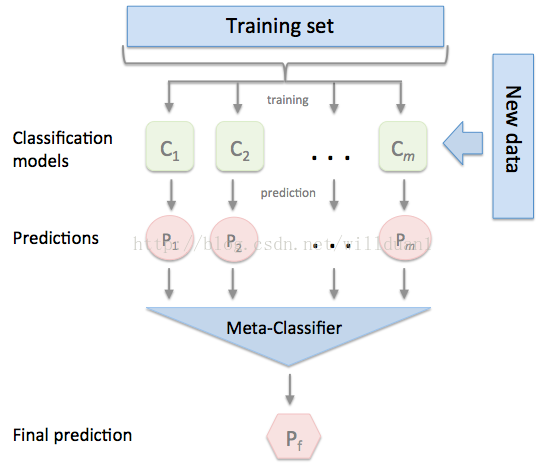
Stacking是一种模型组合技术,用于组合来自多个预测模型的信息,以生成一个新的模型。即将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测.
当然,stacking并不是都能带来惊人的效果,当模型之间存在明显差异时,stacking的效果是相当好的,而当模型都很相似时,带来的效果往往并不是那么亮眼。
实现
直接以kaggle的Porto Seguro’s Safe Driver Prediction 比赛数据为例。
这是Kaggle在9月30日开启的一个新的比赛,举办者是巴西最大的汽车与住房保险公司之一:Porto Seguro。该比赛要求参赛者根据汽车保单持有人的数据建立机器学习模型,分析该持有人是否会在次年提出索赔。比赛所提供的数据均已进行处理,由于数据特征没有实际意义,因此无法根据常识或业界知识简单地进行特征工程。
数据下载地址: Data
加载所需要模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScalerfrom sklearn.metrics import roc_auc_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifierfrom sklearn.naive_bayes import BernoulliNBfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import StratifiedKFoldimport xgboost as xgbimport lightgbm as lgbimport timepd.set_option('display.max_columns' , 500 ) pd.set_option('display.max_colwidth' , 500 ) pd.set_option('display.max_rows' , 1000 )
特征工程
这部分简单的对数据进行处理,主要有:
Categorical feature encoding
Frequency Encoding
Binary Encoding
Feature Reduction
1.1 Frequency Encoding
1 2 3 4 train=pd.read_csv('train.csv' ) test=pd.read_csv('test.csv' ) sample_submission=pd.read_csv('sample_submission.csv' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def freq_encoding (cols, train_df, test_df ): result_train_df=pd.DataFrame() result_test_df=pd.DataFrame() for col in cols: col_freq=col+'_freq' freq=train_df[col].value_counts() freq=pd.DataFrame(freq) freq.reset_index(inplace=True ) freq.columns=[[col,col_freq]] temp_train_df=pd.merge(train_df[[col]], freq, how='left' ,on=col) temp_train_df.drop([col], axis=1 , inplace=True ) temp_test_df=pd.merge(test_df[[col]], freq, how='left' , on=col) temp_test_df.drop([col], axis=1 , inplace=True ) temp_test_df.fillna(0 , inplace=True ) temp_test_df[col_freq]=temp_test_df[col_freq].astype(np.int32) if result_train_df.shape[0 ]==0 : result_train_df=temp_train_df result_test_df=temp_test_df else : result_train_df=pd.concat([result_train_df, temp_train_df],axis=1 ) result_test_df=pd.concat([result_test_df, temp_test_df],axis=1 ) return result_train_df, result_test_df cat_cols=['ps_ind_02_cat' ,'ps_car_04_cat' , 'ps_car_09_cat' , 'ps_ind_05_cat' , 'ps_car_01_cat' , 'ps_car_11_cat' ] train_freq, test_freq=freq_encoding(cat_cols, train, test) train=pd.concat([train, train_freq], axis=1 ) test=pd.concat([test,test_freq], axis=1 )
1.2.Binary Encoding
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def binary_encoding (train_df, test_df, feat ): train_feat_max = train_df[feat].max () test_feat_max = test_df[feat].max () if train_feat_max > test_feat_max: feat_max = train_feat_max else : feat_max = test_feat_max train_df.loc[train_df[feat] == -1 , feat] = feat_max + 1 test_df.loc[test_df[feat] == -1 , feat] = feat_max + 1 union_val = np.union1d(train_df[feat].unique(), test_df[feat].unique()) max_dec = union_val.max () max_bin_len = len ("{0:b}" .format (max_dec)) index = np.arange(len (union_val)) columns = list ([feat]) bin_df = pd.DataFrame(index=index, columns=columns) bin_df[feat] = union_val feat_bin = bin_df[feat].apply(lambda x: "{0:b}" .format (x).zfill(max_bin_len)) splitted = feat_bin.apply(lambda x: pd.Series(list (x)).astype(np.uint8)) splitted.columns = [feat + '_bin_' + str (x) for x in splitted.columns] bin_df = bin_df.join(splitted) train_df = pd.merge(train_df, bin_df, how='left' , on=[feat]) test_df = pd.merge(test_df, bin_df, how='left' , on=[feat]) return train_df, test_df cat_cols=['ps_ind_02_cat' ,'ps_car_04_cat' , 'ps_car_09_cat' , 'ps_ind_05_cat' , 'ps_car_01_cat' ] train, test=binary_encoding(train, test, 'ps_ind_02_cat' ) train, test=binary_encoding(train, test, 'ps_car_04_cat' ) train, test=binary_encoding(train, test, 'ps_car_09_cat' ) train, test=binary_encoding(train, test, 'ps_ind_05_cat' ) train, test=binary_encoding(train, test, 'ps_car_01_cat' )
1.3 Feature Reduction
是否删除原始数据,可以参考删除之前跟删除之后的cv结果
1 2 3 col_to_drop = train.columns[train.columns.str .startswith('ps_calc_' )] train.drop(col_to_drop, axis=1 , inplace=True ) test.drop(col_to_drop, axis=1 , inplace=True )
交叉验证—oof特征
注 :模型的参数已经经过调整好了,所以在增加oof特征之前需要对模型进行调参处理
1 2 def auc_to_gini_norm (auc_score ): return 2 *auc_score-1
Sklearn K-fold & OOF function
主要针对python模块sklearn中的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 def cross_validate_sklearn (clf, x_train, y_train , x_test, kf,scale=False , verbose=True ): ''' :param clf: 模型 :param x_train: 训练数据 :param y_train: 训练数据 :param x_test: 测试数据 :param kf: cv数 :param scale: 是否归一化 :param verbose: :return: ''' start_time=time.time() train_pred = np.zeros((x_train.shape[0 ])) test_pred = np.zeros((x_test.shape[0 ])) for i, (train_index, val_index) in enumerate (kf.split(x_train, y_train)): x_train_kf, x_val_kf = x_train.loc[train_index, :], x_train.loc[val_index, :] y_train_kf, y_val_kf = y_train[train_index], y_train[val_index] if scale: scaler = StandardScaler().fit(x_train_kf.values) x_train_kf_values = scaler.transform(x_train_kf.values) x_val_kf_values = scaler.transform(x_val_kf.values) x_test_values = scaler.transform(x_test.values) else : x_train_kf_values = x_train_kf.values x_val_kf_values = x_val_kf.values x_test_values = x_test.values clf.fit(x_train_kf_values, y_train_kf.values) val_pred=clf.predict_proba(x_val_kf_values)[:,1 ] train_pred[test_index] += val_pred y_test_preds = clf.predict_proba(x_test_values)[:,1 ] test_pred += y_test_preds fold_auc = roc_auc_score(y_val_kf.values, val_pred) fold_gini_norm = auc_to_gini_norm(fold_auc) if verbose: print ('fold cv {} AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (i, fold_auc, fold_gini_norm)) test_pred /= kf.n_splits cv_auc = roc_auc_score(y_train, train_pred) cv_gini_norm = auc_to_gini_norm(cv_auc) cv_score = [cv_auc, cv_gini_norm] if verbose: print ('cv AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (cv_auc, cv_gini_norm)) end_time = time.time() print ("it takes %.3f seconds to perform cross validation" % (end_time - start_time)) return cv_score, train_pred,test_pred
Xgboost K-fold & OOF function
接下来针对kaggle比赛杀器xgboost和lightgbm进行构造oof特征,主要使用原生的xgboost或lightgbm模块,当然你也可以使用sklearn的api,但是原生的模块会包含更多的功能。
1 2 3 4 5 6 def probability_to_rank (prediction, scaler=1 ): pred_df=pd.DataFrame(columns=['probability' ]) pred_df['probability' ]=prediction pred_df['rank' ]=pred_df['probability' ].rank()/len (prediction)*scaler return pred_df['rank' ].values
