Snapshot Ensembles(Huang et al,2017)是最近提出的一种聪明的技术,该方法训练一个单一的模型,使用cosine annealing learning rate schedule方法,首先使用一个较大学习率并快速收敛到一个局部最小值。然后保存模型参数,接着重新使用一个较大的学习率开始进行优化,然后重复这些步骤M次。最后,所有保存的模型Snapshot都是整体的。
摘要
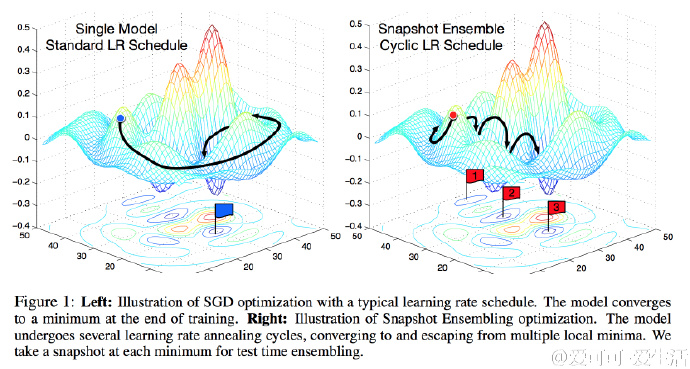
众所周知,使用多个深度网络模型进行融合比单个深度网络模型更加准确和稳健,但是,独立训练多个深度网络,会存在巨大的工程量以及需要大量的时间问题. 论文作者通过训练一个神经网络来得到近似融合的效果,沿着优化路径收敛到几个局部最小值并保存模型参数.为了快速收敛,作者使用了cyclic learning rate schedules ,既简单又高效.在CIFAR-10,CIFAR-100和SVHN上都取得了最好的结果。图1很直观的展示了作者的思路.
Snapshot Ensembles
我们知道如果单个模型之间有较低的test error又保持多样性,则进行融合会得到更好的结果。在单次训练中,Snapshot Ensembles 会产生一组准确又多样的模型,Snapshot Ensembles的核心是在收敛到最后一个解之前,会沿着优化过程保存几个局部最小值解,而在预测阶段,取多个模型的平均预测作为最后的预测答案。
Cyclic Cosine Annealing
为了收敛到多个局部最小值,作者使用了Loshchilov & Hutter(2016)提到的cyclic annealing schedule(简单来说就是消耗训练一个模型的时间,得到多个模型)
- 首先以非常快的速度降低学习率,使得模型快速地收敛到一个局部最小值(小于50 epoch).
- 接着使用较大的学习率进行优化,使得模型能够跳出上一次的最小值
- 不断地重复M次上面两步
论文中,学习率变化:
其中t表示当前迭代,T表示模型总的迭代次数,f是一个单调递减函数,简单来说就是整个训练过程分成M次,每次都是从大的学习率开始,然后快速降低到一个小的学习率,在论文中,作者对f使用了shifted cosine function.
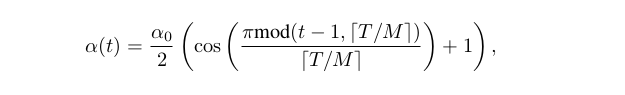
实验
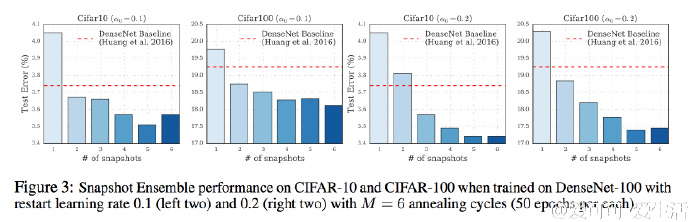
作者在CIFAR-10,CIFAR-100和SVHN上都取得了最好的结果:

Ensemble Size
对于Ensemble Size值M,从论文中可以看到不是越大越好,下图是DenseNet-40在CIFAR-100上的结果

大多数情况下,融合两个模型效果会好于基线模型.
Restart Learning Rate
对于大多数情况下,重置一个较大的学习率会比较小的学习率得到的效果更好.
源码
使用keras实现,具体详见
源码地址: https://github.com/lonePatient/keras_learning/tree/master/Snapshot_Ensembles






