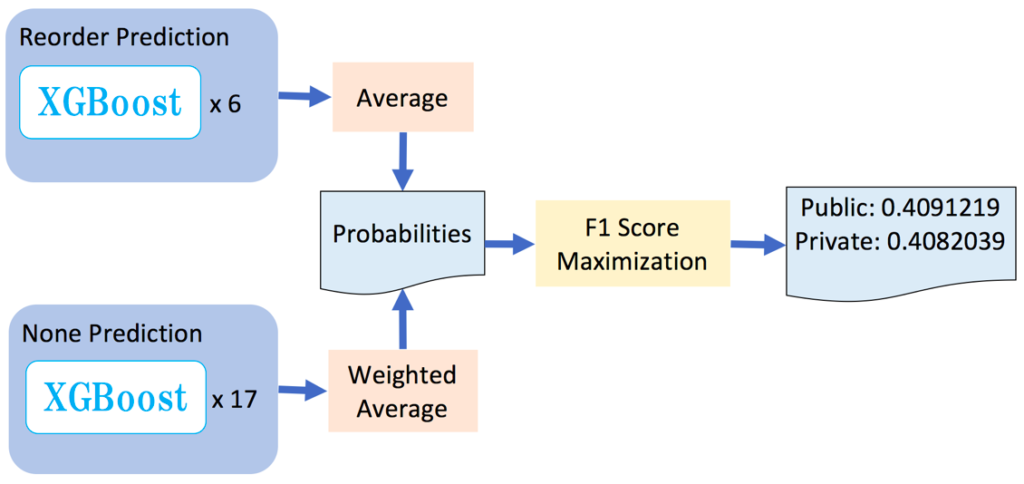
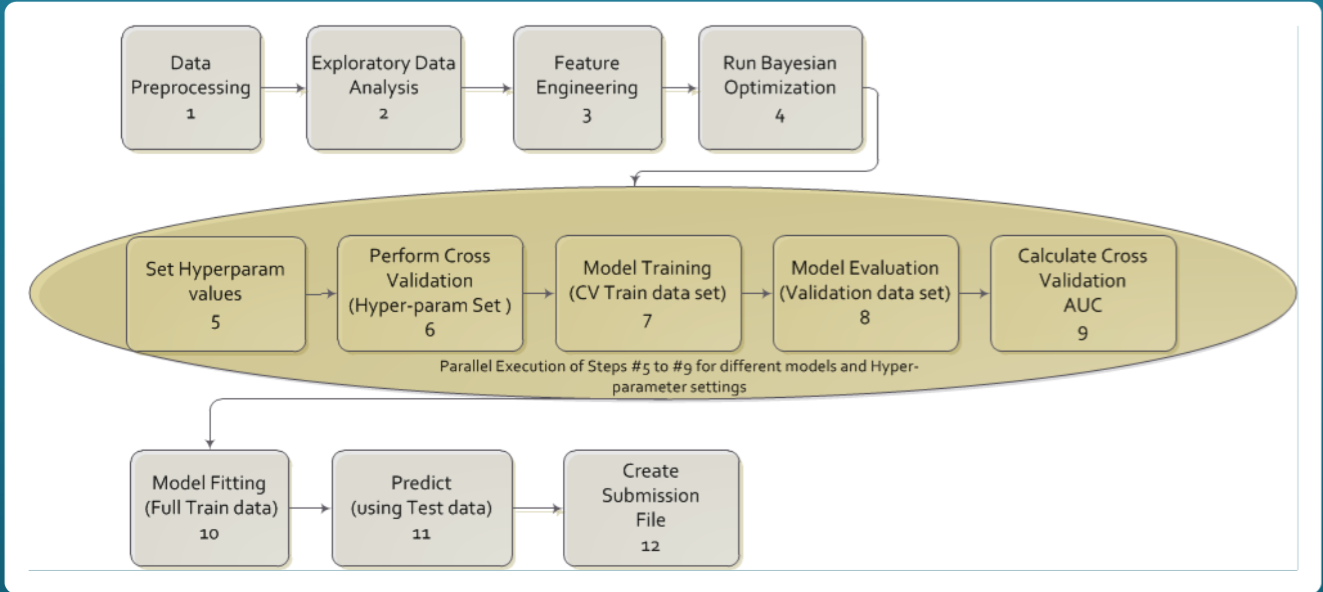
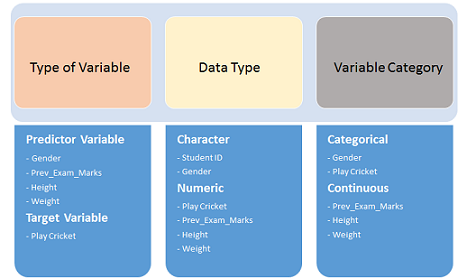
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
import numpy as np
import pandas as pd
import xgboost as xgb
from scipy import sparse
import matplotlib.pyplot as plt
from pylab import plot, show, subplot, specgram, imshow, savefig
import random
import operator
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
print("Started")
RS = 2016
random.seed(RS)
np.random.seed(RS)
input_folder = '../input/'
interest_level = ['high', 'medium', 'low']
n_class = len(interest_level)
interest_level_dict = {w: i for i, w in enumerate(interest_level)}
def train_xgb(X, y, params):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.001, random_state=RS)
xg_train = xgb.DMatrix(X_train, label=y_train)
xg_val = xgb.DMatrix(X_val, label=y_val)
watchlist = [(xg_train, 'train'), (xg_val, 'eval')]
return xgb.train(params, xg_train, params['num_rounds'])
def predict_xgb(clr, X_test):
return clr.predict(xgb.DMatrix(X_test))
def create_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1
outfile.close()
def create_data_preprocess(data):
pass
if __name__ == "__main__":
params = {}
params['objective'] = 'multi:softprob'
params['eval_metric'] = 'mlogloss'
params['num_class'] = n_class
params['eta'] = 0.08
params['max_depth'] = 6
params['subsample'] = 0.7
params['colsample_bytree'] = 0.7
params['silent'] = 1
params['num_rounds'] = 350
params['seed'] = RS
df = create_data_preprocess(data = '')
is_feats = [col for col in df.columns]
print("Features: {}".format(is_feats))
feature_names = is_feats
create_feature_map(feature_names)
X_train = df[:train_len]
X_test = df[train_len:]
print("Training on: X_train: {}, y_train: {}, X_test: {}".format(X_train.shape, y_train.shape, X_test.shape))
clr = train_xgb(X_train, np.array(y_train.astype(np.int8)), params)
preds = predict_xgb(clr, X_test)
print("Submission file done, plotting features importance...")
importance = clr.get_fscore(fmap='xgb.fmap')
importance = sorted(importance.items(), key=operator.itemgetter(1))
df = pd.DataFrame(importance, columns=['feature', 'fscore'])
plt.figure()
df.plot()
df.plot(kind='barh', x='feature', y='fscore', legend=False, figsize=(10, 25))
plt.gcf().savefig('features_importance.png')
|