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 def cross_validate_xgb (params, x_train, y_train, x_test, kf, cat_cols=[], verbose=True , verbose_eval=50 , num_boost_round=4000 , use_rank=True ): ''' :param params: 模型参数 :param x_train: 训练数据 :param y_train: 训练数据 :param x_test: 测试数据 :param kf: cv数 :param cat_cols:类别特征 :param verbose: :param verbose_eval: :param num_boost_round:迭代数 :param use_rank: 是否排序结果 :return: ''' start_time=time.time() train_pred = np.zeros((x_train.shape[0 ])) test_pred = np.zeros((x_test.shape[0 ])) for i, (train_index, val_index) in enumerate (kf.split(x_train, y_train)): x_train_kf, x_val_kf = x_train.loc[train_index, :], x_train.loc[val_index, :] y_train_kf, y_val_kf = y_train[train_index], y_train[val_index] x_test_kf=x_test.copy() d_train_kf = xgb.DMatrix(x_train_kf, label=y_train_kf) d_val_kf = xgb.DMatrix(x_val_kf, label=y_val_kf) d_test = xgb.DMatrix(x_test_kf) bst = xgb.train(params, d_train_kf, num_boost_round=num_boost_round, evals=[(d_train_kf, 'train' ), (d_val_kf, 'val' )], verbose_eval=verbose_eval, early_stopping_rounds=50 ) val_pred = bst.predict(d_val_kf, ntree_limit=bst.best_ntree_limit) if use_rank: train_pred[val_index] += probability_to_rank(val_pred) test_pred+=probability_to_rank(bst.predict(d_test)) else : train_pred[val_index] += val_pred test_pred+=bst.predict(d_test) fold_auc = roc_auc_score(y_val_kf.values, val_pred) fold_gini_norm = auc_to_gini_norm(fold_auc) if verbose: print ('fold cv {} AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (i, fold_auc, fold_gini_norm)) test_pred /= kf.n_splits cv_auc = roc_auc_score(y_train, train_pred) cv_gini_norm = auc_to_gini_norm(cv_auc) cv_score = [cv_auc, cv_gini_norm] if verbose: print ('cv AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (cv_auc, cv_gini_norm)) end_time = time.time() print ("it takes %.3f seconds to perform cross validation" % (end_time - start_time)) return cv_score, train_pred,test_pred
LigthGBM K-fold & OOF function
类似于xgboost
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 def cross_validate_lgb (params, x_train, y_train, x_test, kf, cat_cols=[], verbose=True , verbose_eval=50 , use_cat=True , use_rank=True ): ''' :param params: 模型参数 :param x_train: 训练数据 :param y_train: 训练数据 :param x_test: 测试数据 :param kf: cv数 :param cat_cols: :param verbose: :param verbose_eval: :param use_cat: :param use_rank: :return: ''' start_time = time.time() train_pred = np.zeros((x_train.shape[0 ])) test_pred = np.zeros((x_test.shape[0 ])) if len (cat_cols)==0 : use_cat=False for i, (train_index, val_index) in enumerate (kf.split(x_train, y_train)): x_train_kf, x_val_kf = x_train.loc[train_index, :], x_train.loc[val_index, :] y_train_kf, y_val_kf = y_train[train_index], y_train[val_index] if use_cat: lgb_train = lgb.Dataset(x_train_kf, y_train_kf, categorical_feature=cat_cols) lgb_val = lgb.Dataset(x_val_kf, y_val_kf, reference=lgb_train, categorical_feature=cat_cols) else : lgb_train = lgb.Dataset(x_train_kf, y_train_kf) lgb_val = lgb.Dataset(x_val_kf, y_val_kf, reference=lgb_train) gbm = lgb.train(params, lgb_train, num_boost_round=4000 , valid_sets=lgb_val, early_stopping_rounds=30 , verbose_eval=verbose_eval) val_pred = gbm.predict(x_val_kf) if use_rank: train_pred[val_index] += probability_to_rank(val_pred) test_pred += probability_to_rank(gbm.predict(x_test)) else : train_pred[val_index] += val_pred test_pred += gbm.predict(x_test) fold_auc = roc_auc_score(y_val_kf.values, val_pred) fold_gini_norm = auc_to_gini_norm(fold_auc) if verbose: print ('fold cv {} AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (i, fold_auc, fold_gini_norm)) test_pred /= kf.n_splits cv_auc = roc_auc_score(y_train, train_pred) cv_gini_norm = auc_to_gini_norm(cv_auc) cv_score = [cv_auc, cv_gini_norm] if verbose: print ('cv AUC score is {:.6f}, Gini_Norm score is {:.6f}' .format (cv_auc, cv_gini_norm)) end_time = time.time() print ("it takes %.3f seconds to perform cross validation" % (end_time - start_time)) return cv_score, train_pred,test_pred
