本文主要是使用python加载预训练的词向量模型,这些模型都是使用大规模的预料训练得到,如word2vec,glove和fasttext。使用预训练的模型可以提高我们的准确性。
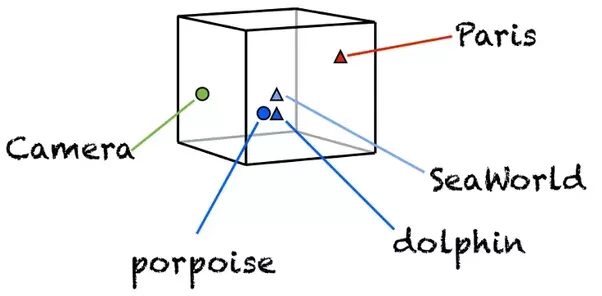
简单看看三者之间的区别
Word2Vec
word2vec的主要思想是在根据每个单词的上下文训练一个模型,因此,类似的单词也会有类似的数字表示。
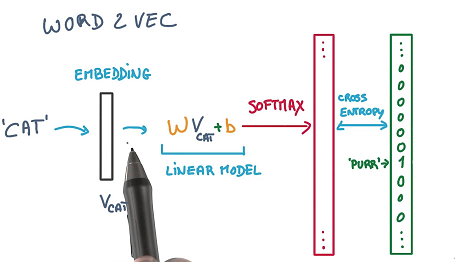
就像一个前馈神经网络(NN),假设你有一组独立的变量和一个你想要预测的目标变量,你首先把你的句子变成单词(tokenize),并根据窗口的大小创建多个词组。所以其中一个组合可以是一对单词,比如(“cat”,“purr”),其中"cat"是独立变量(X),而“purr”是我们想要预测的目标因变量(Y)。
我们通过一个由随机权值初始化的embedding层将“cat”输入到NN中,并将其传递到softmax层,最终目的是预测“purr”。优化方法如SGD将损失函数最小化"(target word | context words)" ,该方法试图将给定上下文单词的目标词的预测损失最小化。如果我们使用足够的epoch的训练,那么embedding层中的权重最终将代表单词向量的词汇,这就是这个几何向量空间中单词的“坐标”。
上面的例子主要是说明skip-gram模型,对于另外一种CBOW模型,给定context则预测一个词。
Golve
glove的工作原理类似于Word2Vec。上述提到Word2Vec是一个“预测”模型,预测给定单词的上下文,Glove通过构造一个共现矩阵(单词X上下文)来学习,共现矩阵主要是计算一个单词在上下文中出现的频率。共现矩阵是一个巨大的矩阵,我们通过分解得到一个更低维的表示。Glove结构包含很多细节。
FastText
FastText与上面的2个embedding非常不同。虽然Word2Vec和Glove把每个单词当作训练的最小单元,FastText使用n-gram字符作为最小的单元。例如,“apple”这个词可以被分解成“ap”、“app”、“ple”等单独的词向量单位。使用FastText的最大好处是,它可以对罕见的单词甚至是在训练中看不到的单词生成更好的词向量,,因为n-gram的字符向量是与其他单词共享的。这是Word2Vec和Glove无法实现的。
python代码实现
数据主要使用kaggle比赛Toxic Comment Classification Challenge 数据
加载模块
1 2 3 4 5 6 7 8 9 import sys,os,re,csv,codecs,numpy as np,pandas as pdfrom keras.preprocessing.text import Tokenizerfrom keras.preprocessing.sequence import pad_sequencesfrom keras.layers import Dense,Input,LSTM,Embeddingfrom keras.layers import Dropout,Activationfrom keras.layers import Bidirectional,GlobalMaxPool1Dfrom keras.models import Modelimport gcimport gensim.models.keyedvectors as word2vec
数据处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 train = pd.read_csv("train.csv" ) test = pd.read_csv("test.csv" ) embed_size = 0 list_classes = ["toxic" , "severe_toxic" , "obscene" , "threat" , "insult" , "identity_hate" ] y = train[list_classes].values list_sentences_train = train['comment_text' ] list_sentences_test = test['comment_text' ] max_features = 20000 tokenizer = Tokenizer(num_words = max_features) tokenizer.fit_on_texts(list (list_sentences_train)) list_tokenized_train = tokenizer.texts_to_sequences(list_sentences_train) list_tokenized_test = tokenizer.texts_to_sequences(list_sentences_test)
其中
Tokenization:将句子转化为唯一的单词组,比如““I love cats and love dogs””,转化为[“I”,“love”,“cats”,“and”,“dogs”]
由上面得到每个评论类似于:
1 2 Comment #1: [8,9,3,7,3,6,3,6,3,6,2,3,4,9] Comment #2: [1,2]
可以看到长度是不一样的,因此我们需要转化为等长列表,即
1 2 3 4 maxlen = 200 X_t = pad_sequences(list_tokenized_train,maxlen = maxlen) X_te = pad_sequences(list_tokenized_test,maxlen = maxlen)
构建词向量
