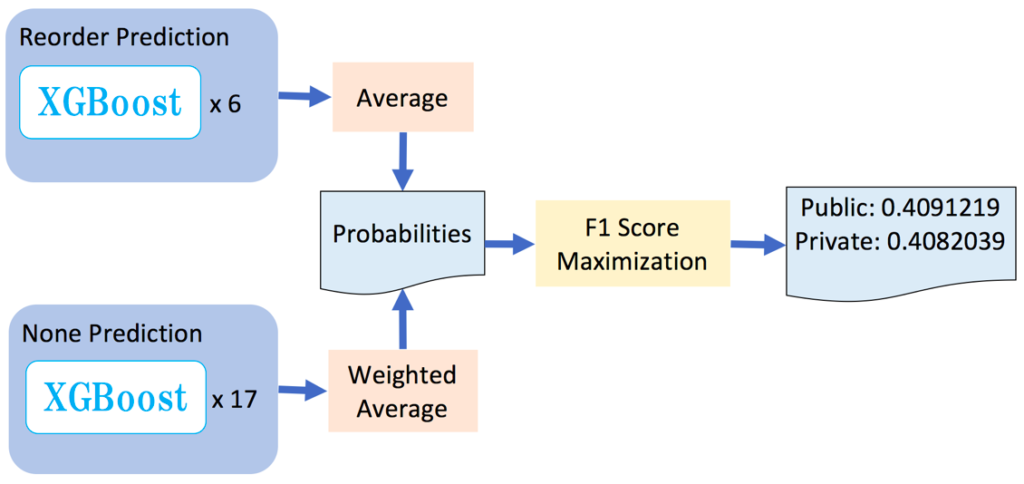
kaggle上的比赛,从作物幼苗中区分出杂草,有效的解决方案意味着更好的作物产量及更好的环境管理。
奥胡斯大学信号处理组与丹麦南方大学合作,发布了一个数据集,其中包含不同生长阶段的 12 个种类大约 960 种植物的图像 ,
数据集下载地址:https://www.kaggle.com/c/plant-seedlings-classification

上述图像数据已公开发布。它包含带注释的 RGB 图像,分辨率约为每毫米 10 个像素。
采用基于 F1 分数的指标对分类结果进行评估。以下图像是描述数据集中所有 12 个类的示例:

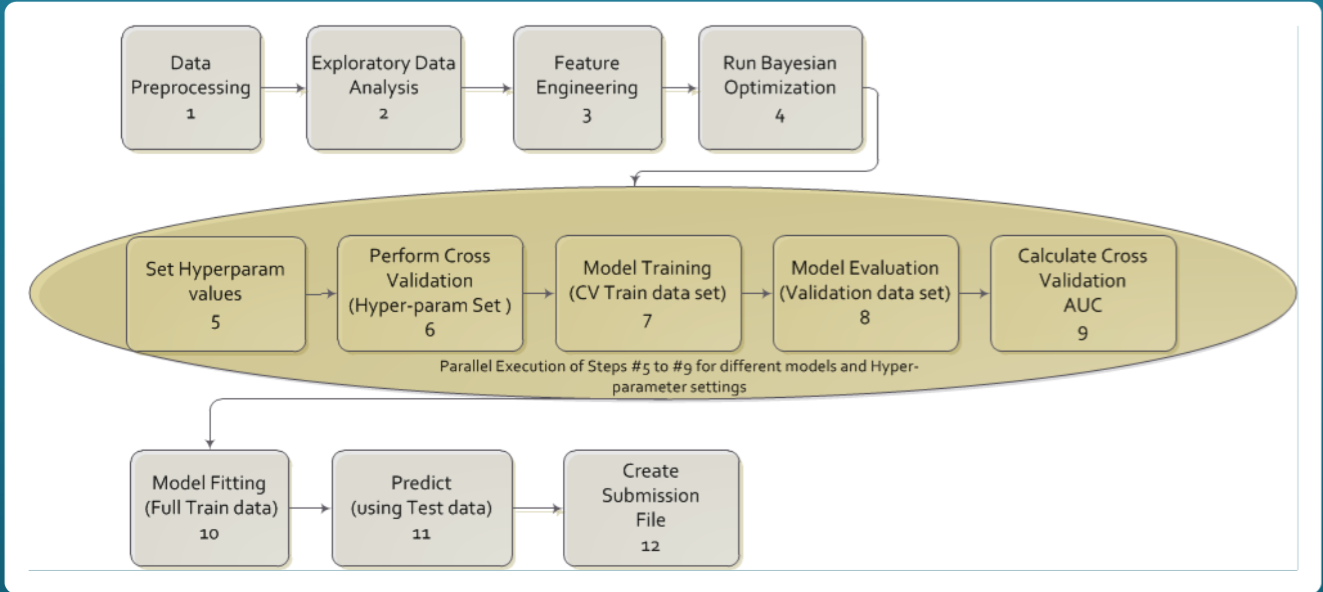
我们主要按照一下5步骤完成图片分类任务:
step 1
机器学习的首要任务是分析数据集,然后进行算法实验。了解数据集的复杂性,这一步很重要,这最终将有助于算法的设计。
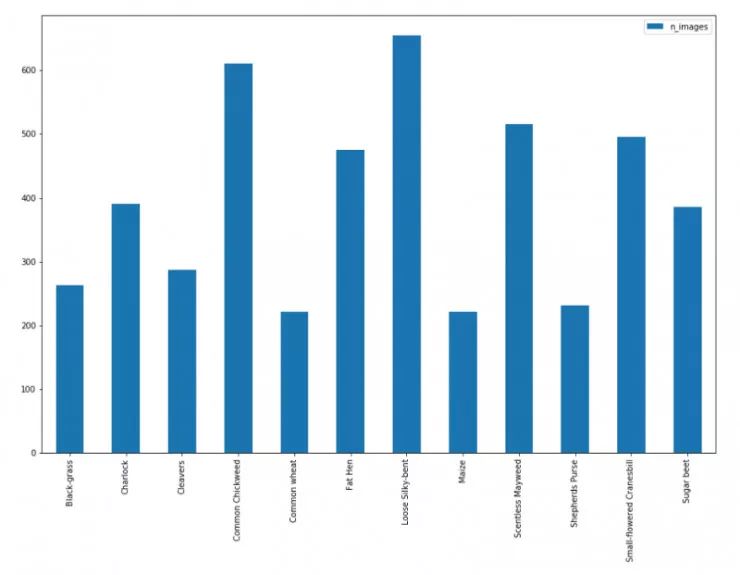
该数据的标签分布如下:
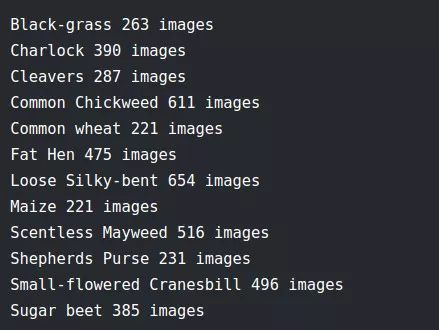
如上所述,该数据集包含 12 个类共 4750 个图像。但是,从上图可以看出,各类分布不平均,最大 个数为654 张,而最小个数为 221 张。下图清楚地表明数据是不平均的,因此,为了获得更好的结果,我们需要对原始数据进行类平衡处理。step 3 中我们将完成此任务。
通过对图像进行可视化十分重要,以便能更好了解数据。因此,我们将展示每个类中的部分示例,查看图像的不同之处。

所有的图像看起来都相差无几,几乎没有什么内容可以从上面的图像群中获得。因此,我决定使用t-SNE对图像数据分布进行可视化。