Generate level 1 OOF predictions
有了前面定义好的oof特征函数,接下来,将构造不同level oof的输出。首先定义好数据和cv数
1 2 3 4 5 drop_cols=['id' ,'target' ] y_train=train['target' ] x_train=train.drop(drop_cols, axis=1 ) x_test=test.drop(['id' ], axis=1 ) kf=StratifiedKFold(n_splits=5 , shuffle=True , random_state=2017 )
下面,将使用一些常见的模型产生level 1 model输出:
Random Forest
1 2 3 4 5 6 7 8 rf=RandomForestClassifier(n_estimators=200 , n_jobs=6 , min_samples_split=5 , max_depth=7 , criterion='gini' , random_state=0 ) outcomes =cross_validate_sklearn(rf, x_train, y_train ,x_test, kf, scale=False , verbose=True ) rf_cv=outcomes[0 ] rf_train_pred=outcomes[1 ] rf_test_pred=outcomes[2 ] rf_train_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=rf_train_pred) rf_test_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=rf_test_pred)
Logistic Regression
1 2 3 4 5 6 7 logit=LogisticRegression(random_state=0 , C=0.5 ) outcomes = cross_validate_sklearn(logit, x_train, y_train ,x_test, kf, scale=True , verbose=True ) logit_cv=outcomes[0 ] logit_train_pred=outcomes[1 ] logit_test_pred=outcomes[2 ] logit_train_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=logit_train_pred) logit_test_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=logit_test_pred)
BernoulliNB
这种算法通常单个模型输出结果性能比不上xgb或lgb的结果,不过,它能带来结果的多样性,有助于提高stacking的性能。
1 2 3 4 5 6 7 nb=BernoulliNB() outcomes =cross_validate_sklearn(nb, x_train, y_train ,x_test, kf, scale=True , verbose=True ) nb_cv=outcomes[0 ] nb_train_pred=outcomes[1 ] nb_test_pred=outcomes[2 ] nb_train_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=nb_train_pred) nb_test_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=nb_test_pred)
xgboost
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 xgb_params = { "booster" : "gbtree" , "objective" : "binary:logistic" , "tree_method" : "hist" , "eval_metric" : "auc" , "eta" : 0.1 , "max_depth" : 5 , "min_child_weight" : 10 , "gamma" : 0.70 , "subsample" : 0.76 , "colsample_bytree" : 0.95 , "nthread" : 6 , "seed" : 0 , 'silent' : 1 } outcomes=cross_validate_xgb(xgb_params, x_train, y_train, x_test, kf, use_rank=False , verbose_eval=False ) xgb_cv=outcomes[0 ] xgb_train_pred=outcomes[1 ] xgb_test_pred=outcomes[2 ] xgb_train_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=xgb_train_pred) xgb_test_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=xgb_test_pred)
lightGBM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 lgb_params = { 'task' : 'train' , 'boosting_type' : 'dart' , 'objective' : 'binary' , 'metric' : {'auc' }, 'num_leaves' : 22 , 'min_sum_hessian_in_leaf' : 20 , 'max_depth' : 5 , 'learning_rate' : 0.1 , 'num_threads' : 6 , 'feature_fraction' : 0.6894 , 'bagging_fraction' : 0.4218 , 'max_drop' : 5 , 'drop_rate' : 0.0123 , 'min_data_in_leaf' : 10 , 'bagging_freq' : 1 , 'lambda_l1' : 1 , 'lambda_l2' : 0.01 , 'verbose' : 1 } cat_cols=['ps_ind_02_cat' ,'ps_car_04_cat' , 'ps_car_09_cat' ,'ps_ind_05_cat' , 'ps_car_01_cat' ] outcomes=cross_validate_lgb(lgb_params,x_train, y_train ,x_test,kf, cat_cols, use_cat=True , verbose_eval=False , use_rank=False ) lgb_cv=outcomes[0 ] lgb_train_pred=outcomes[1 ] lgb_test_pred=outcomes[2 ] lgb_train_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=lgb_train_pred) lgb_test_pred_df=pd.DataFrame(columns=['prediction_probability' ], data=lgb_test_pred)
