Models》
前置任务:文本-图语料对准备
预培训数据集,预训练多模态大模型的第一步是构建大规模的图像文本对。我们将训练前数据集定义为,其中W和V分别表示文本和图像,N是图像-文本对的数量。具体来说,每个文本将被标记为一系列tokens 。同样,每个图像也将被转换为序列化物体特征(或grid特征或patch 特征),表示为。
多模态图、文数据表示
文本embedding + 图片ROI embedding
文本序列首先分为令牌,并与“[CLS]”和“[SEP]”令牌串联,表示为。每个令牌都将映射到一个单词嵌入。此外,在嵌入一词中添加表示位置的 pos embbding和嵌入模态类型的seg embbding,以获得的最终嵌入。
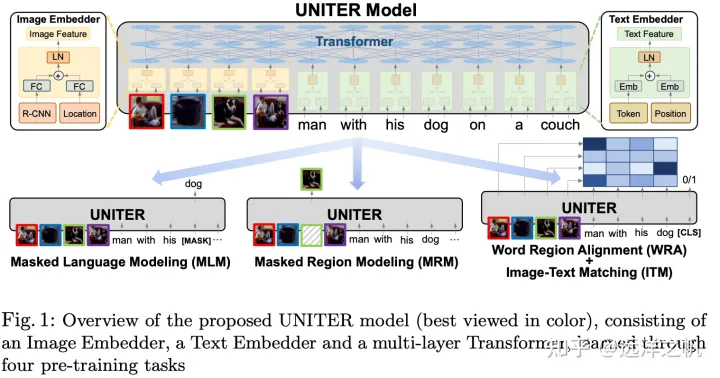
文本部分一般是直接复用BERT的内容,基本是没有太大变化的,但是视觉部分的变化就比较大了。如何设计一个比较好的视觉嵌入,去适应一个语言方面的预训练模型。早期的做法基于一个假设:图片提取出来的区域特征,最好和文本的token特征在同一个level上。比如可以使用faster Rcnn去提取一些区域特征,使用ROI feature作为内容信息,将bounding box作为位置信息( ViLBERT [Lu et al., 2019] 、 LXMERT [Tan and Bansal, 2019] )。
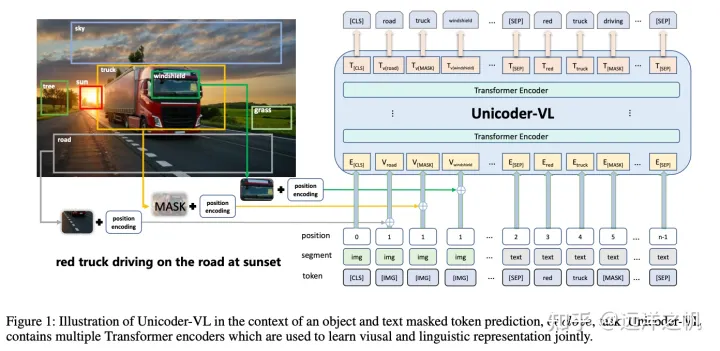
OSCAR将object tag作为信息进行输入,object是将信息转化为一个文本标签,构建了视觉信息和文本信之间的桥梁,达到了视觉和文本的一致性。

问题:
1.需要额外训练一个roi提取模型,模型准确性影响预训练模型准确性
2.不同图片roi个数是不确定的,预训练模型需要相对固定roi个数导致信息丢失
3.roi数据集准备复杂,目标检测模型得到的都是矩形的目标,其不适合于不规则的物体,导致得到的bounding box中存在噪声。另外,除了bounding box以外,一些背景信息是无法提取出来的,相当于即存在噪声,也存在损失。对效果产生一些影响。
4.下游任务不一定适配用roi粒度特征,比如在一个domain预训练的目标检测模型,将其转换到另外的domain中,效果可能有相当大的gap,影响模型的效果。
文本embedding + 图片Grid embedding
ROI来表示图像特征数据是region粒度特征,信息颗粒度太大容易带来信息丢失、下游任务不适配、非端到端模导致使用不方便等问题。为了解决region特征表示问题提出Grid embedding方式表示图像数据。放弃ROI,转而使用cnn或者resnet抽取Grid Embedding,以便图像编码器可以将图像作为一个整体查看,避免忽视一些关键区域的风险。