t- SNE是一种特别适合于高维数据集的可视化降维技术。该技术可以通过Barnes-Hut approximations逼近模型实现,这允许该技术应用于现实世界的大型数据集。
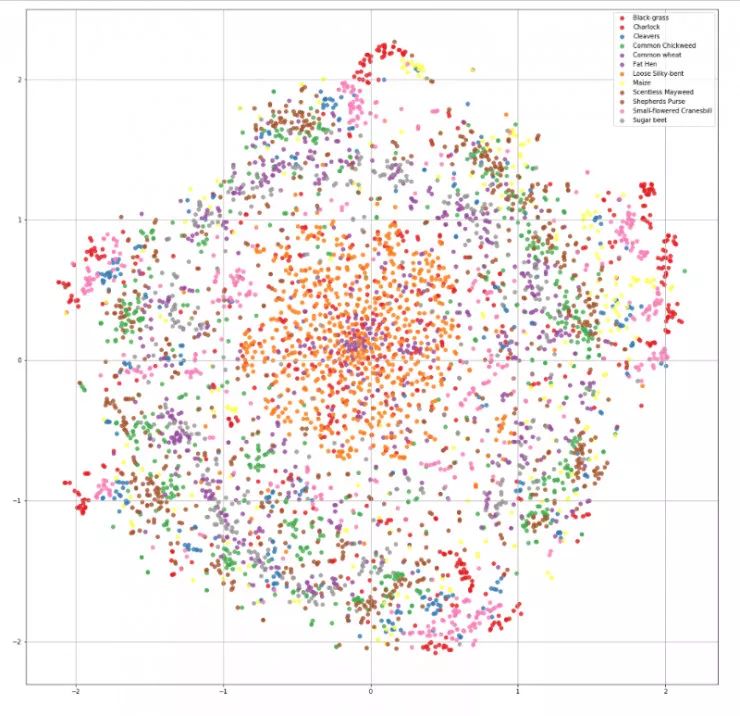
在仔细观察后,我们几乎看不出各类间差异。因此,需要理解该数据对人而言难以分辨的,还是对于机器学习模型同样如此。为此,我们将实验一个baseline。
训练以及验证集合
在模型基准开始之前我们需要将数据划分为训练数据和验证数据集,对原始测试集进行测试之前验证集起到测试数据集作用。所以,模型基本上在训练数据集上进行实验,并在验证集上进行了测试,之后模型随着集合的多次验证得以改进。一旦我们对验证集的结果感到满意,就可将模型应用于实际测试数据。我们能够以此看到模型在我们的验证集上是过拟合还是欠拟合,这可以帮助我们更好地调整模型。
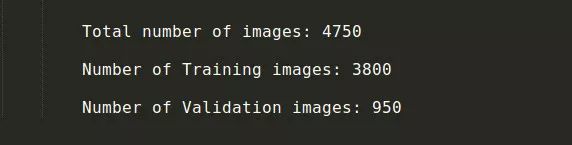
将 80% 图像作为训练数据集及 20% 作为验证集,具体的数据详情如下:
step 2
一旦我们得到了训练集和验证集,我们就从数据集的基准开始着手。从数据集中,我们可以看到这是一个分类问题,我们需要把测试集中的每一个实例划分为 12 类中的一类。所以我们将会用一个卷积神经网络(CNN)去完成这个任务。
有很多途径去创建一个 CNN 模型, 但是作为初学者, 我们最好使用 Keras 深度学习库. 我们也将使用 Keras 上提供的预训练模型, 这些模型是在 ImageNet 数据集上训练过的并且我们可以通过微调这些模型以用于我们这里的任务。
从头开始去训练卷积神经网络实际上是非常低效的。所以,我们采用在有着 1000 类的 ImageNet 数据集上预训练过的 CNN 模型参数,并且在微调时,我们固定住一些层的参数,其他层的参数继续在我们这里的数据集上继续训练。