接下来定义一个加载预训练模型功能的函数,这里glove使用的是基于Twitter文本训练的模型,因为比赛数据也是评论数据,一般文本长度很短。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def loadEMbeddingMatrix (typeToLoad ): if typeToLoad == 'glove' : EMBEDDING_FILE = '/model/glove_twitter/glove.twitter.27B.25d.txt' embed_size = 25 elif typeToLoad == 'word2vec' : EMBEDDING_FILE = '/model/googlenewsvectorsnegative300/GoogleNews-vectors-negative300.bin' word2vecDict = word2vec.KeyedVectors.load_word2vec_format(EMBEDDING_FILE,binary=True ) embed_size = 300 elif typeToLoad == 'fasttext' : EMBEDDING_FILE = '/model/fasttext/wiki-news-300d-1M.vec' embed_size = 300 if typeToLoad == 'glove' or typeToLoad == 'fasttext' : embedding_index = dict () f = open (EMBEDDING_FILE) for line in f: values = line.split() word = values[0 ] coefs = np.asarray(values[1 :],dtype='float32' ) embedding_index[word] = coefs f.close() print ('Load %s word vectors.' %len (embedding_index)) else : embedding_index = dict () for word in word2vecDict.wv.vocab: embedding_index[word] = word2vecDict.word_vec(word) print ('Load %s word vectors.' % len (embedding_index)) gc.collect() all_embs = np.stack(list (embedding_index.values())) emb_mean,emb_std = all_embs.mean(),all_embs.std() nb_words = len (tokenizer.word_index) embedding_matrix = np.random.normal(emb_mean,emb_std,(nb_words,embed_size)) gc.collect() embeddedCount = 0 for word,i in tokenizer.word_index.items(): i -= 1 embedding_vector = embedding_index.get(word) if embedding_vector is not None : embedding_matrix[i] = embedding_vector embeddedCount += 1 print ('total_embedded:' ,embeddedCount,'commen words' ) del embedding_index gc.collect() return embedding_matrix
上述函数将输出一个词向量矩阵,如果预训练模型中包含词,则返回该词对应的词向量,若词是新词,则使用随机产生词向量。
比如我们产生word2vec词向量矩阵
1 2 embedding_matrix = loadEmbeddingMatrix('word2vec' ) embedding_matrix.shape
结果:
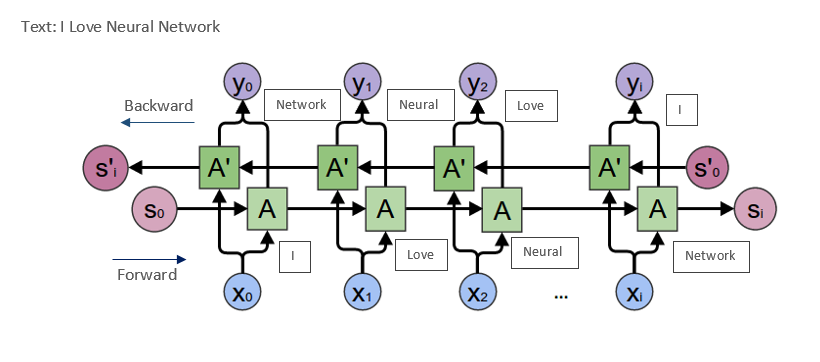
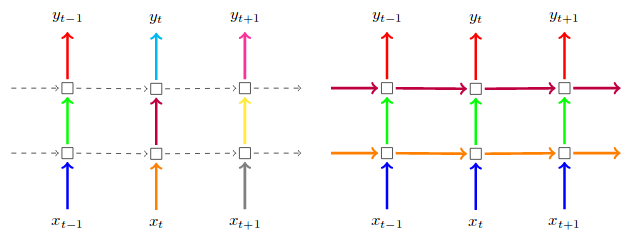
得到词向量矩阵之后,建立一个BiLSTM层,BILSTM结构如下图:
假设LSTM在每个时间步骤中被分成两个隐藏状态。当单词的序列以正向的方式被输入到LSTM中时,又有另一个反向序列在同一时间向不同的隐藏状态输入。稍后您可能会在模型总结中注意到,LSTM层的输出维度增加了一倍,达到120,因为前面使用了60个维度,而另外60个维度用于反向。
使用双向LSTM的最大好处是,当它向后运行时,您可以保存来自未来的信息,并使用两个隐藏的状态组合,您可以在任何时间点保存过去和将来的信息。
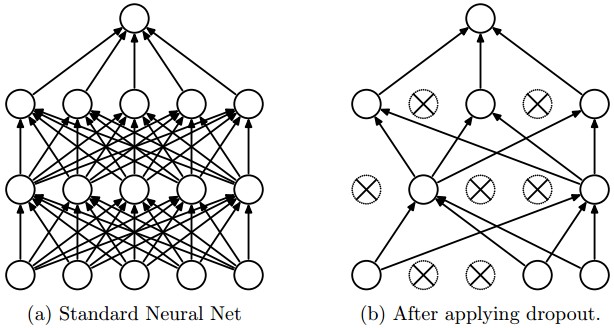
我们还引入两种新的机制:LSTM Drop out 和recurrent drop out。
为什么我们要用drop out?您可能已经注意到,LSTM很容易拟合,dropout并不是什么新鲜事,而这些机制在LSTM的背景下也适用同样的dropout原则。
LSTM dropout是在每一个时间步骤的输入上的概率drop out层,如图所示(箭头指向上方)。另一方面,recurrent drop out就像一个丢失的掩码,它在整个LSTM网络的递归过程中,drop out 掉隐藏的状态,如右边的图中(箭头指向右边)。
这些机制可以分别通过“dropout”和“recurrent_dropout”参数设置。请忽略图片中的颜色。