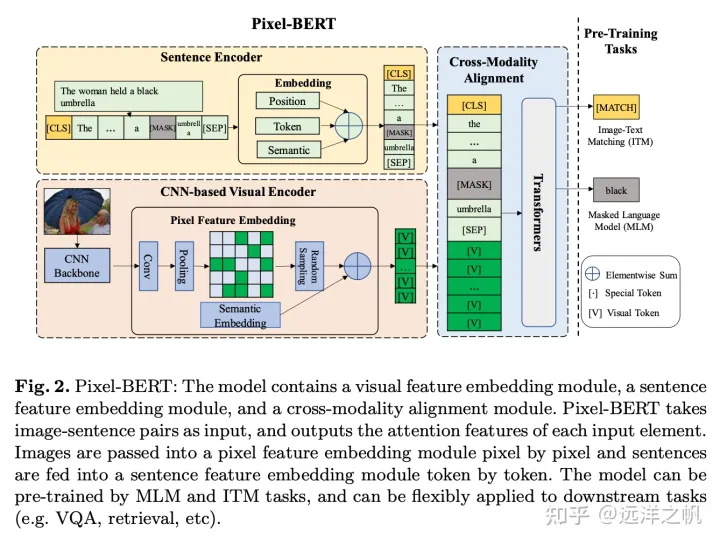
Pixel-Bert用cnn抽取图像Grid embbeding
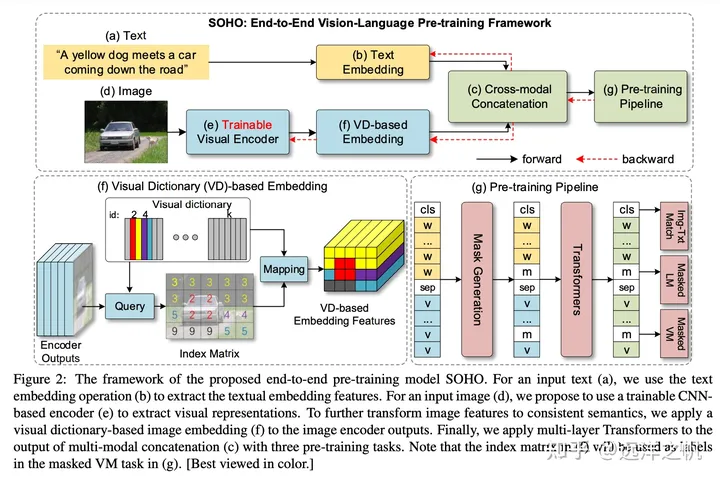
SOHO用resnet抽取Grid embedding
优点是可以编码整张图片,避免了bounding box只能编码部分图片的缺陷,其二是CNN不必非要做一个预训练才可以提取region的特征,其是一个可以和整个预训练模型一起训练的端到端的模型。
文本embedding + 图片Patch embedding
随着VIT的兴起,出现了patch based的特征提取,将一张图片分为若干patch,并且使用线性变化的方式对其进行编码。
图像首先被拆分为拍平为2D patch,然后序列化embdding图像的patch,来表示原始图像特征。模型是端到端表示且用的transformer架构可以并行化计算,所以VIT做patch推理速度会快很多

小结:
1.文本部分一般是直接复用BERT的内容,基本是没有太大变化的。
2.视觉部分的变化就比较大了,主要有region embbding表示、Grid embbding表示、Patch embbding表示

多模态信息融合模型:
融合模型将文本embbding和图像特征作为输入,让几种模态的信息融合交互以达到跨模态信息表示、知识萃取
Fusion Encoder
fusion encoder主要有两种类型的融合方案:单流架构和双流架构。在self-attention 或 cross-attention 对图文数据表示操作后,不管是单流网络还是双流网络,其最后都将transformer的最后一层输出作为多模态融合的结果。
单流架构
单流网络直接将两个模态的内容加以拼接,之后输入到transformer中。相当于是将单模态内的交互和多模态之间的交互合到一起来做。比如vision的q来自于图像,其k和v即来自于图像也来自于文本;文本这边也是如此。
其最大的好处是其参数的高效性。并不需要将跨模态的交互和单模态的交互放到一起来做,因此是十分节约参数的。
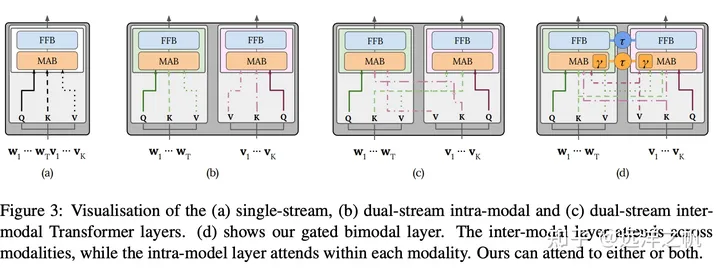
双流架构
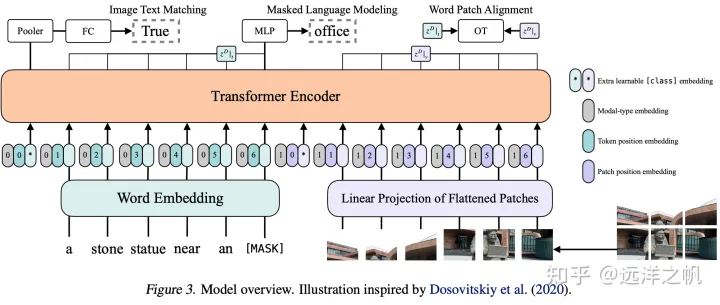
但是有人argue觉得这种方式的单模态特征都是刚刚提取到的,是没有学习很好的单模态特征,因此是具有一定局限性的。所以提出双流机构的解决方案,双流网络是先在单模态的场景下将模态内的交互做好,之后在多模态场景下,做好多模态的交互。