这样做的原因是因为比较前面的一些层是用来学习图像的基本特征的,我们没有必要去训练并且可以直接在我们的任务里直接采用。一个值得我们注意的重要事情是,我们要去检查我们这里的数据集跟 ImageNet 相似度大小。这两个数据集的特性决定了我们该如何进行网络微调。想要获取关于网络微调的详细资料,请参考 Andrej Karpathy 的博客:
对于我们这里的例子,数据集是很小的,并且还跟 ImageNet 有点相似。所以我们首先直接用 ImageNet 上的权重,并加上有着 12 个类别的最终输出层来构建我们的第一个基准程序。接着,我们训练一些后面的层,前面层的权重仍然保持固定。
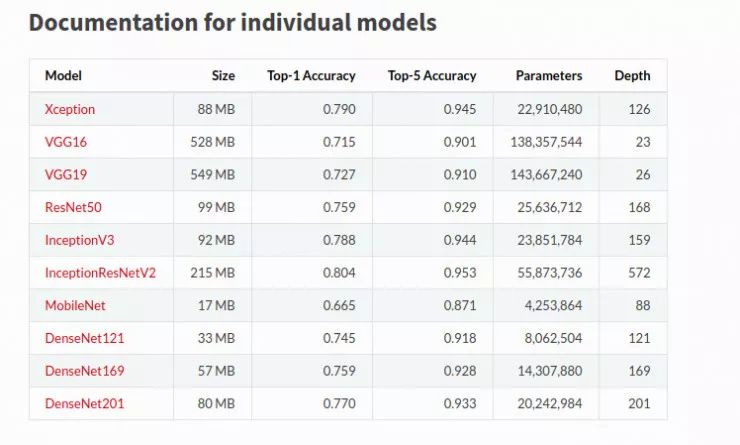
因为 Keras 提供很多的预训练模型,我们将用 Keras 去完成我们最初基准程序,我们将在我们的任务上用 ResNet50 和 InceptionResNetV2 这两个模型。为了理解模型是过拟合还是欠拟合,为数据集准备一个简单模型和一个复杂模型作为基准是非常重要的。

我们也可以检查这些模型在 ImageNet 数据集上的性能或者这里的每一个模型的参数数量来选择我们的基准模型。
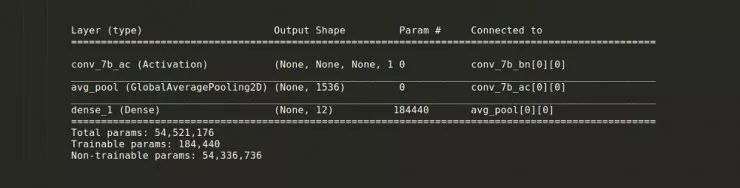
对于第一个基准模型,我去掉了最后的输出层,并且只增加了对应着 12 个类别的输出层。模型结构如下,我们可以看到参数量,这里只截取了最后几个层的信息。
模型总共训练了 10 次epochs,6 次epochs以后结果饱和了。训练集上的准确度达到了 88%,验证集上也有 87% 的准确度。

为了提高性能,我们释放一些前面的层,并以一个指数下降的学习率去训练这些层。这个可以进一步得到 2% 的提升

这个过程中使用到的一些超参数:

step 3
在具备相关知识的基础下,我们可以尝试着增加图像数据的数量以改进上述模型。
没有数据,就没有机器学习!