我们已经产生了level 1的特征,接下来进行level 2的ensemble
Level 2 ensemble
Generate L1 output dataframe
将level 1的oof特征作为level 2 的输入特征
1 2 3 4 5 6 7 8 9 10 columns=['rf' ,'et' ,'logit' ,'nb' ,'xgb' ,'lgb' ] train_pred_df_list=[rf_train_pred_df, et_train_pred_df, logit_train_pred_df, nb_train_pred_df, xgb_train_pred_df, lgb_train_pred_df] test_pred_df_list=[rf_test_pred_df, et_test_pred_df, logit_test_pred_df, nb_test_pred_df,xgb_test_pred_df, lgb_test_pred_df] lv1_train_df=pd.DataFrame(columns=columns) lv1_test_df=pd.DataFrame(columns=columns) for i in range (0 ,len (columns)): lv1_train_df[columns[i]]=train_pred_df_list[i]['prediction_probability' ] lv1_test_df[columns[i]]=test_pred_df_list[i]['prediction_probability' ]
Level 2 XGB
对level 1 的oof特征训练xgboost模型,并输出level 2 oof特征
1 2 3 4 5 xgb_lv2_outcomes=cross_validate_xgb(xgb_params, lv1_train_df, y_train, lv1_test_df, kf, verbose=True , verbose_eval=False , use_rank=False ) xgb_lv2_cv=xgb_lv2_outcomes[0 ] xgb_lv2_train_pred=xgb_lv2_outcomes[1 ] xgb_lv2_test_pred=xgb_lv2_outcomes[2 ]
Level 2 LightGBM
1 2 3 4 5 lgb_lv2_outcomes=cross_validate_lgb(lgb_params,lv1_train_df, y_train ,lv1_test_df,kf, [], use_cat=False , verbose_eval=False , use_rank=True ) lgb_lv2_cv=xgb_lv2_outcomes[0 ] lgb_lv2_train_pred=lgb_lv2_outcomes[1 ] lgb_lv2_test_pred=lgb_lv2_outcomes[2 ]
Level 2 Random Forest
1 2 3 4 5 6 7 rf_lv2=RandomForestClassifier(n_estimators=200 , n_jobs=6 , min_samples_split=5 , max_depth=7 , criterion='gini' , random_state=0 ) rf_lv2_outcomes = cross_validate_sklearn(rf_lv2, lv1_train_df, y_train ,lv1_test_df, kf, scale=True , verbose=True ) rf_lv2_cv=rf_lv2_outcomes[0 ] rf_lv2_train_pred=rf_lv2_outcomes[1 ] rf_lv2_test_pred=rf_lv2_outcomes[2 ]
Level 2 Logistic Regression
1 2 3 4 5 6 logit_lv2=LogisticRegression(random_state=0 , C=0.5 ) logit_lv2_outcomes = cross_validate_sklearn(logit_lv2, lv1_train_df, y_train ,lv1_test_df, kf, scale=True , verbose=True ) logit_lv2_cv=logit_lv2_outcomes[0 ] logit_lv2_train_pred=logit_lv2_outcomes[1 ] logit_lv2_test_pred=logit_lv2_outcomes[2 ]
Level 3 ensemble
类似于level 2 的ensemble,当然也可以加入level 1的oof特征
Generate L2 output dataframe
1 2 3 4 5 6 7 8 lv2_columns=['rf_lf2' , 'logit_lv2' , 'xgb_lv2' ,'lgb_lv2' ] train_lv2_pred_list=[rf_lv2_train_pred, logit_lv2_train_pred, xgb_lv2_train_pred, lgb_lv2_train_pred] test_lv2_pred_list=[rf_lv2_test_pred, logit_lv2_test_pred, xgb_lv2_test_pred, lgb_lv2_test_pred] lv2_train=pd.DataFrame(columns=lv2_columns) lv2_test=pd.DataFrame(columns=lv2_columns) for i in range (0 ,len (lv2_columns)): lv2_train[lv2_columns[i]]=train_lv2_pred_list[i] lv2_test[lv2_columns[i]]=test_lv2_pred_list[i]
Level 3 XGB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 xgb_lv3_params = { "booster" : "gbtree" , "objective" : "binary:logistic" , "tree_method" : "hist" , "eval_metric" : "auc" , "eta" : 0.1 , "max_depth" : 2 , "min_child_weight" : 10 , "gamma" : 0.70 , "subsample" : 0.76 , "colsample_bytree" : 0.95 , "nthread" : 6 , "seed" : 0 , 'silent' : 1 } xgb_lv3_outcomes=cross_validate_xgb(xgb_lv3_params, lv2_train, y_train, lv2_test, kf, verbose=True , verbose_eval=False , use_rank=True ) xgb_lv3_cv=xgb_lv3_outcomes[0 ] xgb_lv3_train_pred=xgb_lv3_outcomes[1 ] xgb_lv3_test_pred=xgb_lv3_outcomes[2 ]