与单流架构中的自注意操作不同(单流是把视觉embbeding和文本embbding concat系,相当于融合后做KV自注意力),双流架构采用交叉注意机制来建模V-L交互中,其中查询向量来自一种模式,而键和值向量来自另一种模式。交叉注意力层通常包含两个单向交叉注意力子层:一个从语言到视觉,另一个从视觉到语言。他们负责在两种模式之间交换信息和调整语义。

Dual encoder
fusion encoder的操作不可避免的需要使用transformer进行模态之间的融合,但是在很多对时间敏感的任务上其实是没有必要的。
Dual encoder对文本和图像进行编码,仅仅使用相似度的交互,进行浅层的交互。
文本用一个text encoder去编码,图像用一个image encoder进行编码,他们之间并不需要进行特别多的交互,其最后仅需要用一个简单的计算,比如相似性度量进行计算,即可。
其优点是,表示是预训练好的,另外文本编码器和图像编码器是完全解耦的,可以用于很多单模态任务上。但是因为其只进行了浅层的交互,因此这类模型无法适用于多模态推理方面的工作。
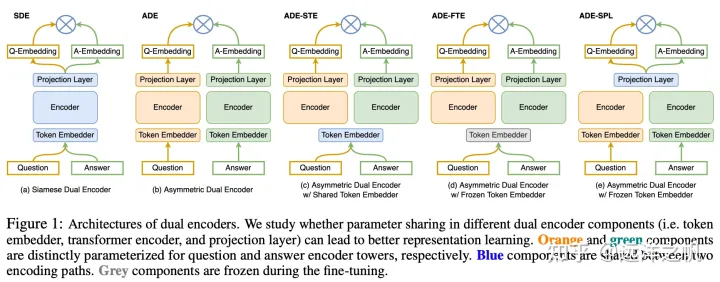
Fusion Encoder + Dual encoder

fusion encoder模式融合图信息和文信息交互的更深入,能学习到更细粒度的跨模态信息特征,但是推理速度相对较慢、数据复杂度也会更高。而dual encoder把单独抽取好的图信息和文信息,在高层面简单的做点乘跨模态信息交融不够;但是数据处理简单、推理速度更快、得到更宏观层面的图文信息。有没办法把两种encoder方式融合,让模型及科研学习到细粒度的多模态信息也可以学习到更宏观的多模态表示,同时能够根据不同的下游任务需要可控的选择性突出哪部分表示能力,加快下游任务的推理速度。

fusion encoder比较容易处理多模态融合的推理问题,dual encoder比较适合处理跨模态检索的问题。VLMO提出了将两者融合在一起的解决方案。
V-L模型适合解决多模态的信息,但是不是非常适合解决文本的信息,UNIMO给出了解决方案。OFA给出了视觉任务,文本任务,以及多模态任务三种任务的一个统一的解决方案。
多模态预训练模型学习手段
根据前面的介绍,在输入图像和文本编码为矢量并完全融合交互后,下一步是为VL-PTM设计预训练任务,设计的预训练任务对VL-PTM可以从数据中学到什么东西有很大影响。这部分,我们将介绍一些广泛使用的预训练任务。
Cross-Modal Masked Language Modeling (MLM)
多模态MLM任务和nlp中bert模式很相似,通过MASK掉一部分的信息,通过没有MASK的信息来推理出MASK的表示。但与NLP不同地方在于,需要考虑如何设计学习任务。让多模态预训练模型不能只是单纯的依靠文本或者图像上下文信息就推理出MASK掉的表示是什么,而应该依赖与另外模态的信息才能推理出MASK的信息表示是什么。这样的任务设计才能让文本和图像信息之间产生关联,有上下文信息依赖,多到跨模态信息之间的对齐。