需要注意的是我们所拥有的数据存在数据类别不平衡的情况。我们首先应该处理这一问题,从而使得模型的每批样本即便拥有少量图像数据,也能达到较好的分类效果。
现实生活中的数据集很少能够达到数据平衡,而且模型对少数类样本的分类效果并不好。错误地分类一个少数类样本往往比错误分类一个正常数量样本会付出更大的代价。
我们可以用以下两种算法来解决数据不平衡问题:
- 不均衡学习的自适应合成抽样算法(ADASYN):ADASYN 通过更多地合成更难学习的数据集,从而为少数类样本合成更多数据。
ADASYN 算法的基本思想是根据数据的学习难度,对不同的少数类样本进行加权分布。相比那些容易学习的少数类样本,为那些更难学习的少数类样本合成更多的数据。因此,ADASYN 算法通过以下两种方式来改善数据:1)减少类不平衡引起的偏差,2)自适应地将分类决策边界转向学习困难的样本。
- 合成少数类过采样算法 (SMOTE):SMOTE 通过对少数类的过度采样和对多数类的采样,从而获得最佳结果。
相比于对多数类样本进行欠采样,通过对少数(异常)类样本进行过采样和对多数(正常)类进行采样相结合的方式,从而实现更好的分类效果(在 ROC 空间中)。

针对这个实例,SMOTE 算法相比 ADASYN 算法表现得更加出色。一旦数据达到平衡,我们便可以把这些数据用于数据集的扩充。
另外有一些数据增强方法,其中比较重要的有:
- 缩放
- 裁剪
- 翻转
- 回转
- 翻译
- 增加噪声
- 改变照明条件
- 像 GAN 这样的先进技术
现在已经有一些非常好的博客可以解释以上所有技巧。比如参考文献[8][9], 因此这里不再细述。这里用到了上面提到的除 GAN 之外的所有数据增强技术。
step 4
为了进一步提高图片分类结果的准确性,我们使用了周期性学习率和热重启学习率。但是在我们使用这些学习率之前,我们需要找到这个模型的最佳学习率。作一张学习率和损失函数的图,找到损失开始减少的地方,这样我们就找到了模型的最佳学习率。
本文介绍了一种新的设置学习率的方法,称之为周期性学习率,用这种方法,我们几乎可以不用试探性地寻找全局学习率的最优值和学习率时间表。这种方法不是单调地降低学习率,而是使学习率在合理的边界值之间周期性变化。使用周期性学习率的方法进行训练而不用固定值,只需要少量的迭代并且不需要调整,就能够提高训练的准确度。[10]
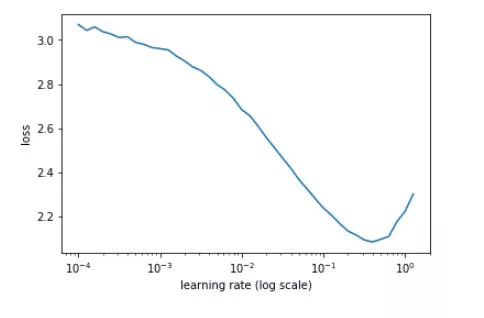
在我们的实例中, 1e-1 看起来是一个完美的学习率。但是我们想用更少的步骤来接近我们的全局最小值。其中一种方法是使用学习率退火,但是我使用了热重启学习率,这个灵感来自于这篇论文 [10]。与此同时,优化器的优化算法就被从 Adam 算法改为 SGD 算法和 SGDR 算法。
接下来,我们就可以开始使用上述技术来去训练几个模型,然后将训练后的结果合并在一起。这就是我们所说的模型融合(Model Ensemble),这个技术已经非常流行了,但是计算起来非常消耗资源。
