命名实体识别任务(NER)是NLP领域的一个研究热点。大部分使用序列标记框架来解决该问题,但是序列标记框架通常难以检测出嵌套的实体。基于Span的方法可以很容易地检测出不同子序列中的嵌套实体,因此适用于解决嵌套NER问题。然而,现有的基于Span的方法有两个主要问题。第一,对所有子序列进行分类识别在计算上很昂贵,而且在推理上效率很低。第二,基于Span的方法主要集中在学习Span表示,但缺乏明确的边界监督。针对上述两个问题,本文提出了一种边界增强型neural span 分类模型。除了对Span进行分类之外,还加入一个额外的边界检测任务来预测那些作为实体边界的单词。并在多任务学习框架下进行联合训练,在附加边界监督的情况下增强了跨度表示。此外,边界检测模型能够生成高质量的候选跨度,大大降低了推理过程的时间复杂度。
本文主要解决嵌套NER问题,如下所示:
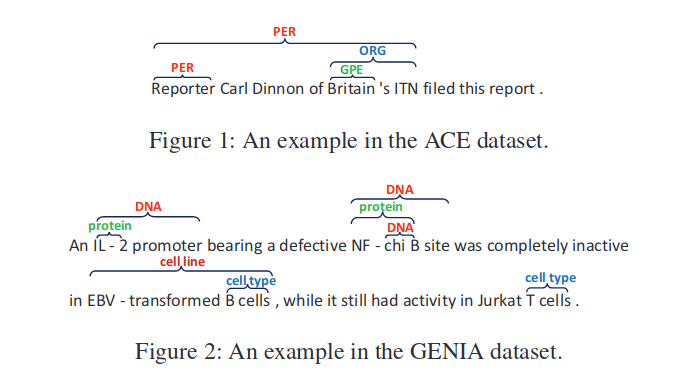
数据集中每一个单词不再只有一个标签,可能存在多种标签。本文提出的BENSC模型的主要思想为:在给定一个句子,首先,对word进行语义编码,其次利用多任务学习思想联合训练边界检测模型和Span分类模型。边界检测模型主要预测每个词是否实体的开始或者结束。Span分类模型主要融合Span的信息预测其标签。在推理过程中,可以通过边界检测模型得到边界置信度和,通过Span分类模型具有置信度的标签C,这三个分数将共同决定一个Span是否是带有标签C的实体。
整体模型结构如下:
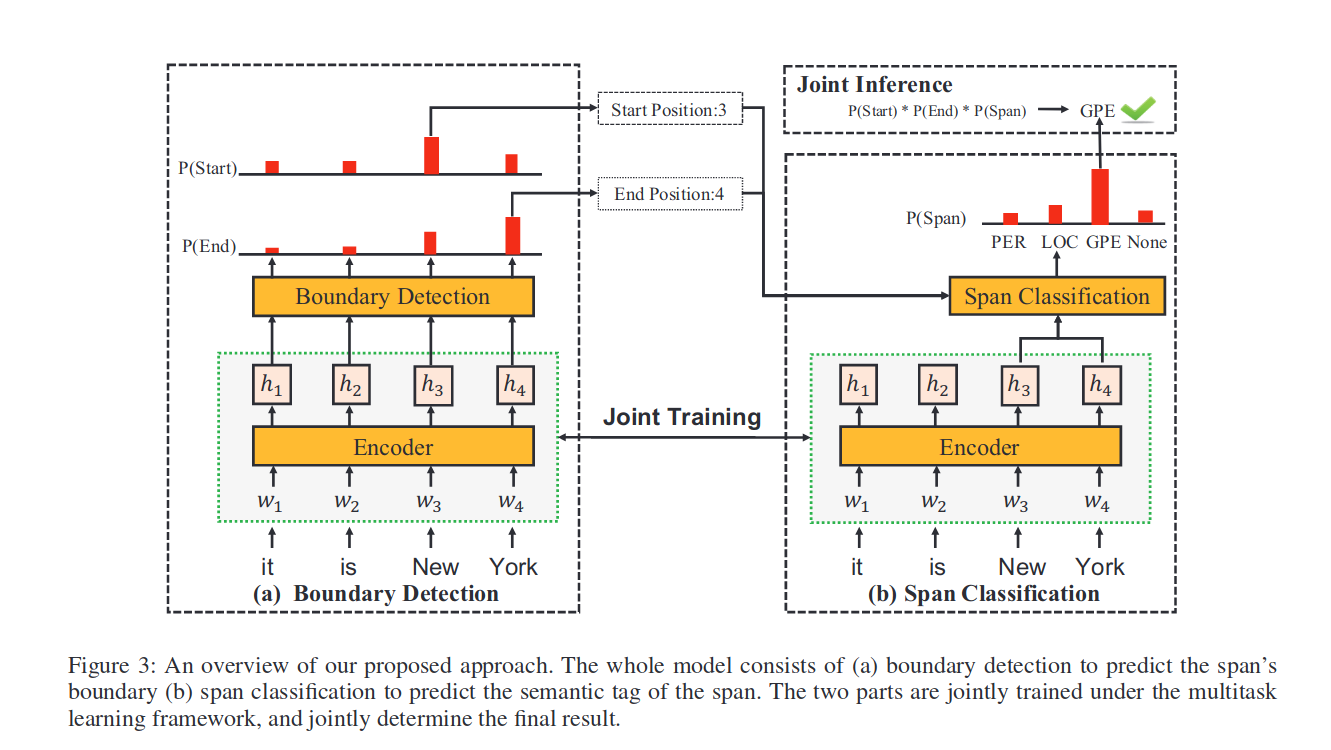
Encoder
在encoder部分,作者使用了两种encoder器,分别为LSTM和BERT,其中LSTM编码主要输入为word、char和pos嵌入。
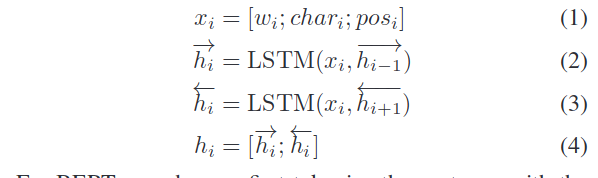
BERT编码主要输入为wordpiece tokens。
Boundary Detection
边界检测部分不在使用传统的序列标签检测模型识别,而是使用两个softamx层分别预测每一个词是否为实体的开始和结束标记。即:

loss如下:
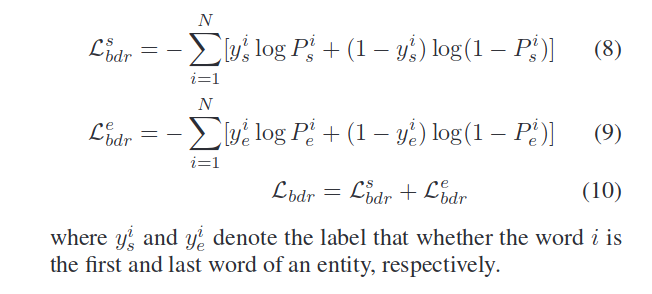
Span Classification
Span分类模型就是正常的对进行标签分类。loss如下;

Joint Training and Inference
总的训练loss为:
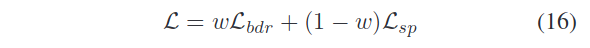
其中w为学习参数。
实验结果
本文主要在s ACE2004, ACE2005 和 GENIA 三个数据集进行实验:
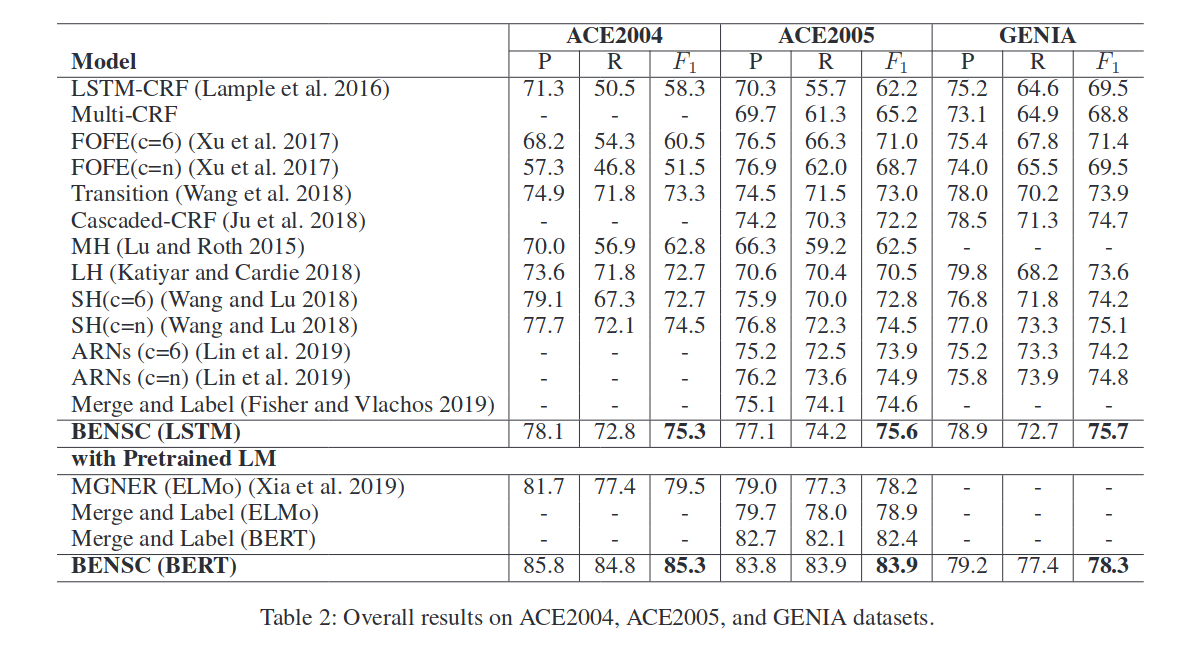
可以观察到,联合训练边界检测模型和跨度分类模型可以提高这两个任务的结果。首先,与单独边界检测模型相比,预测起始边界和结束边界的结果有了一些改善。然后,与原跨度分类方法相比,结合边界检测模型的ACE204、ACE205和GENIA数据集的绝对增益分别为4.5%、4.9%和1.8%。