ViLT [Kim等人,2021年]采用了全字屏蔽策略,该策略防止模型仅通过周围文本信息就可以预测被MASK掉的信息表示;InterBERT [Lin等人,2020年]屏蔽了连续的文本片段,以使这预训练学习任务更加困难,并进一步改进了其在下游任务上的表现。
Cross-Modal Masked Region Prediction (MRP)
与MLM相似MRP也是通过对对部分信息MASK,通过没被MASK信息推测MASK的表示。MRP通过MASK掉一些ROI区域,然后根据其它图文信息预测出ROI区域信息表示。主要有两大类训练任务预测被MASK的区域是什么物体Masked Region Classification (MRC) 和预测被MASK区域的信息表示 Masked Region Feature Regression (MRFR) 。
Masked Region Classification (MRC)
MRC学习预测每个屏蔽区域的语义类,预测的是图像的更高层次的语意,而不是预测MASK部分每个像素。通过预测被MASK区域的是那个类,相当于在做object detect中的物体分类。用交叉熵方式来作为loss,通过没有被MASK的图文信息来预测被MASK区域可能是什么物体(做分类)。
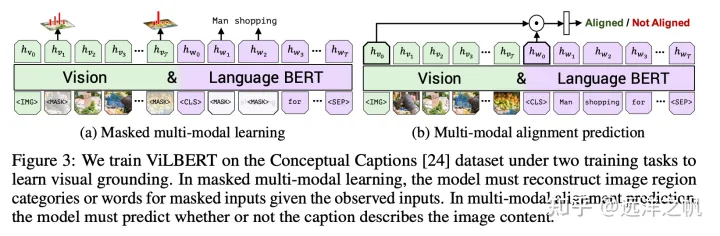
Masked Region Feature Regression (MRFR)
MRFR通过未MASK区域的图文信息回归预测MASK区域的原始区域特征,MRFR要求模型重建高维向量,而不是语义分类。

Image-Text Matching (ITM)
MLM和MRP帮助多模态预训练模型学习图像和文本之间的细粒度相关性,而ITM 为多模态预训练模型提供在粗粒度水平上对齐的能力。ITM类似NLP中预测上下两句话相似度的任务,给一对图文对预测他们之间是否匹配。
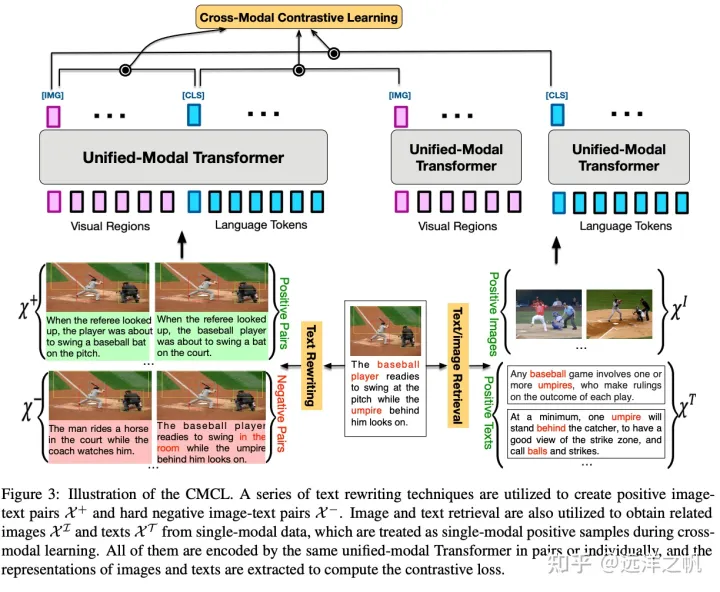
Cross-Modal Contrastive Learning (CMCL)
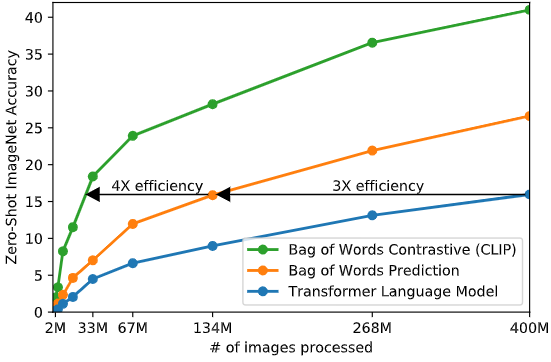
CMCL旨在通过将匹配的图像文本对的嵌入点推在一起,同时将不匹配的图像文本对分开,在同一语义空间下学习通用视觉和语言表达。有点类似nlp和cv里面的trip loss方式(比较学习),值得注意的是,CMCL中的对比loss是对称的,文本到图像的对比loss也类似。CLIP和ALIGN利用大规模的图像文本对来cmcl学习,并在图像分类任务表现出令人惊讶的zero-shot效果。
多模态预训练模型下游任务