Level 3 Logistic Regression
1 2 3 4 5 6 logit_lv3=LogisticRegression(random_state=0 , C=0.5 ) logit_lv3_outcomes = cross_validate_sklearn(logit_lv3, lv2_train, y_train ,lv2_test, kf, scale=True , verbose=True ) logit_lv3_cv=logit_lv3_outcomes[0 ] logit_lv3_train_pred=logit_lv3_outcomes[1 ] logit_lv3_test_pred=logit_lv3_outcomes[2 ]
Average L3 outputs & Submission Generation
1 2 3 4 5 6 7 weight_avg=logit_lv3_train_pred*0.5 + xgb_lv3_train_pred*0.5 print (auc_to_gini_norm(roc_auc_score(y_train, weight_avg)))submission=sample_submission.copy() submission['target' ]=logit_lv3_test_pred*0.5 + xgb_lv3_test_pred*0.5 filename='stacking_demonstration.csv.gz' submission.to_csv(filename,compression='gzip' , index=False )
结语
上述的3层stacking也许不是最好的,但是可以引导你发现更多有用的信息,对于stacking level 是不是越高越好呢?? 一般而言,大部分都只使用到level 2 或者level 3。而我自己一般的策略是:
一般只到level 2,然后平均level 2 的结果
更新—增加模型ensemble权重函数
这里训练的ensemble的权重一般是最后几个模型进行线性融合的权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 ''' 主要是优化最后线性融合模型时候的权重 ''' import pandas as pdimport numpy as npfrom scipy.optimize import minimize from sklearn.cross_validation import StratifiedShuffleSplitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import log_lossimport osos.system("ls ../input" ) train = pd.read_csv("../input/train.csv" ) print ("Training set has {0[0]} rows and {0[1]} columns" .format (train.shape))labels = train['target' ] train.drop(['target' , 'id' ], axis=1 , inplace=True ) print (train.head())sss = StratifiedShuffleSplit(labels, test_size=0.05 , random_state=1234 ) for train_index, test_index in sss: break train_x, train_y = train.values[train_index], labels.values[train_index] test_x, test_y = train.values[test_index], labels.values[test_index] clfs = [] rfc = RandomForestClassifier(n_estimators=50 , random_state=4141 , n_jobs=-1 ) rfc.fit(train_x, train_y) print ('RFC LogLoss {score}' .format (score=log_loss(test_y, rfc.predict_proba(test_x))))clfs.append(rfc) logreg = LogisticRegression() logreg.fit(train_x, train_y) print ('LogisticRegression LogLoss {score}' .format (score=log_loss(test_y, logreg.predict_proba(test_x))))clfs.append(logreg) rfc2 = RandomForestClassifier(n_estimators=50 , random_state=1337 , n_jobs=-1 ) rfc2.fit(train_x, train_y) print ('RFC2 LogLoss {score}' .format (score=log_loss(test_y, rfc2.predict_proba(test_x))))clfs.append(rfc2) predictions = [] for clf in clfs: predictions.append(clf.predict_proba(test_x)) def log_loss_func (weights ): ''' scipy minimize will pass the weights as a numpy array ''' final_prediction = 0 for weight, prediction in zip (weights, predictions): final_prediction += weight * prediction print (test_y, final_prediction) return log_loss(test_y, final_prediction) starting_values = [0.5 ] * len (predictions) cons = ({'type' : 'eq' , 'fun' : lambda w: 1 - sum (w)}) bounds = [(0 , 1 )] * len (predictions) res = minimize(log_loss_func, starting_values, method='SLSQP' , bounds=bounds, constraints=cons) print ('Ensamble Score: {best_score}' .format (best_score=res['fun' ]))print ('Best Weights: {weights}' .format (weights=res['x' ]))