因此,我决定采用一种叫做快照集成(snapshot ensembling)的技术,该方法通过训练单个神经网络来达到集成的目的,然后沿着它的最优路径收敛到几个局部的最小值,最后保存模型数据。
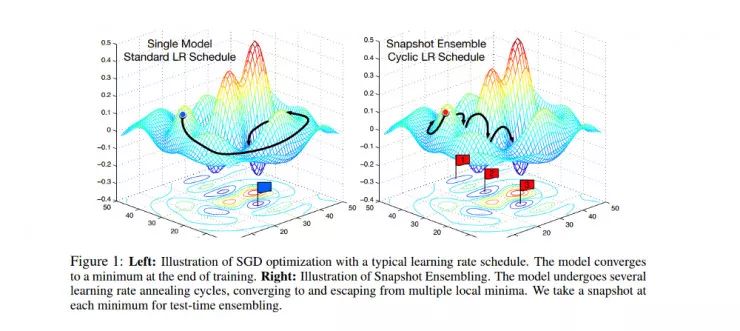
一旦学习率方法确定下来,我就开始对付图像的尺寸。我训练了一个图像大小为 6464(在 ImageNet 数据集上微调)的模型,释放了一些层,并使用周期性学习率和快照集成技术,得到了模型的权重,然后将图像的大小改为 299299,再一次对图像大小为 64*64 的权重,然后使用快照集成和热重启学习率技术。
在后续的处理中,只要我们的图像大小发生了变化,我们就需要再一次使用学习率和损失函数去得到最优的学习率。
step 5
最后一步是将结果可视化,这一步是为了检查哪一种图像分类具有最好或最差的性能,同时这也是提高训练准确性的必要步骤。
构造混淆矩阵是了解模型好坏的一个非常有效的方法。
在机器学习领域,尤其是统计分类问题、混淆矩阵(confusion matrix),又称为错误矩阵,它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一行代表了预测值,每一列代表的是实际的类别(反之亦然)。这个名字来源于它可以非常容易的表明系统是否将类个类别混淆(也就是一个 class 被预测成另一个 class)。
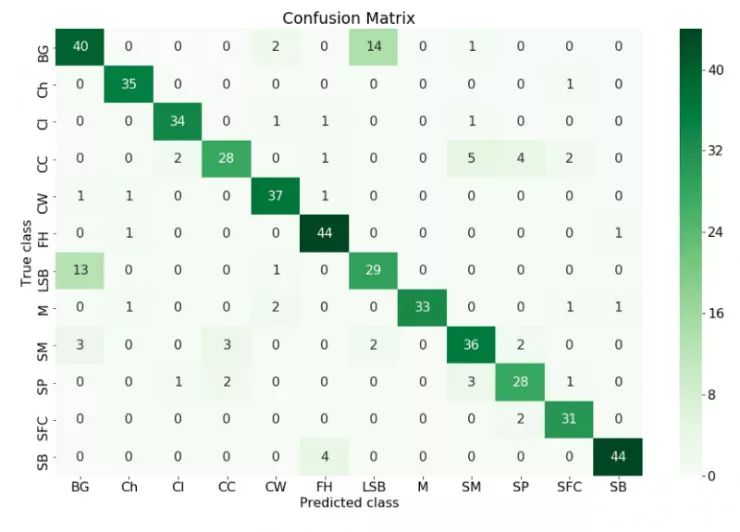
我们可以从混淆矩阵的所有类中看出,模型的预测标签是不同于实际标签的,我们可以采取一些措施去改进它。我们可以增大数据量来让模型学习到那个类。
最后,将验证集合并到训练数据集,并使用所获得的超参数,对模型进行最后一次训练,并在最后的提交之前对数据集进行评估。
注意:为了达到最佳的效果,训练中所强化的数据需要存在于数据集中。
参考文献
[1] https://www.kaggle.com/c/plant-seedlings-classification
[2] https://arxiv.org/abs/1711.05458
[3] https://vision.eng.au.dk/plant-seedlings-dataset/
[4] https://keras.io/applications/
[5] https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=4633969&tag=1
[6] https://jair.org/index.php/jair/article/view/10302
[10] https://arxiv.org/pdf/1608.03983.pdf
[11] https://arxiv.org/pdf/1506.01186.pdf
[12] https://arxiv.org/abs/1704.00109