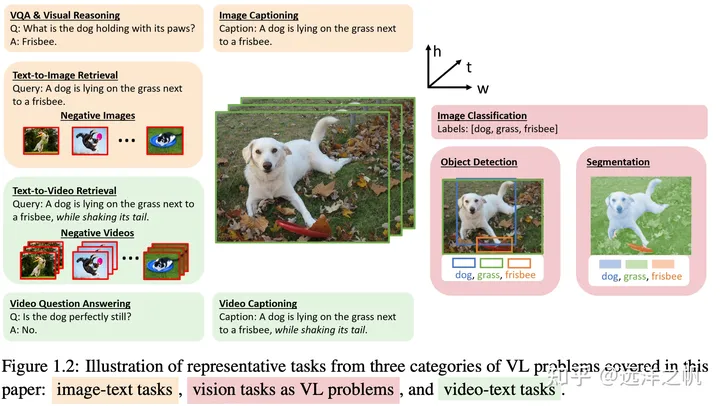
下游任务包括理解和生成。
理解部分:
图文检索
ITR是一项典型的跨模态匹配任务。这项任务需要检索与给定句子最匹配的图像,反之亦然。使用融合编码器架构的早期VL-PTM获得融合矢量表示,该表示后来被预测为相似性分数[Lu等人,2019年;Li等人,2019年;Li等人,2020年c]。CLIP[Radford等人,2021年]和ALBEF[Li等人,2021a]等双编码器架构对ITR来说效率更高,因为它们可以在检索之前预先计算和存储图像和文本的嵌入。
视觉引用表达
VRE是NLP中引用表达式任务的扩展。目标是将区域定位在与特定文本描述相对应的图像中。
看图回答问题(VQA)
VQA是一项广泛使用的跨模态推理任务。与基于文本的QA不同,VQA需要回答有关图像的问题。大多数研究人员将VQA视为一项分类任务,并要求模型从答案库中选择正确的答案。具有融合编码器架构的VL-PTM通常将最终的跨模态表示(通常对应于输入[CLS]令牌)映射到答案标签的分布。因此,dual encoder架构的VL-PTM对VQA任务不那么有效,因为两种模式信息融合太浅,无法进行跨模式推理。现在有一些研究将VQA建模为生成任务,这可以更好地推广到现实世界的开放式场景。
感知任务
利用预训练大模型来实现zero-shot或者是few-shot的图片分类、物体识别、segment边界划分。
生成部分:
生成任务可以被认为是图像-文本的双重任务,生成任务可以分为文本到图像生成和图像到文本生成(多模式文本生成)。
图到文生成
imagecaption图像描述技术,就是以图像为输入,通过数学模型和计算使计算机输出对应图像的自然语言描述文字,使计算机拥有 “看图说话”的能力,是图像处理领域中继图像识别、图像分割和目标跟踪之后的又一新型任务.。
在日常生活中,人们可以将图像中的场景、色彩、逻辑关系等低层视觉特征信息自动建立关系,从而感知图像的高层语义信息,但是计算机作为工具只能提取到数字图像的低层数据特征,而无法像人类大脑一样生成高层语义信息,这就是计算机视觉中的“语义鸿沟”问题.图像描述(字幕)技术(Image Caption Generation)的本质就是将计算机提取的图像视觉特征转化为高层语义信息,即解决“语义鸿沟”问题,使计算机生成与人类大脑理解相近的对图像的文字描述,从而可以对图像进行分类、检索、分析等处理任务。
文到图生成
文本到图像生成是从描述文本生成相应图像的任务。这部分前面文章已经做过详细介绍,这边不在展开介绍。需要进一步了解的可以翻阅我前面文章。
随着生成任务的完善,最近研究开始进行多模态的图片生成。利用文本描述,把输入的参考图片、边界信息作为控制变量来限制生成图的风格,controlnet。甚至出现输入视频作为参考控制,通过文本描述来生成视频的任务