建立模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def _model (maxlen,embedding_matrix,units ): inp = Input(shape = (maxlen,)) x = Embedding(units,embedding_matrix.shape[1 ],weights = [embedding_matrix], trainable = False )(inp) x = Bidirectional(LSTM(60 ,return_sequences=True ,name = 'lstm_layer' , dropout=0.1 ,recurrent_dropout=0.1 ))(x) x = GlobalMaxPool1D()(x) x = Dropout(0.1 )(x) x = Dense(50 ,activation='relu' )(x) x = Dropout(0.1 )(x) x = Dense(6 ,activation='sigmoid' )(x) model = Model(inputs = inp,outputs = x) model.compile (loss = 'binary_crossentropy' , optimizer = 'adam' , metrics = ['accuracy' ]) return model
1 2 model = _model(units = len (tokenizer.word_index),embedding_matrix=embedding_matrix,maxlen=maxlen) model.summary()
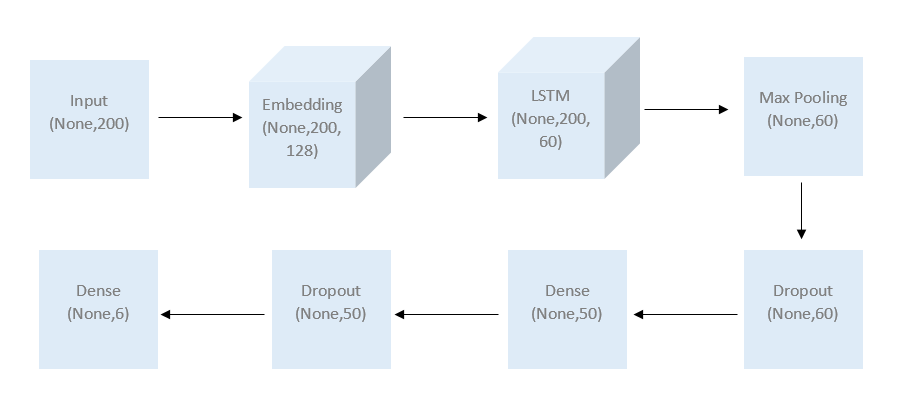
模型结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_5 (InputLayer) (None, 200) 0 _________________________________________________________________ embedding_5 (Embedding) (None, 200, 300) 63101100 _________________________________________________________________ bidirectional_5 (Bidirection (None, 200, 120) 173280 _________________________________________________________________ global_max_pooling1d_5 (Glob (None, 120) 0 _________________________________________________________________ dropout_5 (Dropout) (None, 120) 0 _________________________________________________________________ dense_9 (Dense) (None, 50) 6050 _________________________________________________________________ dropout_6 (Dropout) (None, 50) 0 _________________________________________________________________ dense_10 (Dense) (None, 6) 306 ================================================================= Total params: 63,280,736 Trainable params: 179,636 Non-trainable params: 63,101,100
训练模型
1 2 3 batch_size = 32 epochs = 4 hist = model.fit(X_t,y, batch_size=batch_size, epochs=epochs, validation_split=0.1 )
结果如下:
1 2 3 4 5 Train on 143613 samples, validate on 15958 samples Epoch 1/4 143613/143613 [==============================] - 2938s 20ms/step - loss: 0.0843 - acc: 0.9739 - val_loss: 0.0630 - val_acc: 0.9786 Epoch 2/4 143613/143613 [==============================] - 3332s 23ms/step - loss: 0.0573 - acc: 0.9805 - val_loss: 0.0573 - val_acc: 0.9805 Epoch 3/4 143613/143613 [==============================] - 3119s 22ms/step - loss: 0.0513 - acc: 0.9819 - val_loss: 0.0511 - val_acc: 0.9817 Epoch 4/4 143613/143613 [==============================] - 3137s 22ms/step - loss: 0.0477 - acc: 0.9827 - val_loss: 0.0498 - val_acc: 0.9820
对于glove和fasttext一样,只需将embedding对应修改即可,比如:
1 2 loadEmbeddingMatrix('glove' ) loadEmbeddingMatrix('fasttext' )
上述只是说明怎么使用,结果不一定好。